 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Wave Variables: A Data-Driven Ensemble Approach for Enhanced Teleoperation Transparency and Stability
Dec 09, 2025
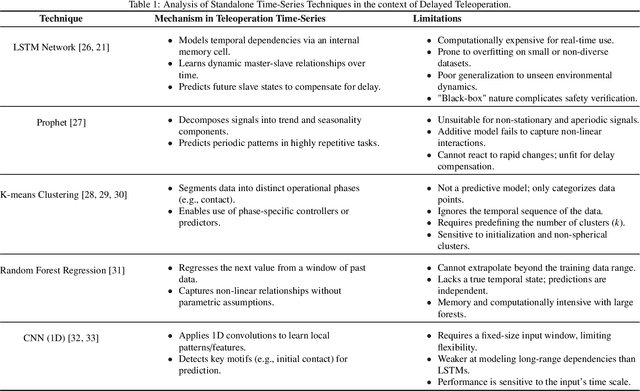
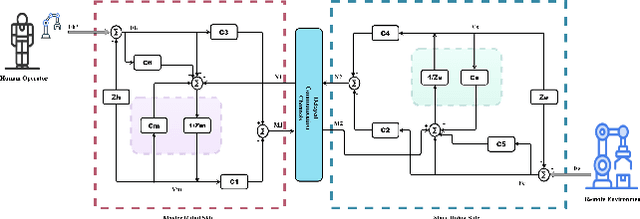
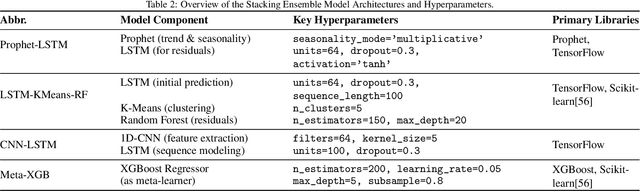
Time delays in communication channels present significant challenges for bilateral teleoperation systems, affecting both transparency and stability. Although traditional wave variable-based methods for a four-channel architecture ensure stability via passivity, they remain vulnerable to wave reflections and disturbances like variable delays and environmental noise. This article presents a data-driven hybrid framework that replaces the conventional wave-variable transform with an ensemble of three advanced sequence models, each optimized separately via the state-of-the-art Optuna optimizer, and combined through a stacking meta-learner. The base predictors include an LSTM augmented with Prophet for trend correction, an LSTM-based feature extractor paired with clustering and a random forest for improved regression, and a CNN-LSTM model for localized and long-term dynamics. Experimental validation was performed in Python using data generated from the baseline system implemented in MATLAB/Simulink. The results show that our optimized ensemble achieves a transparency comparable to the baseline wave-variable system under varying delays and noise, while ensuring stability through passivity constraints.
Classification of 24-hour movement behaviors from wrist-worn accelerometer data: from handcrafted features to deep learning techniques
Sep 10, 2025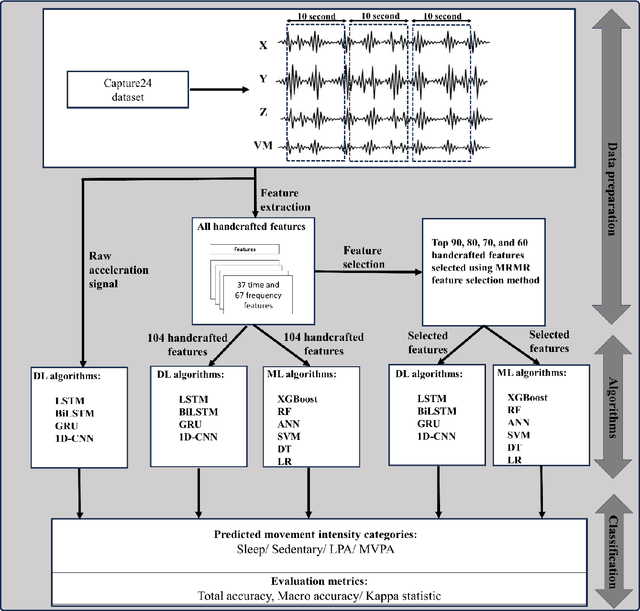


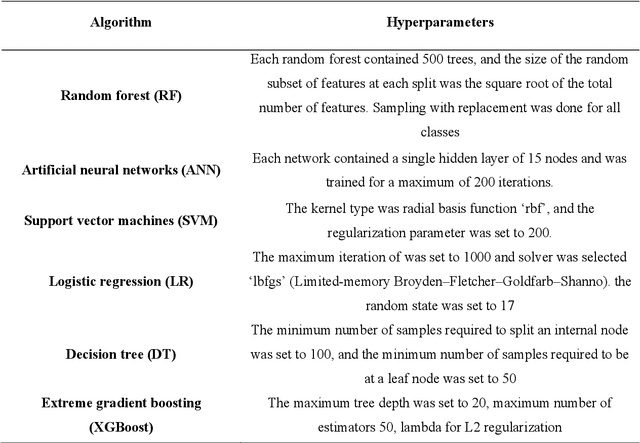
Purpose: We compared the performance of deep learning (DL) and classical machine learning (ML) algorithms for the classification of 24-hour movement behavior into sleep, sedentary, light intensity physical activity (LPA), and moderate-to-vigorous intensity physical activity (MVPA). Methods: Open-access data from 151 adults wearing a wrist-worn accelerometer (Axivity-AX3) was used. Participants were randomly divided into training, validation, and test sets (121, 15, and 15 participants each). Raw acceleration signals were segmented into non-overlapping 10-second windows, and then a total of 104 handcrafted features were extracted. Four DL algorithms-Long Short-Term Memory (LSTM), Bidirectional Long Short-Term Memory (BiLSTM), Gated Recurrent Units (GRU), and One-Dimensional Convolutional Neural Network (1D-CNN)-were trained using raw acceleration signals and with handcrafted features extracted from these signals to predict 24-hour movement behavior categories. The handcrafted features were also used to train classical ML algorithms, namely Random Forest (RF), Support Vector Machine (SVM), Extreme Gradient Boosting (XGBoost), Logistic Regression (LR), Artificial Neural Network (ANN), and Decision Tree (DT) for classifying 24-hour movement behavior intensities. Results: LSTM, BiLSTM, and GRU showed an overall accuracy of approximately 85% when trained with raw acceleration signals, and 1D-CNN an overall accuracy of approximately 80%. When trained on handcrafted features, the overall accuracy for both DL and classical ML algorithms ranged from 70% to 81%. Overall, there was a higher confusion in classification of MVPA and LPA, compared to sleep and sedentary categories. Conclusion: DL methods with raw acceleration signals had only slightly better performance in predicting 24-hour movement behavior intensities, compared to when DL and classical ML were trained with handcrafted features.
A Comprehensive Study on NLP Data Augmentation for Hate Speech Detection: Legacy Methods, BERT, and LLMs
Mar 30, 2024



The surge of interest in data augmentation within the realm of NLP has been driven by the need to address challenges posed by hate speech domains, the dynamic nature of social media vocabulary, and the demands for large-scale neural networks requiring extensive training data. However, the prevalent use of lexical substitution in data augmentation has raised concerns, as it may inadvertently alter the intended meaning, thereby impacting the efficacy of supervised machine learning models. In pursuit of suitable data augmentation methods, this study explores both established legacy approaches and contemporary practices such as Large Language Models (LLM), including GPT in Hate Speech detection. Additionally, we propose an optimized utilization of BERT-based encoder models with contextual cosine similarity filtration, exposing significant limitations in prior synonym substitution methods. Our comparative analysis encompasses five popular augmentation techniques: WordNet and Fast-Text synonym replacement, Back-translation, BERT-mask contextual augmentation, and LLM. Our analysis across five benchmarked datasets revealed that while traditional methods like back-translation show low label alteration rates (0.3-1.5%), and BERT-based contextual synonym replacement offers sentence diversity but at the cost of higher label alteration rates (over 6%). Our proposed BERT-based contextual cosine similarity filtration markedly reduced label alteration to just 0.05%, demonstrating its efficacy in 0.7% higher F1 performance. However, augmenting data with GPT-3 not only avoided overfitting with up to sevenfold data increase but also improved embedding space coverage by 15% and classification F1 score by 1.4% over traditional methods, and by 0.8% over our method.
Cross-Linguistic Offensive Language Detection: BERT-Based Analysis of Bengali, Assamese, & Bodo Conversational Hateful Content from Social Media
Dec 16, 2023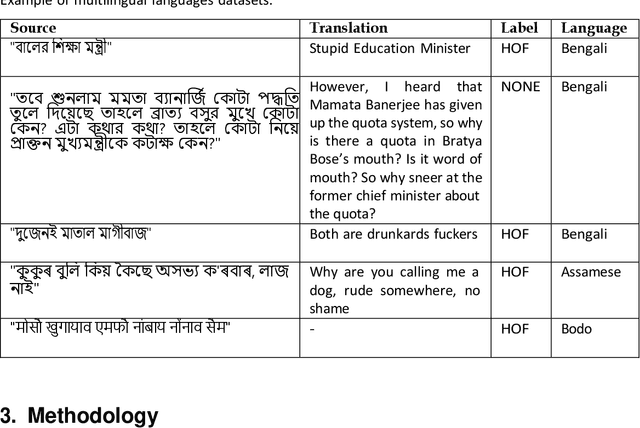



In today's age, social media reigns as the paramount communication platform, providing individuals with the avenue to express their conjectures, intellectual propositions, and reflections. Unfortunately, this freedom often comes with a downside as it facilitates the widespread proliferation of hate speech and offensive content, leaving a deleterious impact on our world. Thus, it becomes essential to discern and eradicate such offensive material from the realm of social media. This article delves into the comprehensive results and key revelations from the HASOC-2023 offensive language identification result. The primary emphasis is placed on the meticulous detection of hate speech within the linguistic domains of Bengali, Assamese, and Bodo, forming the framework for Task 4: Annihilate Hates. In this work, we used BERT models, including XML-Roberta, L3-cube, IndicBERT, BenglaBERT, and BanglaHateBERT. The research outcomes were promising and showed that XML-Roberta-lagre performed better than monolingual models in most cases. Our team 'TeamBD' achieved rank 3rd for Task 4 - Assamese, & 5th for Bengali.
Semi-Supervised learning for Face Anti-Spoofing using Apex frame
Sep 10, 2023


Conventional feature extraction techniques in the face anti-spoofing domain either analyze the entire video sequence or focus on a specific segment to improve model performance. However, identifying the optimal frames that provide the most valuable input for the face anti-spoofing remains a challenging task. In this paper, we address this challenge by employing Gaussian weighting to create apex frames for videos. Specifically, an apex frame is derived from a video by computing a weighted sum of its frames, where the weights are determined using a Gaussian distribution centered around the video's central frame. Furthermore, we explore various temporal lengths to produce multiple unlabeled apex frames using a Gaussian function, without the need for convolution. By doing so, we leverage the benefits of semi-supervised learning, which considers both labeled and unlabeled apex frames to effectively discriminate between live and spoof classes. Our key contribution emphasizes the apex frame's capacity to represent the most significant moments in the video, while unlabeled apex frames facilitate efficient semi-supervised learning, as they enable the model to learn from videos of varying temporal lengths. Experimental results using four face anti-spoofing databases: CASIA, REPLAY-ATTACK, OULU-NPU, and MSU-MFSD demonstrate the apex frame's efficacy in advancing face anti-spoofing techniques.
Saliency-based Video Summarization for Face Anti-spoofing
Aug 23, 2023



Due to the growing availability of face anti-spoofing databases, researchers are increasingly focusing on video-based methods that use hundreds to thousands of images to assess their impact on performance. However, there is no clear consensus on the exact number of frames in a video required to improve the performance of face anti-spoofing tasks. Inspired by the visual saliency theory, we present a video summarization method for face anti-spoofing tasks that aims to enhance the performance and efficiency of deep learning models by leveraging visual saliency. In particular, saliency information is extracted from the differences between the Laplacian and Wiener filter outputs of the source images, enabling identification of the most visually salient regions within each frame. Subsequently, the source images are decomposed into base and detail layers, enhancing representation of important information. The weighting maps are then computed based on the saliency information, indicating the importance of each pixel in the image. By linearly combining the base and detail layers using the weighting maps, the method fuses the source images to create a single representative image that summarizes the entire video. The key contribution of our proposed method lies in demonstrating how visual saliency can be used as a data-centric approach to improve the performance and efficiency of face presentation attack detection models. By focusing on the most salient images or regions within the images, a more representative and diverse training set can be created, potentially leading to more effective models. To validate the method's effectiveness, a simple deep learning architecture (CNN-RNN) was used, and the experimental results showcased state-of-the-art performance on five challenging face anti-spoofing datasets.
Deep Ensemble Learning with Frame Skipping for Face Anti-Spoofing
Jul 11, 2023Face presentation attacks (PA), also known as spoofing attacks, pose a substantial threat to biometric systems that rely on facial recognition systems, such as access control systems, mobile payments, and identity verification systems. To mitigate the spoofing risk, several video-based methods have been presented in the literature that analyze facial motion in successive video frames. However, estimating the motion between adjacent frames is a challenging task and requires high computational cost. In this paper, we rephrase the face anti-spoofing task as a motion prediction problem and introduce a deep ensemble learning model with a frame skipping mechanism. In particular, the proposed frame skipping adopts a uniform sampling approach by dividing the original video into video clips of fixed size. By doing so, every nth frame of the clip is selected to ensure that the temporal patterns can easily be perceived during the training of three different recurrent neural networks (RNNs). Motivated by the performance of individual RNNs, a meta-model is developed to improve the overall detection performance by combining the prediction of individual RNNs. Extensive experiments were performed on four datasets, and state-of-the-art performance is reported on MSU-MFSD (3.12%), Replay-Attack (11.19%), and OULU-NPU (12.23%) databases by using half total error rates (HTERs) in the most challenging cross-dataset testing scenario.
Domain Generalization via Ensemble Stacking for Face Presentation Attack Detection
Jan 05, 2023Face presentation attack detection (PAD) plays a pivotal role in securing face recognition systems against spoofing attacks. Although great progress has been made in designing face PAD methods, developing a model that can generalize well to an unseen test domain remains a significant challenge. Moreover, due to different types of spoofing attacks, creating a dataset with a sufficient number of samples for training deep neural networks is a laborious task. This work addresses these challenges by creating synthetic data and introducing a deep learning-based unified framework for improving the generalization ability of the face PAD. In particular, synthetic data is generated by proposing a video distillation technique that blends a spatiotemporal warped image with a still image based on alpha compositing. Since the proposed synthetic samples can be generated by increasing different alpha weights, we train multiple classifiers by taking the advantage of a specific type of ensemble learning known as a stacked ensemble, where each such classifier becomes an expert in its own domain but a non-expert to others. Motivated by this, a meta-classifier is employed to learn from these experts collaboratively so that when developing an ensemble, they can leverage complementary information from each other to better tackle or be more useful for an unseen target domain. Experimental results using half total error rates (HTERs) on four PAD databases CASIA-MFSD (6.97 %), Replay-Attack (33.49%), MSU-MFSD (4.02%), and OULU-NPU (10.91%)) demonstrate the robustness of the method and open up new possibilities for advancing presentation attack detection using ensemble learning with large-scale synthetic data.
Face Anti-Spoofing from the Perspective of Data Sampling
Aug 28, 2022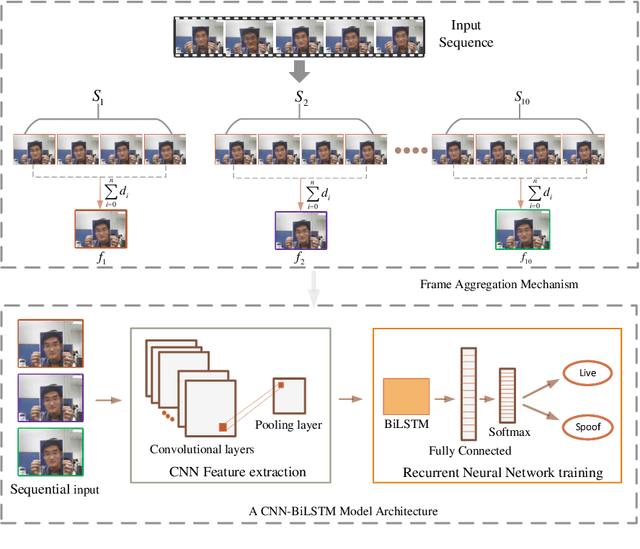



Without deploying face anti-spoofing countermeasures, face recognition systems can be spoofed by presenting a printed photo, a video, or a silicon mask of a genuine user. Thus, face presentation attack detection (PAD) plays a vital role in providing secure facial access to digital devices. Most existing video-based PAD countermeasures lack the ability to cope with long-range temporal variations in videos. Moreover, the key-frame sampling prior to the feature extraction step has not been widely studied in the face anti-spoofing domain. To mitigate these issues, this paper provides a data sampling approach by proposing a video processing scheme that models the long-range temporal variations based on Gaussian Weighting Function. Specifically, the proposed scheme encodes the consecutive t frames of video sequences into a single RGB image based on a Gaussian-weighted summation of the t frames. Using simply the data sampling scheme alone, we demonstrate that state-of-the-art performance can be achieved without any bells and whistles in both intra-database and inter-database testing scenarios for the three public benchmark datasets; namely, Replay-Attack, MSU-MFSD, and CASIA-FASD. In particular, the proposed scheme provides a much lower error (from 15.2% to 6.7% on CASIA-FASD and 5.9% to 4.9% on Replay-Attack) compared to baselines in cross-database scenarios.
Self-Supervised Face Presentation Attack Detection with Dynamic Grayscale Snippets
Aug 27, 2022
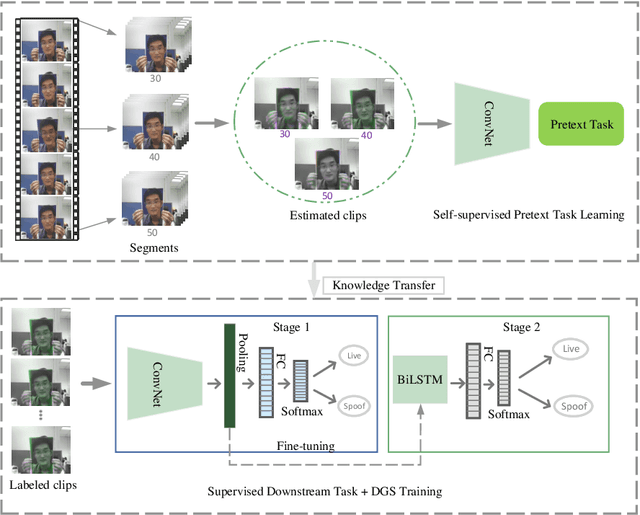
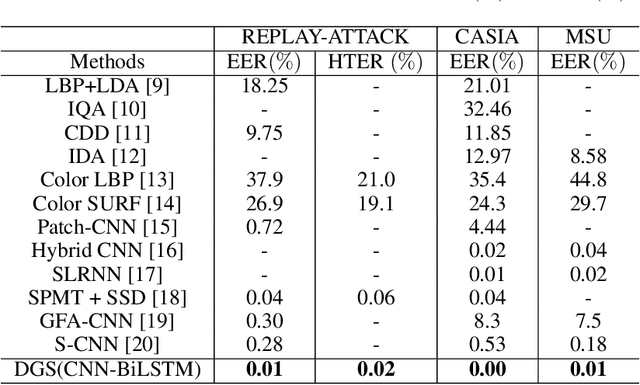
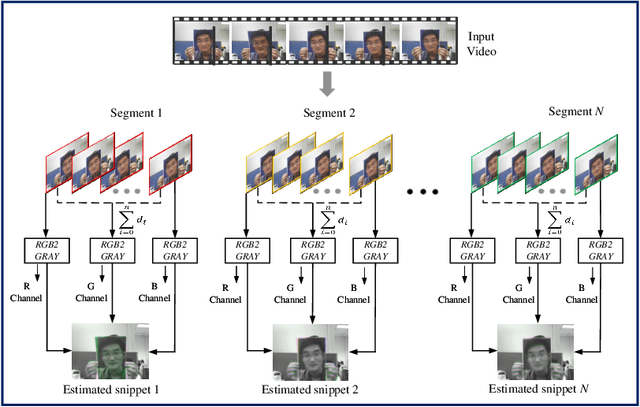
Face presentation attack detection (PAD) plays an important role in defending face recognition systems against presentation attacks. The success of PAD largely relies on supervised learning that requires a huge number of labeled data, which is especially challenging for videos and often requires expert knowledge. To avoid the costly collection of labeled data, this paper presents a novel method for self-supervised video representation learning via motion prediction. To achieve this, we exploit the temporal consistency based on three RGB frames which are acquired at three different times in the video sequence. The obtained frames are then transformed into grayscale images where each image is specified to three different channels such as R(red), G(green), and B(blue) to form a dynamic grayscale snippet (DGS). Motivated by this, the labels are automatically generated to increase the temporal diversity based on DGS by using the different temporal lengths of the videos, which prove to be very helpful for the downstream task. Benefiting from the self-supervised nature of our method, we report the results that outperform existing methods on four public benchmark datasets, namely Replay-Attack, MSU-MFSD, CASIA-FASD, and OULU-NPU. Explainability analysis has been carried out through LIME and Grad-CAM techniques to visualize the most important features used in the DGS.