 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperator Learning for Surrogate Modeling of Wave-Induced Forces from Sea Surface Waves
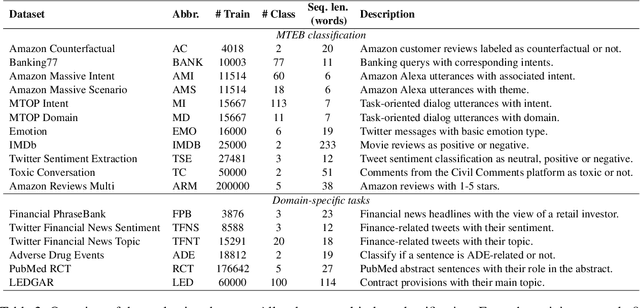
Apr 07, 2026Wave setup plays a significant role in transferring wave-induced energy to currents and causing an increase in water elevation. This excess momentum flux, known as radiation stress, motivates the coupling of circulation models with wave models to improve the accuracy of storm surge prediction, however, traditional numerical wave models are complex and computationally expensive. As a result, in practical coupled simulations, wave models are often executed at much coarser temporal resolution than circulation models. In this work, we explore the use of Deep Operator Networks (DeepONets) as a surrogate for the Simulating WAves Nearshore (SWAN) numerical wave model. The proposed surrogate model was tested on three distinct 1-D and 2-D steady-state numerical examples with variable boundary wave conditions and wind fields. When applied to a realistic numerical example of steady state wave simulation in Duck, NC, the model achieved consistently high accuracy in predicting the components of the radiation stress gradient and the significant wave height across representative scenarios.
ColBERT-Att: Late-Interaction Meets Attention for Enhanced Retrieval
Mar 26, 2026Vector embeddings from pre-trained language models form a core component in Neural Information Retrieval systems across a multitude of knowledge extraction tasks. The paradigm of late interaction, introduced in ColBERT, demonstrates high accuracy along with runtime efficiency. However, the current formulation fails to take into account the attention weights of query and document terms, which intuitively capture the "importance" of similarities between them, that might lead to a better understanding of relevance between the queries and documents. This work proposes ColBERT-Att, to explicitly integrate attention mechanism into the late interaction framework for enhanced retrieval performance. Empirical evaluation of ColBERT-Att depicts improvements in recall accuracy on MS-MARCO as well as on a wide range of BEIR and LoTTE benchmark datasets.
DROID: Dual Representation for Out-of-Scope Intent Detection
Oct 15, 2025Detecting out-of-scope (OOS) user utterances remains a key challenge in task-oriented dialogue systems and, more broadly, in open-set intent recognition. Existing approaches often depend on strong distributional assumptions or auxiliary calibration modules. We present DROID (Dual Representation for Out-of-Scope Intent Detection), a compact end-to-end framework that combines two complementary encoders -- the Universal Sentence Encoder (USE) for broad semantic generalization and a domain-adapted Transformer-based Denoising Autoencoder (TSDAE) for domain-specific contextual distinctions. Their fused representations are processed by a lightweight branched classifier with a single calibrated threshold that separates in-domain and OOS intents without post-hoc scoring. To enhance boundary learning under limited supervision, DROID incorporates both synthetic and open-domain outlier augmentation. Despite using only 1.5M trainable parameters, DROID consistently outperforms recent state-of-the-art baselines across multiple intent benchmarks, achieving macro-F1 improvements of 6--15% for known and 8--20% for OOS intents, with the most significant gains in low-resource settings. These results demonstrate that dual-encoder representations with simple calibration can yield robust, scalable, and reliable OOS detection for neural dialogue systems.
A Neural Operator-Based Emulator for Regional Shallow Water Dynamics
Feb 20, 2025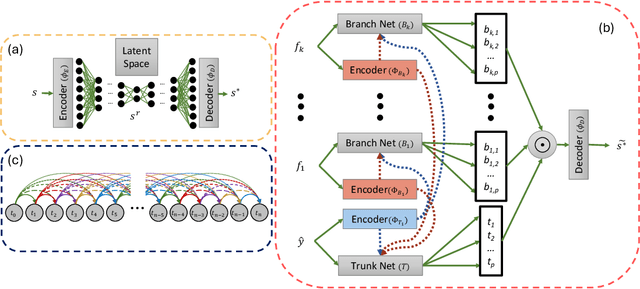

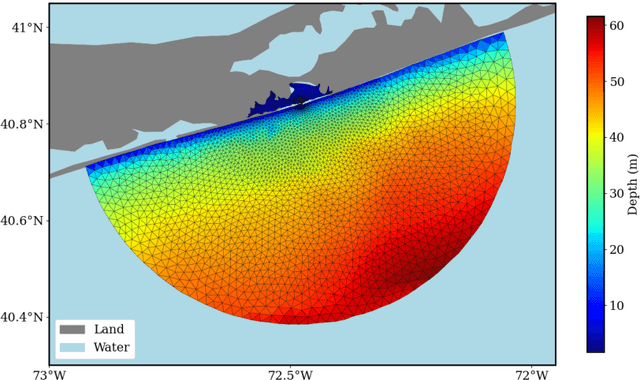
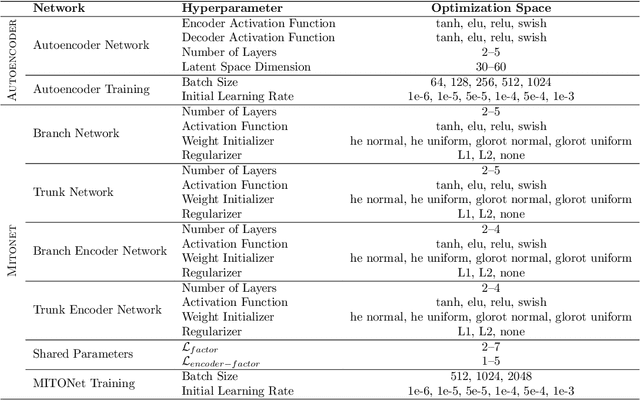
Coastal regions are particularly vulnerable to the impacts of rising sea levels and extreme weather events. Accurate real-time forecasting of hydrodynamic processes in these areas is essential for infrastructure planning and climate adaptation. In this study, we present the Multiple-Input Temporal Operator Network (MITONet), a novel autoregressive neural emulator that employs dimensionality reduction to efficiently approximate high-dimensional numerical solvers for complex, nonlinear problems that are governed by time-dependent, parameterized partial differential equations. Although MITONet is applicable to a wide range of problems, we showcase its capabilities by forecasting regional tide-driven dynamics described by the two-dimensional shallow-water equations, while incorporating initial conditions, boundary conditions, and a varying domain parameter. We demonstrate MITONet's performance in a real-world application, highlighting its ability to make accurate predictions by extrapolating both in time and parametric space.
Improved Out-of-Scope Intent Classification with Dual Encoding and Threshold-based Re-Classification
May 31, 2024



Detecting out-of-scope user utterances is essential for task-oriented dialogues and intent classification. Current methodologies face difficulties with the unpredictable distribution of outliers and often rely on assumptions about data distributions. We present the Dual Encoder for Threshold-Based Re-Classification (DETER) to address these challenges. This end-to-end framework efficiently detects out-of-scope intents without requiring assumptions on data distributions or additional post-processing steps. The core of DETER utilizes dual text encoders, the Universal Sentence Encoder (USE) and the Transformer-based Denoising AutoEncoder (TSDAE), to generate user utterance embeddings, which are classified through a branched neural architecture. Further, DETER generates synthetic outliers using self-supervision and incorporates out-of-scope phrases from open-domain datasets. This approach ensures a comprehensive training set for out-of-scope detection. Additionally, a threshold-based re-classification mechanism refines the model's initial predictions. Evaluations on the CLINC-150, Stackoverflow, and Banking77 datasets demonstrate DETER's efficacy. Our model outperforms previous benchmarks, increasing up to 13% and 5% in F1 score for known and unknown intents on CLINC-150 and Stackoverflow, and 16% for known and 24% % for unknown intents on Banking77. The source code has been released at https://github.com/Hossam-Mohammed-tech/Intent_Classification_OOS.
AdaSent: Efficient Domain-Adapted Sentence Embeddings for Few-Shot Classification
Nov 01, 2023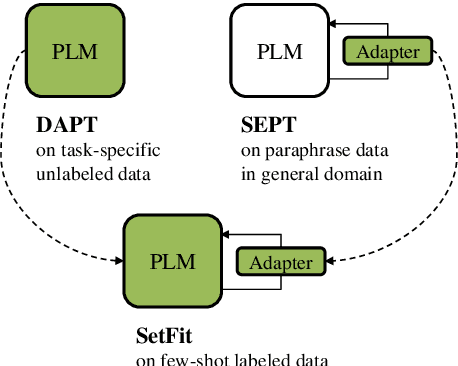

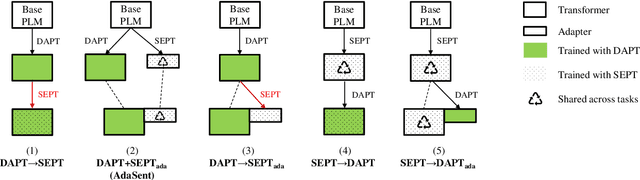
Recent work has found that few-shot sentence classification based on pre-trained Sentence Encoders (SEs) is efficient, robust, and effective. In this work, we investigate strategies for domain-specialization in the context of few-shot sentence classification with SEs. We first establish that unsupervised Domain-Adaptive Pre-Training (DAPT) of a base Pre-trained Language Model (PLM) (i.e., not an SE) substantially improves the accuracy of few-shot sentence classification by up to 8.4 points. However, applying DAPT on SEs, on the one hand, disrupts the effects of their (general-domain) Sentence Embedding Pre-Training (SEPT). On the other hand, applying general-domain SEPT on top of a domain-adapted base PLM (i.e., after DAPT) is effective but inefficient, since the computationally expensive SEPT needs to be executed on top of a DAPT-ed PLM of each domain. As a solution, we propose AdaSent, which decouples SEPT from DAPT by training a SEPT adapter on the base PLM. The adapter can be inserted into DAPT-ed PLMs from any domain. We demonstrate AdaSent's effectiveness in extensive experiments on 17 different few-shot sentence classification datasets. AdaSent matches or surpasses the performance of full SEPT on DAPT-ed PLM, while substantially reducing the training costs. The code for AdaSent is available.
Gradient Sparsification For Masked Fine-Tuning of Transformers
Jul 19, 2023
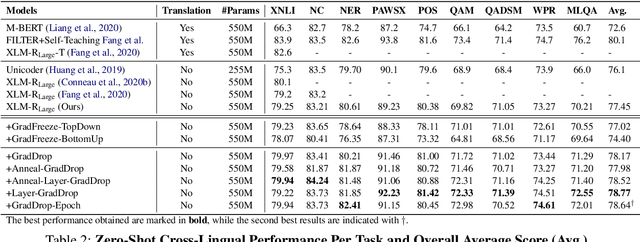
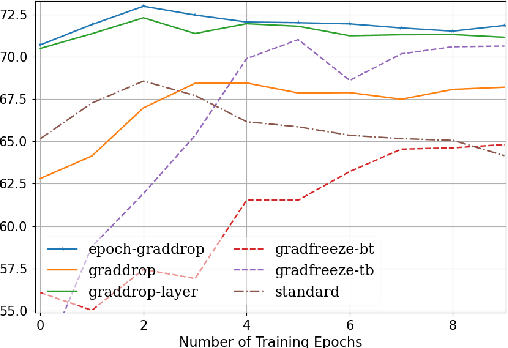
Fine-tuning pretrained self-supervised language models is widely adopted for transfer learning to downstream tasks. Fine-tuning can be achieved by freezing gradients of the pretrained network and only updating gradients of a newly added classification layer, or by performing gradient updates on all parameters. Gradual unfreezing makes a trade-off between the two by gradually unfreezing gradients of whole layers during training. This has been an effective strategy to trade-off between storage and training speed with generalization performance. However, it is not clear whether gradually unfreezing layers throughout training is optimal, compared to sparse variants of gradual unfreezing which may improve fine-tuning performance. In this paper, we propose to stochastically mask gradients to regularize pretrained language models for improving overall fine-tuned performance. We introduce GradDrop and variants thereof, a class of gradient sparsification methods that mask gradients during the backward pass, acting as gradient noise. GradDrop is sparse and stochastic unlike gradual freezing. Extensive experiments on the multilingual XGLUE benchmark with XLMR-Large show that GradDrop is competitive against methods that use additional translated data for intermediate pretraining and outperforms standard fine-tuning and gradual unfreezing. A post-analysis shows how GradDrop improves performance with languages it was not trained on, such as under-resourced languages.
Attention over pre-trained Sentence Embeddings for Long Document Classification
Jul 18, 2023



Despite being the current de-facto models in most NLP tasks, transformers are often limited to short sequences due to their quadratic attention complexity on the number of tokens. Several attempts to address this issue were studied, either by reducing the cost of the self-attention computation or by modeling smaller sequences and combining them through a recurrence mechanism or using a new transformer model. In this paper, we suggest to take advantage of pre-trained sentence transformers to start from semantically meaningful embeddings of the individual sentences, and then combine them through a small attention layer that scales linearly with the document length. We report the results obtained by this simple architecture on three standard document classification datasets. When compared with the current state-of-the-art models using standard fine-tuning, the studied method obtains competitive results (even if there is no clear best model in this configuration). We also showcase that the studied architecture obtains better results when freezing the underlying transformers. A configuration that is useful when we need to avoid complete fine-tuning (e.g. when the same frozen transformer is shared by different applications). Finally, two additional experiments are provided to further evaluate the relevancy of the studied architecture over simpler baselines.
AI-assisted Improved Service Provisioning for Low-latency XR over 5G NR
Jul 18, 2023



Extended Reality (XR) is one of the most important 5G/6G media applications that will fundamentally transform human interactions. However, ensuring low latency, high data rate, and reliability to support XR services poses significant challenges. This letter presents a novel AI-assisted service provisioning scheme that leverages predicted frames for processing rather than relying solely on actual frames. This method virtually increases the network delay budget and consequently improves service provisioning, albeit at the expense of minor prediction errors. The proposed scheme is validated by extensive simulations demonstrating a multi-fold increase in supported XR users and also provides crucial network design insights.
Self-Distilled Quantization: Achieving High Compression Rates in Transformer-Based Language Models
Jul 12, 2023



We investigate the effects of post-training quantization and quantization-aware training on the generalization of Transformer language models. We present a new method called self-distilled quantization (SDQ) that minimizes accumulative quantization errors and outperforms baselines. We apply SDQ to multilingual models XLM-R-Base and InfoXLM-Base and demonstrate that both models can be reduced from 32-bit floating point weights to 8-bit integer weights while maintaining a high level of performance on the XGLUE benchmark. Our results also highlight the challenges of quantizing multilingual models, which must generalize to languages they were not fine-tuned on.