 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Sentence Encoders: Separating Language Specialization from Cross-Lingual Alignment
Paper and Code
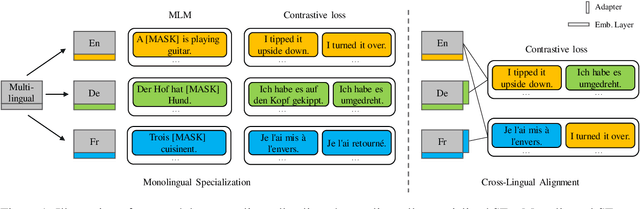
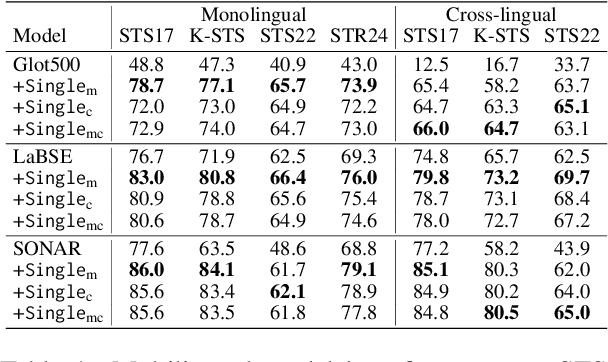

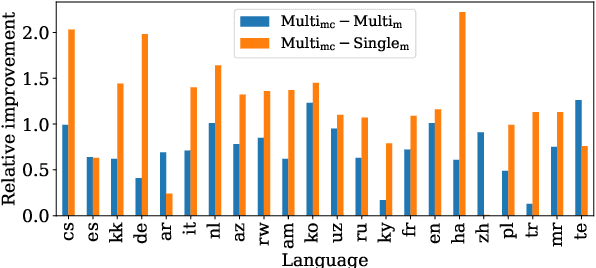
Multilingual sentence encoders are commonly obtained by training multilingual language models to map sentences from different languages into a shared semantic space. As such, they are subject to curse of multilinguality, a loss of monolingual representational accuracy due to parameter sharing. Another limitation of multilingual sentence encoders is the trade-off between monolingual and cross-lingual performance. Training for cross-lingual alignment of sentence embeddings distorts the optimal monolingual structure of semantic spaces of individual languages, harming the utility of sentence embeddings in monolingual tasks. In this work, we address both issues by modular training of sentence encoders, i.e., by separating monolingual specialization from cross-lingual alignment. We first efficiently train language-specific sentence encoders to avoid negative interference between languages (i.e., the curse). We then align all non-English monolingual encoders to the English encoder by training a cross-lingual alignment adapter on top of each, preventing interference with monolingual specialization from the first step. In both steps, we resort to contrastive learning on machine-translated paraphrase data. Monolingual and cross-lingual evaluations on semantic text similarity/relatedness and multiple-choice QA render our modular solution more effective than multilingual sentence encoders, especially benefiting low-resource languages.