 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Domain Convolutional Network for Hyperspectral Single-Image Super-Resolution
Dec 10, 2025



This study presents a lightweight dual-domain super-resolution network (DDSRNet) that combines Spatial-Net with the discrete wavelet transform (DWT). Specifically, our proposed model comprises three main components: (1) a shallow feature extraction module, termed Spatial-Net, which performs residual learning and bilinear interpolation; (2) a low-frequency enhancement branch based on the DWT that refines coarse image structures; and (3) a shared high-frequency refinement branch that simultaneously enhances the LH (horizontal), HL (vertical), and HH (diagonal) wavelet subbands using a single CNN with shared weights. As a result, the DWT enables subband decomposition, while the inverse DWT reconstructs the final high-resolution output. By doing so, the integration of spatial- and frequency-domain learning enables DDSRNet to achieve highly competitive performance with low computational cost on three hyperspectral image datasets, demonstrating its effectiveness for hyperspectral image super-resolution.
MIRA: A Novel Framework for Fusing Modalities in Medical RAG
Jul 10, 2025Multimodal Large Language Models (MLLMs) have significantly advanced AI-assisted medical diagnosis, but they often generate factually inconsistent responses that deviate from established medical knowledge. Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external sources, but it presents two key challenges. First, insufficient retrieval can miss critical information, whereas excessive retrieval can introduce irrelevant or misleading content, disrupting model output. Second, even when the model initially provides correct answers, over-reliance on retrieved data can lead to factual errors. To address these issues, we introduce the Multimodal Intelligent Retrieval and Augmentation (MIRA) framework, designed to optimize factual accuracy in MLLM. MIRA consists of two key components: (1) a calibrated Rethinking and Rearrangement module that dynamically adjusts the number of retrieved contexts to manage factual risk, and (2) A medical RAG framework integrating image embeddings and a medical knowledge base with a query-rewrite module for efficient multimodal reasoning. This enables the model to effectively integrate both its inherent knowledge and external references. Our evaluation of publicly available medical VQA and report generation benchmarks demonstrates that MIRA substantially enhances factual accuracy and overall performance, achieving new state-of-the-art results. Code is released at https://github.com/mbzuai-oryx/MIRA.
TerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation
Jun 06, 2025Modern Earth observation (EO) increasingly leverages deep learning to harness the scale and diversity of satellite imagery across sensors and regions. While recent foundation models have demonstrated promising generalization across EO tasks, many remain limited by the scale, geographical coverage, and spectral diversity of their training data, factors critical for learning globally transferable representations. In this work, we introduce TerraFM, a scalable self-supervised learning model that leverages globally distributed Sentinel-1 and Sentinel-2 imagery, combined with large spatial tiles and land-cover aware sampling to enrich spatial and semantic coverage. By treating sensing modalities as natural augmentations in our self-supervised approach, we unify radar and optical inputs via modality-specific patch embeddings and adaptive cross-attention fusion. Our training strategy integrates local-global contrastive learning and introduces a dual-centering mechanism that incorporates class-frequency-aware regularization to address long-tailed distributions in land cover.TerraFM achieves strong generalization on both classification and segmentation tasks, outperforming prior models on GEO-Bench and Copernicus-Bench. Our code and pretrained models are publicly available at: https://github.com/mbzuai-oryx/TerraFM .
DACN: Dual-Attention Convolutional Network for Hyperspectral Image Super-Resolution
Jun 05, 20252D convolutional neural networks (CNNs) have attracted significant attention for hyperspectral image super-resolution tasks. However, a key limitation is their reliance on local neighborhoods, which leads to a lack of global contextual understanding. Moreover, band correlation and data scarcity continue to limit their performance. To mitigate these issues, we introduce DACN, a dual-attention convolutional network for hyperspectral image super-resolution. Specifically, the model first employs augmented convolutions, integrating multi-head attention to effectively capture both local and global feature dependencies. Next, we infer separate attention maps for the channel and spatial dimensions to determine where to focus across different channels and spatial positions. Furthermore, a custom optimized loss function is proposed that combines L2 regularization with spatial-spectral gradient loss to ensure accurate spectral fidelity. Experimental results on two hyperspectral datasets demonstrate that the combination of multi-head attention and channel attention outperforms either attention mechanism used individually.
ARB: A Comprehensive Arabic Multimodal Reasoning Benchmark
May 22, 2025
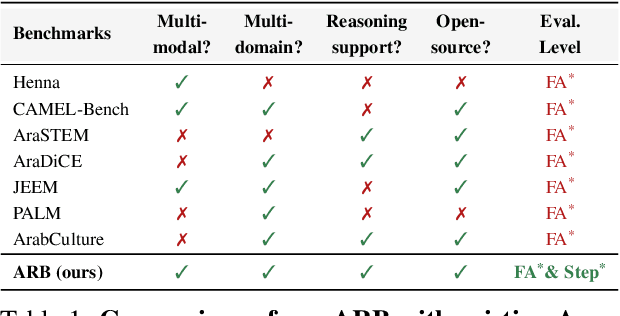
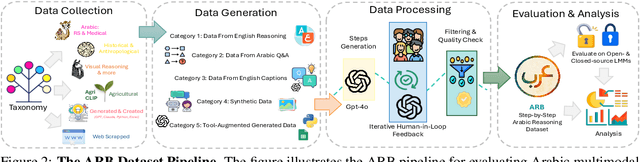
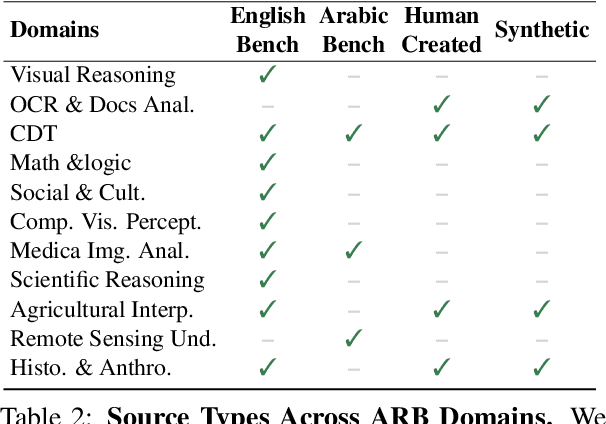
As Large Multimodal Models (LMMs) become more capable, there is growing interest in evaluating their reasoning processes alongside their final outputs. However, most benchmarks remain focused on English, overlooking languages with rich linguistic and cultural contexts, such as Arabic. To address this gap, we introduce the Comprehensive Arabic Multimodal Reasoning Benchmark (ARB), the first benchmark designed to evaluate step-by-step reasoning in Arabic across both textual and visual modalities. ARB spans 11 diverse domains, including visual reasoning, document understanding, OCR, scientific analysis, and cultural interpretation. It comprises 1,356 multimodal samples paired with 5,119 human-curated reasoning steps and corresponding actions. We evaluated 12 state-of-the-art open- and closed-source LMMs and found persistent challenges in coherence, faithfulness, and cultural grounding. ARB offers a structured framework for diagnosing multimodal reasoning in underrepresented languages and marks a critical step toward inclusive, transparent, and culturally aware AI systems. We release the benchmark, rubric, and evaluation suit to support future research and reproducibility. Code available at: https://github.com/mbzuai-oryx/ARB
OpenSeg-R: Improving Open-Vocabulary Segmentation via Step-by-Step Visual Reasoning
May 22, 2025Open-Vocabulary Segmentation (OVS) has drawn increasing attention for its capacity to generalize segmentation beyond predefined categories. However, existing methods typically predict segmentation masks with simple forward inference, lacking explicit reasoning and interpretability. This makes it challenging for OVS model to distinguish similar categories in open-world settings due to the lack of contextual understanding and discriminative visual cues. To address this limitation, we propose a step-by-step visual reasoning framework for open-vocabulary segmentation, named OpenSeg-R. The proposed OpenSeg-R leverages Large Multimodal Models (LMMs) to perform hierarchical visual reasoning before segmentation. Specifically, we generate both generic and image-specific reasoning for each image, forming structured triplets that explain the visual reason for objects in a coarse-to-fine manner. Based on these reasoning steps, we can compose detailed description prompts, and feed them to the segmentor to produce more accurate segmentation masks. To the best of our knowledge, OpenSeg-R is the first framework to introduce explicit step-by-step visual reasoning into OVS. Experimental results demonstrate that OpenSeg-R significantly outperforms state-of-the-art methods on open-vocabulary semantic segmentation across five benchmark datasets. Moreover, it achieves consistent gains across all metrics on open-vocabulary panoptic segmentation. Qualitative results further highlight the effectiveness of our reasoning-guided framework in improving both segmentation precision and interpretability. Our code is publicly available at https://github.com/Hanzy1996/OpenSeg-R.
A Fusion-Guided Inception Network for Hyperspectral Image Super-Resolution
May 06, 2025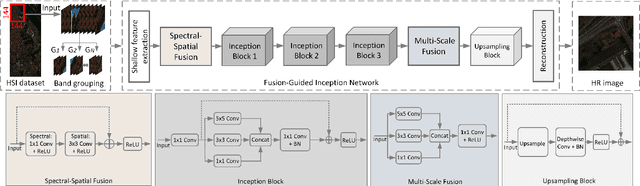
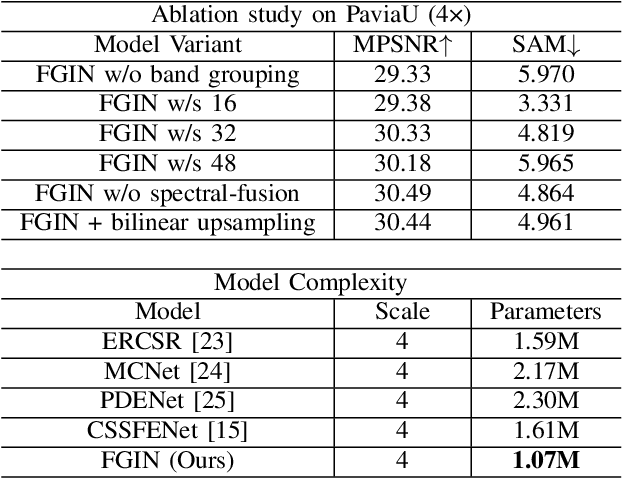
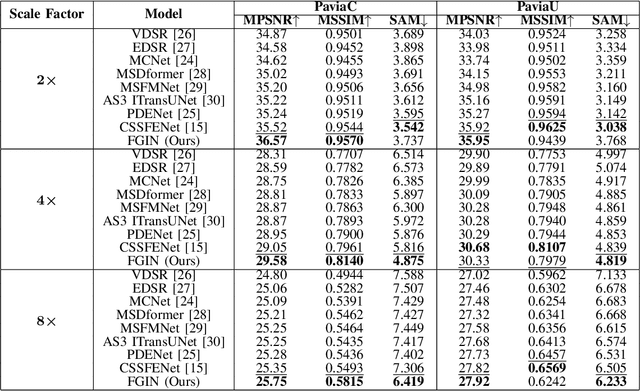
The fusion of low-spatial-resolution hyperspectral images (HSIs) with high-spatial-resolution conventional images (e.g., panchromatic or RGB) has played a significant role in recent advancements in HSI super-resolution. However, this fusion process relies on the availability of precise alignment between image pairs, which is often challenging in real-world scenarios. To mitigate this limitation, we propose a single-image super-resolution model called the Fusion-Guided Inception Network (FGIN). Specifically, we first employ a spectral-spatial fusion module to effectively integrate spectral and spatial information at an early stage. Next, an Inception-like hierarchical feature extraction strategy is used to capture multiscale spatial dependencies, followed by a dedicated multi-scale fusion block. To further enhance reconstruction quality, we incorporate an optimized upsampling module that combines bilinear interpolation with depthwise separable convolutions. Experimental evaluations on two publicly available hyperspectral datasets demonstrate the competitive performance of our method.
Towards Lightweight Hyperspectral Image Super-Resolution with Depthwise Separable Dilated Convolutional Network
May 01, 2025Deep neural networks have demonstrated highly competitive performance in super-resolution (SR) for natural images by learning mappings from low-resolution (LR) to high-resolution (HR) images. However, hyperspectral super-resolution remains an ill-posed problem due to the high spectral dimensionality of the data and the scarcity of available training samples. Moreover, existing methods often rely on large models with a high number of parameters or require the fusion with panchromatic or RGB images, both of which are often impractical in real-world scenarios. Inspired by the MobileNet architecture, we introduce a lightweight depthwise separable dilated convolutional network (DSDCN) to address the aforementioned challenges. Specifically, our model leverages multiple depthwise separable convolutions, similar to the MobileNet architecture, and further incorporates a dilated convolution fusion block to make the model more flexible for the extraction of both spatial and spectral features. In addition, we propose a custom loss function that combines mean squared error (MSE), an L2 norm regularization-based constraint, and a spectral angle-based loss, ensuring the preservation of both spectral and spatial details. The proposed model achieves very competitive performance on two publicly available hyperspectral datasets, making it well-suited for hyperspectral image super-resolution tasks. The source codes are publicly available at: \href{https://github.com/Usman1021/lightweight}{https://github.com/Usman1021/lightweight}.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
CAMEL-Bench: A Comprehensive Arabic LMM Benchmark
Oct 24, 2024Recent years have witnessed a significant interest in developing large multimodal models (LMMs) capable of performing various visual reasoning and understanding tasks. This has led to the introduction of multiple LMM benchmarks to evaluate LMMs on different tasks. However, most existing LMM evaluation benchmarks are predominantly English-centric. In this work, we develop a comprehensive LMM evaluation benchmark for the Arabic language to represent a large population of over 400 million speakers. The proposed benchmark, named CAMEL-Bench, comprises eight diverse domains and 38 sub-domains including, multi-image understanding, complex visual perception, handwritten document understanding, video understanding, medical imaging, plant diseases, and remote sensing-based land use understanding to evaluate broad scenario generalizability. Our CAMEL-Bench comprises around 29,036 questions that are filtered from a larger pool of samples, where the quality is manually verified by native speakers to ensure reliable model assessment. We conduct evaluations of both closed-source, including GPT-4 series, and open-source LMMs. Our analysis reveals the need for substantial improvement, especially among the best open-source models, with even the closed-source GPT-4o achieving an overall score of 62%. Our benchmark and evaluation scripts are open-sourced.