 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAu-M-ol: A Unified Model for Medical Audio and Language Understanding
Apr 25, 2026In this work, we present Au-M-ol, a novel multimodal architecture that extends Large Language Models (LLMs) with audio processing. It is designed to improve performance on clinically relevant tasks such as Automatic Speech Recognition (ASR). Au-M-ol has three main components: (1) an audio encoder that extracts rich acoustic features from medical speech, (2) an adaptation layer that maps audio features into the LLM input space, and (3) a pretrained LLM that performs transcription and clinical language understanding. This design allows the model to interpret spoken medical content directly, improving both accuracy and robustness. In experiments, Au-M-ol reduces Word Error Rate (WER) by 56\% compared to state-of-the-art baselines on medical transcription tasks. The model also performs well in challenging conditions, including noisy environments, domain-specific terminology, and speaker variability. These results suggest that Au-M-ol is a strong candidate for real-world clinical applications, where reliable and context-aware audio understanding is essential.
Attention over pre-trained Sentence Embeddings for Long Document Classification
Jul 18, 2023



Despite being the current de-facto models in most NLP tasks, transformers are often limited to short sequences due to their quadratic attention complexity on the number of tokens. Several attempts to address this issue were studied, either by reducing the cost of the self-attention computation or by modeling smaller sequences and combining them through a recurrence mechanism or using a new transformer model. In this paper, we suggest to take advantage of pre-trained sentence transformers to start from semantically meaningful embeddings of the individual sentences, and then combine them through a small attention layer that scales linearly with the document length. We report the results obtained by this simple architecture on three standard document classification datasets. When compared with the current state-of-the-art models using standard fine-tuning, the studied method obtains competitive results (even if there is no clear best model in this configuration). We also showcase that the studied architecture obtains better results when freezing the underlying transformers. A configuration that is useful when we need to avoid complete fine-tuning (e.g. when the same frozen transformer is shared by different applications). Finally, two additional experiments are provided to further evaluate the relevancy of the studied architecture over simpler baselines.
DziriBERT: a Pre-trained Language Model for the Algerian Dialect
Sep 25, 2021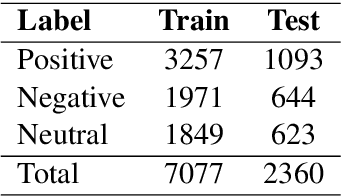
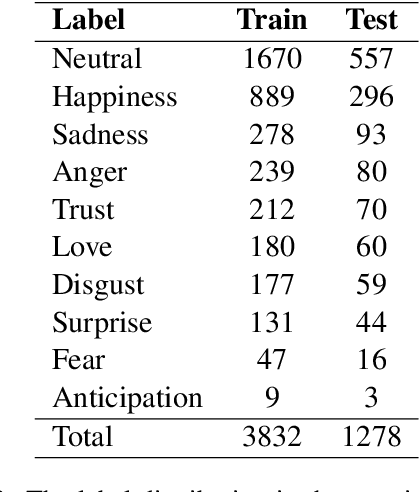
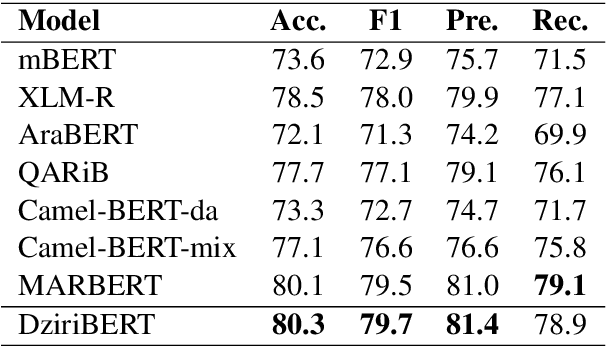
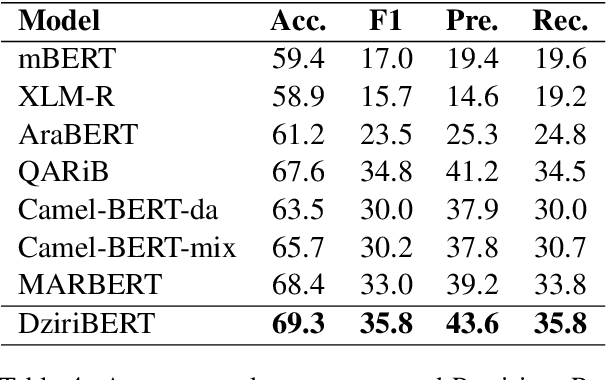
Pre-trained transformers are now the de facto models in Natural Language Processing given their state-of-the-art results in many tasks and languages. However, most of the current models have been trained on languages for which large text resources are already available (such as English, French, Arabic, etc.). Therefore, there is still a number of low-resource languages that need more attention from the community. In this paper, we study the Algerian dialect which has several specificities that make the use of Arabic or multilingual models inappropriate. To address this issue, we collected more than one Million Algerian tweets, and pre-trained the first Algerian language model: DziriBERT. When compared to existing models, DziriBERT achieves the best results on two Algerian downstream datasets. The obtained results show that pre-training a dedicated model on a small dataset (150 MB) can outperform existing models that have been trained on much more data (hundreds of GB). Finally, our model is publicly available to the community.
Load What You Need: Smaller Versions of Multilingual BERT
Oct 12, 2020


Pre-trained Transformer-based models are achieving state-of-the-art results on a variety of Natural Language Processing data sets. However, the size of these models is often a drawback for their deployment in real production applications. In the case of multilingual models, most of the parameters are located in the embeddings layer. Therefore, reducing the vocabulary size should have an important impact on the total number of parameters. In this paper, we propose to generate smaller models that handle fewer number of languages according to the targeted corpora. We present an evaluation of smaller versions of multilingual BERT on the XNLI data set, but we believe that this method may be applied to other multilingual transformers. The obtained results confirm that we can generate smaller models that keep comparable results, while reducing up to 45% of the total number of parameters. We compared our models with DistilmBERT (a distilled version of multilingual BERT) and showed that unlike language reduction, distillation induced a 1.7% to 6% drop in the overall accuracy on the XNLI data set. The presented models and code are publicly available.