 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Domain Convolutional Network for Hyperspectral Single-Image Super-Resolution
Dec 10, 2025



This study presents a lightweight dual-domain super-resolution network (DDSRNet) that combines Spatial-Net with the discrete wavelet transform (DWT). Specifically, our proposed model comprises three main components: (1) a shallow feature extraction module, termed Spatial-Net, which performs residual learning and bilinear interpolation; (2) a low-frequency enhancement branch based on the DWT that refines coarse image structures; and (3) a shared high-frequency refinement branch that simultaneously enhances the LH (horizontal), HL (vertical), and HH (diagonal) wavelet subbands using a single CNN with shared weights. As a result, the DWT enables subband decomposition, while the inverse DWT reconstructs the final high-resolution output. By doing so, the integration of spatial- and frequency-domain learning enables DDSRNet to achieve highly competitive performance with low computational cost on three hyperspectral image datasets, demonstrating its effectiveness for hyperspectral image super-resolution.
DACN: Dual-Attention Convolutional Network for Hyperspectral Image Super-Resolution
Jun 05, 20252D convolutional neural networks (CNNs) have attracted significant attention for hyperspectral image super-resolution tasks. However, a key limitation is their reliance on local neighborhoods, which leads to a lack of global contextual understanding. Moreover, band correlation and data scarcity continue to limit their performance. To mitigate these issues, we introduce DACN, a dual-attention convolutional network for hyperspectral image super-resolution. Specifically, the model first employs augmented convolutions, integrating multi-head attention to effectively capture both local and global feature dependencies. Next, we infer separate attention maps for the channel and spatial dimensions to determine where to focus across different channels and spatial positions. Furthermore, a custom optimized loss function is proposed that combines L2 regularization with spatial-spectral gradient loss to ensure accurate spectral fidelity. Experimental results on two hyperspectral datasets demonstrate that the combination of multi-head attention and channel attention outperforms either attention mechanism used individually.
A Fusion-Guided Inception Network for Hyperspectral Image Super-Resolution
May 06, 2025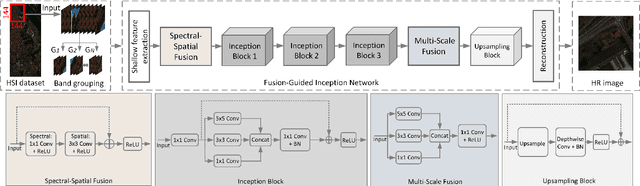
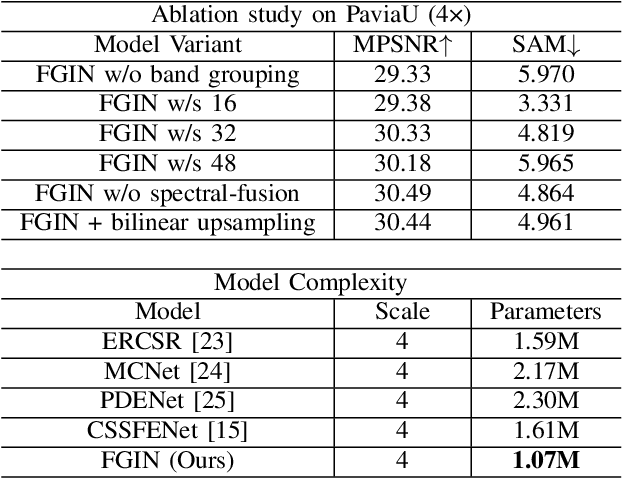
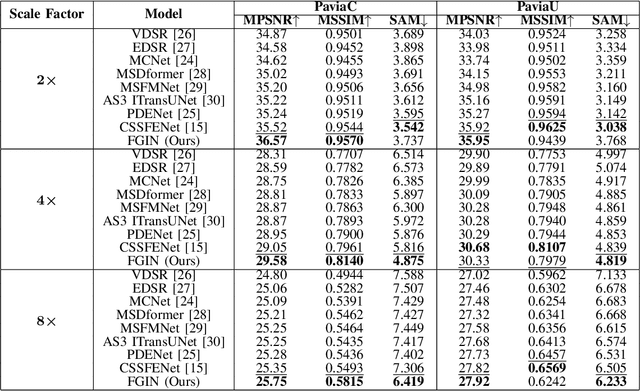
The fusion of low-spatial-resolution hyperspectral images (HSIs) with high-spatial-resolution conventional images (e.g., panchromatic or RGB) has played a significant role in recent advancements in HSI super-resolution. However, this fusion process relies on the availability of precise alignment between image pairs, which is often challenging in real-world scenarios. To mitigate this limitation, we propose a single-image super-resolution model called the Fusion-Guided Inception Network (FGIN). Specifically, we first employ a spectral-spatial fusion module to effectively integrate spectral and spatial information at an early stage. Next, an Inception-like hierarchical feature extraction strategy is used to capture multiscale spatial dependencies, followed by a dedicated multi-scale fusion block. To further enhance reconstruction quality, we incorporate an optimized upsampling module that combines bilinear interpolation with depthwise separable convolutions. Experimental evaluations on two publicly available hyperspectral datasets demonstrate the competitive performance of our method.
Towards Lightweight Hyperspectral Image Super-Resolution with Depthwise Separable Dilated Convolutional Network
May 01, 2025Deep neural networks have demonstrated highly competitive performance in super-resolution (SR) for natural images by learning mappings from low-resolution (LR) to high-resolution (HR) images. However, hyperspectral super-resolution remains an ill-posed problem due to the high spectral dimensionality of the data and the scarcity of available training samples. Moreover, existing methods often rely on large models with a high number of parameters or require the fusion with panchromatic or RGB images, both of which are often impractical in real-world scenarios. Inspired by the MobileNet architecture, we introduce a lightweight depthwise separable dilated convolutional network (DSDCN) to address the aforementioned challenges. Specifically, our model leverages multiple depthwise separable convolutions, similar to the MobileNet architecture, and further incorporates a dilated convolution fusion block to make the model more flexible for the extraction of both spatial and spectral features. In addition, we propose a custom loss function that combines mean squared error (MSE), an L2 norm regularization-based constraint, and a spectral angle-based loss, ensuring the preservation of both spectral and spatial details. The proposed model achieves very competitive performance on two publicly available hyperspectral datasets, making it well-suited for hyperspectral image super-resolution tasks. The source codes are publicly available at: \href{https://github.com/Usman1021/lightweight}{https://github.com/Usman1021/lightweight}.
Semi-Supervised learning for Face Anti-Spoofing using Apex frame
Sep 10, 2023


Conventional feature extraction techniques in the face anti-spoofing domain either analyze the entire video sequence or focus on a specific segment to improve model performance. However, identifying the optimal frames that provide the most valuable input for the face anti-spoofing remains a challenging task. In this paper, we address this challenge by employing Gaussian weighting to create apex frames for videos. Specifically, an apex frame is derived from a video by computing a weighted sum of its frames, where the weights are determined using a Gaussian distribution centered around the video's central frame. Furthermore, we explore various temporal lengths to produce multiple unlabeled apex frames using a Gaussian function, without the need for convolution. By doing so, we leverage the benefits of semi-supervised learning, which considers both labeled and unlabeled apex frames to effectively discriminate between live and spoof classes. Our key contribution emphasizes the apex frame's capacity to represent the most significant moments in the video, while unlabeled apex frames facilitate efficient semi-supervised learning, as they enable the model to learn from videos of varying temporal lengths. Experimental results using four face anti-spoofing databases: CASIA, REPLAY-ATTACK, OULU-NPU, and MSU-MFSD demonstrate the apex frame's efficacy in advancing face anti-spoofing techniques.
Saliency-based Video Summarization for Face Anti-spoofing
Aug 23, 2023



Due to the growing availability of face anti-spoofing databases, researchers are increasingly focusing on video-based methods that use hundreds to thousands of images to assess their impact on performance. However, there is no clear consensus on the exact number of frames in a video required to improve the performance of face anti-spoofing tasks. Inspired by the visual saliency theory, we present a video summarization method for face anti-spoofing tasks that aims to enhance the performance and efficiency of deep learning models by leveraging visual saliency. In particular, saliency information is extracted from the differences between the Laplacian and Wiener filter outputs of the source images, enabling identification of the most visually salient regions within each frame. Subsequently, the source images are decomposed into base and detail layers, enhancing representation of important information. The weighting maps are then computed based on the saliency information, indicating the importance of each pixel in the image. By linearly combining the base and detail layers using the weighting maps, the method fuses the source images to create a single representative image that summarizes the entire video. The key contribution of our proposed method lies in demonstrating how visual saliency can be used as a data-centric approach to improve the performance and efficiency of face presentation attack detection models. By focusing on the most salient images or regions within the images, a more representative and diverse training set can be created, potentially leading to more effective models. To validate the method's effectiveness, a simple deep learning architecture (CNN-RNN) was used, and the experimental results showcased state-of-the-art performance on five challenging face anti-spoofing datasets.
Deep Ensemble Learning with Frame Skipping for Face Anti-Spoofing
Jul 11, 2023Face presentation attacks (PA), also known as spoofing attacks, pose a substantial threat to biometric systems that rely on facial recognition systems, such as access control systems, mobile payments, and identity verification systems. To mitigate the spoofing risk, several video-based methods have been presented in the literature that analyze facial motion in successive video frames. However, estimating the motion between adjacent frames is a challenging task and requires high computational cost. In this paper, we rephrase the face anti-spoofing task as a motion prediction problem and introduce a deep ensemble learning model with a frame skipping mechanism. In particular, the proposed frame skipping adopts a uniform sampling approach by dividing the original video into video clips of fixed size. By doing so, every nth frame of the clip is selected to ensure that the temporal patterns can easily be perceived during the training of three different recurrent neural networks (RNNs). Motivated by the performance of individual RNNs, a meta-model is developed to improve the overall detection performance by combining the prediction of individual RNNs. Extensive experiments were performed on four datasets, and state-of-the-art performance is reported on MSU-MFSD (3.12%), Replay-Attack (11.19%), and OULU-NPU (12.23%) databases by using half total error rates (HTERs) in the most challenging cross-dataset testing scenario.
Domain Generalization via Ensemble Stacking for Face Presentation Attack Detection
Jan 05, 2023Face presentation attack detection (PAD) plays a pivotal role in securing face recognition systems against spoofing attacks. Although great progress has been made in designing face PAD methods, developing a model that can generalize well to an unseen test domain remains a significant challenge. Moreover, due to different types of spoofing attacks, creating a dataset with a sufficient number of samples for training deep neural networks is a laborious task. This work addresses these challenges by creating synthetic data and introducing a deep learning-based unified framework for improving the generalization ability of the face PAD. In particular, synthetic data is generated by proposing a video distillation technique that blends a spatiotemporal warped image with a still image based on alpha compositing. Since the proposed synthetic samples can be generated by increasing different alpha weights, we train multiple classifiers by taking the advantage of a specific type of ensemble learning known as a stacked ensemble, where each such classifier becomes an expert in its own domain but a non-expert to others. Motivated by this, a meta-classifier is employed to learn from these experts collaboratively so that when developing an ensemble, they can leverage complementary information from each other to better tackle or be more useful for an unseen target domain. Experimental results using half total error rates (HTERs) on four PAD databases CASIA-MFSD (6.97 %), Replay-Attack (33.49%), MSU-MFSD (4.02%), and OULU-NPU (10.91%)) demonstrate the robustness of the method and open up new possibilities for advancing presentation attack detection using ensemble learning with large-scale synthetic data.
Face Anti-Spoofing from the Perspective of Data Sampling
Aug 28, 2022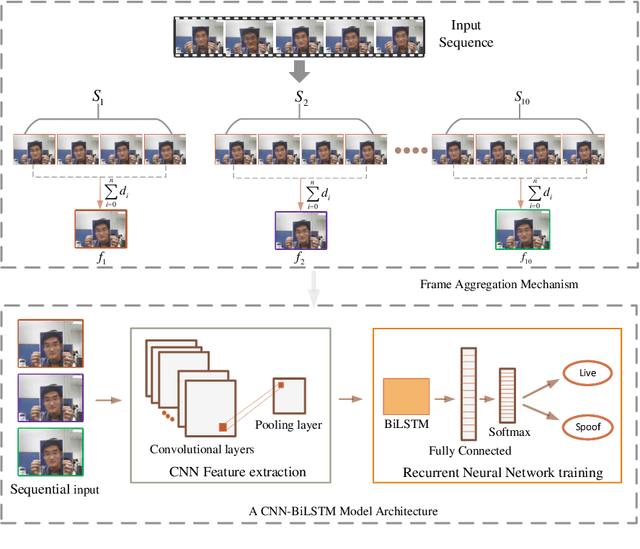



Without deploying face anti-spoofing countermeasures, face recognition systems can be spoofed by presenting a printed photo, a video, or a silicon mask of a genuine user. Thus, face presentation attack detection (PAD) plays a vital role in providing secure facial access to digital devices. Most existing video-based PAD countermeasures lack the ability to cope with long-range temporal variations in videos. Moreover, the key-frame sampling prior to the feature extraction step has not been widely studied in the face anti-spoofing domain. To mitigate these issues, this paper provides a data sampling approach by proposing a video processing scheme that models the long-range temporal variations based on Gaussian Weighting Function. Specifically, the proposed scheme encodes the consecutive t frames of video sequences into a single RGB image based on a Gaussian-weighted summation of the t frames. Using simply the data sampling scheme alone, we demonstrate that state-of-the-art performance can be achieved without any bells and whistles in both intra-database and inter-database testing scenarios for the three public benchmark datasets; namely, Replay-Attack, MSU-MFSD, and CASIA-FASD. In particular, the proposed scheme provides a much lower error (from 15.2% to 6.7% on CASIA-FASD and 5.9% to 4.9% on Replay-Attack) compared to baselines in cross-database scenarios.
Self-Supervised Face Presentation Attack Detection with Dynamic Grayscale Snippets
Aug 27, 2022
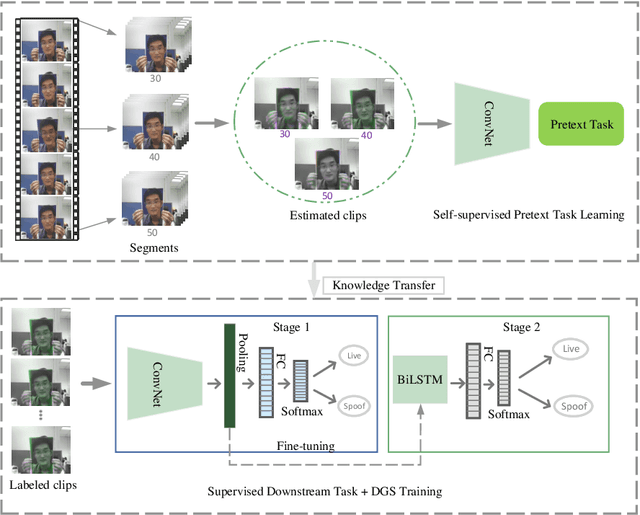
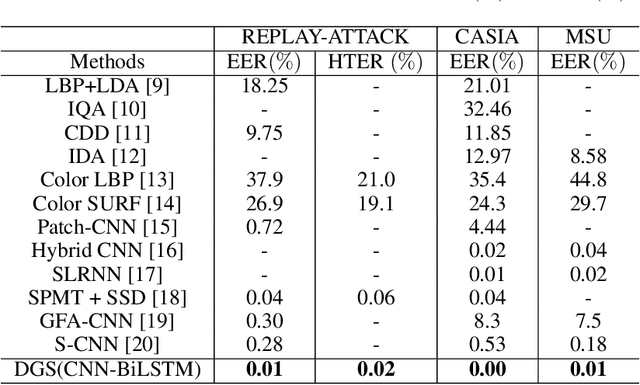
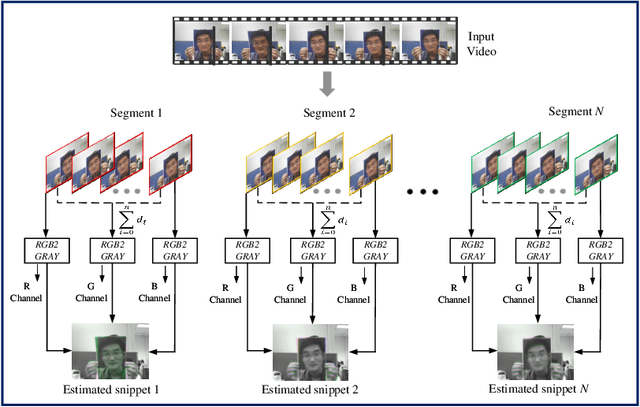
Face presentation attack detection (PAD) plays an important role in defending face recognition systems against presentation attacks. The success of PAD largely relies on supervised learning that requires a huge number of labeled data, which is especially challenging for videos and often requires expert knowledge. To avoid the costly collection of labeled data, this paper presents a novel method for self-supervised video representation learning via motion prediction. To achieve this, we exploit the temporal consistency based on three RGB frames which are acquired at three different times in the video sequence. The obtained frames are then transformed into grayscale images where each image is specified to three different channels such as R(red), G(green), and B(blue) to form a dynamic grayscale snippet (DGS). Motivated by this, the labels are automatically generated to increase the temporal diversity based on DGS by using the different temporal lengths of the videos, which prove to be very helpful for the downstream task. Benefiting from the self-supervised nature of our method, we report the results that outperform existing methods on four public benchmark datasets, namely Replay-Attack, MSU-MFSD, CASIA-FASD, and OULU-NPU. Explainability analysis has been carried out through LIME and Grad-CAM techniques to visualize the most important features used in the DGS.