 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Calibrating Prompt Tuning of Vision-Language Models
Feb 22, 2026Prompt tuning of large-scale vision-language models such as CLIP enables efficient task adaptation without updating model weights. However, it often leads to poor confidence calibration and unreliable predictive uncertainty. We address this problem by proposing a calibration framework that enhances predictive reliability while preserving the geometry of the pretrained CLIP embedding space, which is required for robust generalization. Our approach extends the standard cross-entropy loss with two complementary regularizers: (1) a mean-variance margin penalty that stabilizes inter-class logit margins by maximizing their average while minimizing dispersion, mitigating underconfidence and overconfidence spikes; and (2) a text moment-matching loss that aligns the first and second moments of tuned text embeddings with their frozen CLIP counterparts, preserving semantic dispersion crucial for generalization. Through extensive experiments across 7 prompt-tuning methods and 11 diverse datasets, we demonstrate that our approach significantly reduces the Expected Calibration Error (ECE) compared to competitive calibration techniques on both base and novel classes
OpenEarthAgent: A Unified Framework for Tool-Augmented Geospatial Agents
Feb 19, 2026Recent progress in multimodal reasoning has enabled agents that can interpret imagery, connect it with language, and perform structured analytical tasks. Extending such capabilities to the remote sensing domain remains challenging, as models must reason over spatial scale, geographic structures, and multispectral indices while maintaining coherent multi-step logic. To bridge this gap, OpenEarthAgent introduces a unified framework for developing tool-augmented geospatial agents trained on satellite imagery, natural-language queries, and detailed reasoning traces. The training pipeline relies on supervised fine-tuning over structured reasoning trajectories, aligning the model with verified multistep tool interactions across diverse analytical contexts. The accompanying corpus comprises 14,538 training and 1,169 evaluation instances, with more than 100K reasoning steps in the training split and over 7K reasoning steps in the evaluation split. It spans urban, environmental, disaster, and infrastructure domains, and incorporates GIS-based operations alongside index analyses such as NDVI, NBR, and NDBI. Grounded in explicit reasoning traces, the learned agent demonstrates structured reasoning, stable spatial understanding, and interpretable behaviour through tool-driven geospatial interactions across diverse conditions. We report consistent improvements over a strong baseline and competitive performance relative to recent open and closed-source models.
TerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation
Jun 06, 2025Modern Earth observation (EO) increasingly leverages deep learning to harness the scale and diversity of satellite imagery across sensors and regions. While recent foundation models have demonstrated promising generalization across EO tasks, many remain limited by the scale, geographical coverage, and spectral diversity of their training data, factors critical for learning globally transferable representations. In this work, we introduce TerraFM, a scalable self-supervised learning model that leverages globally distributed Sentinel-1 and Sentinel-2 imagery, combined with large spatial tiles and land-cover aware sampling to enrich spatial and semantic coverage. By treating sensing modalities as natural augmentations in our self-supervised approach, we unify radar and optical inputs via modality-specific patch embeddings and adaptive cross-attention fusion. Our training strategy integrates local-global contrastive learning and introduces a dual-centering mechanism that incorporates class-frequency-aware regularization to address long-tailed distributions in land cover.TerraFM achieves strong generalization on both classification and segmentation tasks, outperforming prior models on GEO-Bench and Copernicus-Bench. Our code and pretrained models are publicly available at: https://github.com/mbzuai-oryx/TerraFM .
ThinkGeo: Evaluating Tool-Augmented Agents for Remote Sensing Tasks
May 29, 2025



Recent progress in large language models (LLMs) has enabled tool-augmented agents capable of solving complex real-world tasks through step-by-step reasoning. However, existing evaluations often focus on general-purpose or multimodal scenarios, leaving a gap in domain-specific benchmarks that assess tool-use capabilities in complex remote sensing use cases. We present ThinkGeo, an agentic benchmark designed to evaluate LLM-driven agents on remote sensing tasks via structured tool use and multi-step planning. Inspired by tool-interaction paradigms, ThinkGeo includes human-curated queries spanning a wide range of real-world applications such as urban planning, disaster assessment and change analysis, environmental monitoring, transportation analysis, aviation monitoring, recreational infrastructure, and industrial site analysis. Each query is grounded in satellite or aerial imagery and requires agents to reason through a diverse toolset. We implement a ReAct-style interaction loop and evaluate both open and closed-source LLMs (e.g., GPT-4o, Qwen2.5) on 436 structured agentic tasks. The benchmark reports both step-wise execution metrics and final answer correctness. Our analysis reveals notable disparities in tool accuracy and planning consistency across models. ThinkGeo provides the first extensive testbed for evaluating how tool-enabled LLMs handle spatial reasoning in remote sensing. Our code and dataset are publicly available
O-TPT: Orthogonality Constraints for Calibrating Test-time Prompt Tuning in Vision-Language Models
Mar 15, 2025Test-time prompt tuning for vision-language models (VLMs) is getting attention because of their ability to learn with unlabeled data without fine-tuning. Although test-time prompt tuning methods for VLMs can boost accuracy, the resulting models tend to demonstrate poor calibration, which casts doubts on the reliability and trustworthiness of these models. Notably, more attention needs to be devoted to calibrating the test-time prompt tuning in vision-language models. To this end, we propose a new approach, called O-TPT that introduces orthogonality constraints on the textual features corresponding to the learnable prompts for calibrating test-time prompt tuning in VLMs. Towards introducing orthogonality constraints, we make the following contributions. First, we uncover new insights behind the suboptimal calibration performance of existing methods relying on textual feature dispersion. Second, we show that imposing a simple orthogonalization of textual features is a more effective approach towards obtaining textual dispersion. We conduct extensive experiments on various datasets with different backbones and baselines. The results indicate that our method consistently outperforms the prior state of the art in significantly reducing the overall average calibration error. Also, our method surpasses the zero-shot calibration performance on fine-grained classification tasks.
AirCast: Improving Air Pollution Forecasting Through Multi-Variable Data Alignment
Feb 25, 2025



Air pollution remains a leading global health risk, exacerbated by rapid industrialization and urbanization, contributing significantly to morbidity and mortality rates. In this paper, we introduce AirCast, a novel multi-variable air pollution forecasting model, by combining weather and air quality variables. AirCast employs a multi-task head architecture that simultaneously forecasts atmospheric conditions and pollutant concentrations, improving its understanding of how weather patterns affect air quality. Predicting extreme pollution events is challenging due to their rare occurrence in historic data, resulting in a heavy-tailed distribution of pollution levels. To address this, we propose a novel Frequency-weighted Mean Absolute Error (fMAE) loss, adapted from the class-balanced loss for regression tasks. Informed from domain knowledge, we investigate the selection of key variables known to influence pollution levels. Additionally, we align existing weather and chemical datasets across spatial and temporal dimensions. AirCast's integrated approach, combining multi-task learning, frequency weighted loss and domain informed variable selection, enables more accurate pollution forecasts. Our source code and models are made public here (https://github.com/vishalned/AirCast.git)
EarthDial: Turning Multi-sensory Earth Observations to Interactive Dialogues
Dec 19, 2024



Automated analysis of vast Earth observation data via interactive Vision-Language Models (VLMs) can unlock new opportunities for environmental monitoring, disaster response, and resource management. Existing generic VLMs do not perform well on Remote Sensing data, while the recent Geo-spatial VLMs remain restricted to a fixed resolution and few sensor modalities. In this paper, we introduce EarthDial, a conversational assistant specifically designed for Earth Observation (EO) data, transforming complex, multi-sensory Earth observations into interactive, natural language dialogues. EarthDial supports multi-spectral, multi-temporal, and multi-resolution imagery, enabling a wide range of remote sensing tasks, including classification, detection, captioning, question answering, visual reasoning, and visual grounding. To achieve this, we introduce an extensive instruction tuning dataset comprising over 11.11M instruction pairs covering RGB, Synthetic Aperture Radar (SAR), and multispectral modalities such as Near-Infrared (NIR) and infrared. Furthermore, EarthDial handles bi-temporal and multi-temporal sequence analysis for applications like change detection. Our extensive experimental results on 37 downstream applications demonstrate that EarthDial outperforms existing generic and domain-specific models, achieving better generalization across various EO tasks.
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks
Nov 28, 2024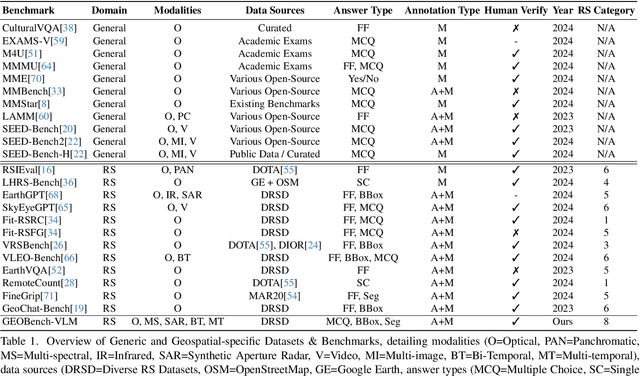
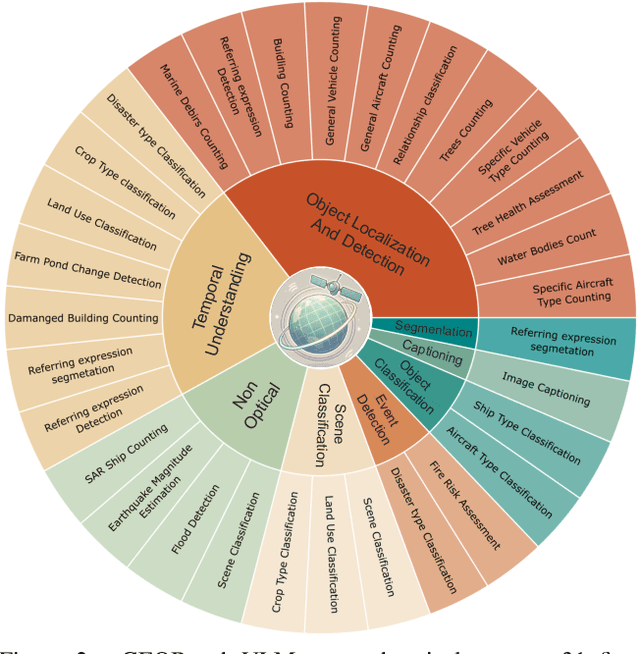
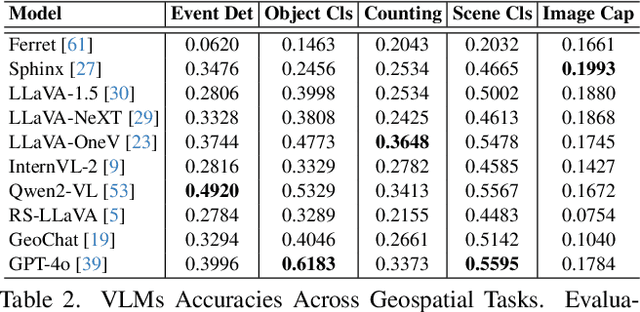
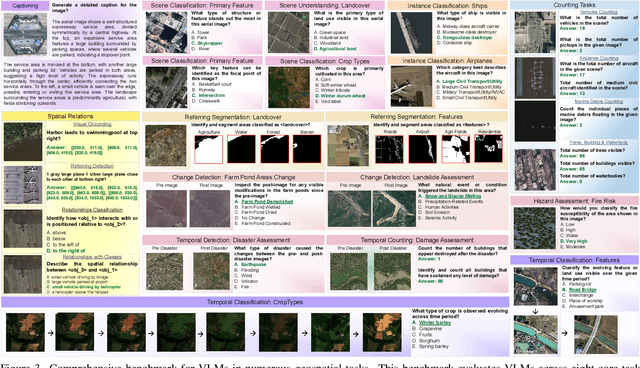
While numerous recent benchmarks focus on evaluating generic Vision-Language Models (VLMs), they fall short in addressing the unique demands of geospatial applications. Generic VLM benchmarks are not designed to handle the complexities of geospatial data, which is critical for applications such as environmental monitoring, urban planning, and disaster management. Some of the unique challenges in geospatial domain include temporal analysis for changes, counting objects in large quantities, detecting tiny objects, and understanding relationships between entities occurring in Remote Sensing imagery. To address this gap in the geospatial domain, we present GEOBench-VLM, a comprehensive benchmark specifically designed to evaluate VLMs on geospatial tasks, including scene understanding, object counting, localization, fine-grained categorization, and temporal analysis. Our benchmark features over 10,000 manually verified instructions and covers a diverse set of variations in visual conditions, object type, and scale. We evaluate several state-of-the-art VLMs to assess their accuracy within the geospatial context. The results indicate that although existing VLMs demonstrate potential, they face challenges when dealing with geospatial-specific examples, highlighting the room for further improvements. Specifically, the best-performing GPT4o achieves only 40\% accuracy on MCQs, which is only double the random guess performance. Our benchmark is publicly available at https://github.com/The-AI-Alliance/GEO-Bench-VLM .
Efficient Localized Adaptation of Neural Weather Forecasting: A Case Study in the MENA Region
Sep 11, 2024Accurate weather and climate modeling is critical for both scientific advancement and safeguarding communities against environmental risks. Traditional approaches rely heavily on Numerical Weather Prediction (NWP) models, which simulate energy and matter flow across Earth's systems. However, heavy computational requirements and low efficiency restrict the suitability of NWP, leading to a pressing need for enhanced modeling techniques. Neural network-based models have emerged as promising alternatives, leveraging data-driven approaches to forecast atmospheric variables. In this work, we focus on limited-area modeling and train our model specifically for localized region-level downstream tasks. As a case study, we consider the MENA region due to its unique climatic challenges, where accurate localized weather forecasting is crucial for managing water resources, agriculture and mitigating the impacts of extreme weather events. This targeted approach allows us to tailor the model's capabilities to the unique conditions of the region of interest. Our study aims to validate the effectiveness of integrating parameter-efficient fine-tuning (PEFT) methodologies, specifically Low-Rank Adaptation (LoRA) and its variants, to enhance forecast accuracy, as well as training speed, computational resource utilization, and memory efficiency in weather and climate modeling for specific regions.
Improving Single Domain-Generalized Object Detection: A Focus on Diversification and Alignment
May 23, 2024



In this work, we tackle the problem of domain generalization for object detection, specifically focusing on the scenario where only a single source domain is available. We propose an effective approach that involves two key steps: diversifying the source domain and aligning detections based on class prediction confidence and localization. Firstly, we demonstrate that by carefully selecting a set of augmentations, a base detector can outperform existing methods for single domain generalization by a good margin. This highlights the importance of domain diversification in improving the performance of object detectors. Secondly, we introduce a method to align detections from multiple views, considering both classification and localization outputs. This alignment procedure leads to better generalized and well-calibrated object detector models, which are crucial for accurate decision-making in safety-critical applications. Our approach is detector-agnostic and can be seamlessly applied to both single-stage and two-stage detectors. To validate the effectiveness of our proposed methods, we conduct extensive experiments and ablations on challenging domain-shift scenarios. The results consistently demonstrate the superiority of our approach compared to existing methods. Our code and models are available at: https://github.com/msohaildanish/DivAlign