 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation
Jun 06, 2025Modern Earth observation (EO) increasingly leverages deep learning to harness the scale and diversity of satellite imagery across sensors and regions. While recent foundation models have demonstrated promising generalization across EO tasks, many remain limited by the scale, geographical coverage, and spectral diversity of their training data, factors critical for learning globally transferable representations. In this work, we introduce TerraFM, a scalable self-supervised learning model that leverages globally distributed Sentinel-1 and Sentinel-2 imagery, combined with large spatial tiles and land-cover aware sampling to enrich spatial and semantic coverage. By treating sensing modalities as natural augmentations in our self-supervised approach, we unify radar and optical inputs via modality-specific patch embeddings and adaptive cross-attention fusion. Our training strategy integrates local-global contrastive learning and introduces a dual-centering mechanism that incorporates class-frequency-aware regularization to address long-tailed distributions in land cover.TerraFM achieves strong generalization on both classification and segmentation tasks, outperforming prior models on GEO-Bench and Copernicus-Bench. Our code and pretrained models are publicly available at: https://github.com/mbzuai-oryx/TerraFM .
EarthDial: Turning Multi-sensory Earth Observations to Interactive Dialogues
Dec 19, 2024



Automated analysis of vast Earth observation data via interactive Vision-Language Models (VLMs) can unlock new opportunities for environmental monitoring, disaster response, and resource management. Existing generic VLMs do not perform well on Remote Sensing data, while the recent Geo-spatial VLMs remain restricted to a fixed resolution and few sensor modalities. In this paper, we introduce EarthDial, a conversational assistant specifically designed for Earth Observation (EO) data, transforming complex, multi-sensory Earth observations into interactive, natural language dialogues. EarthDial supports multi-spectral, multi-temporal, and multi-resolution imagery, enabling a wide range of remote sensing tasks, including classification, detection, captioning, question answering, visual reasoning, and visual grounding. To achieve this, we introduce an extensive instruction tuning dataset comprising over 11.11M instruction pairs covering RGB, Synthetic Aperture Radar (SAR), and multispectral modalities such as Near-Infrared (NIR) and infrared. Furthermore, EarthDial handles bi-temporal and multi-temporal sequence analysis for applications like change detection. Our extensive experimental results on 37 downstream applications demonstrate that EarthDial outperforms existing generic and domain-specific models, achieving better generalization across various EO tasks.
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks
Nov 28, 2024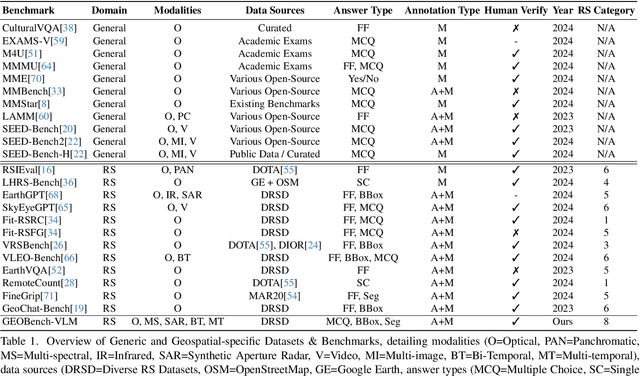
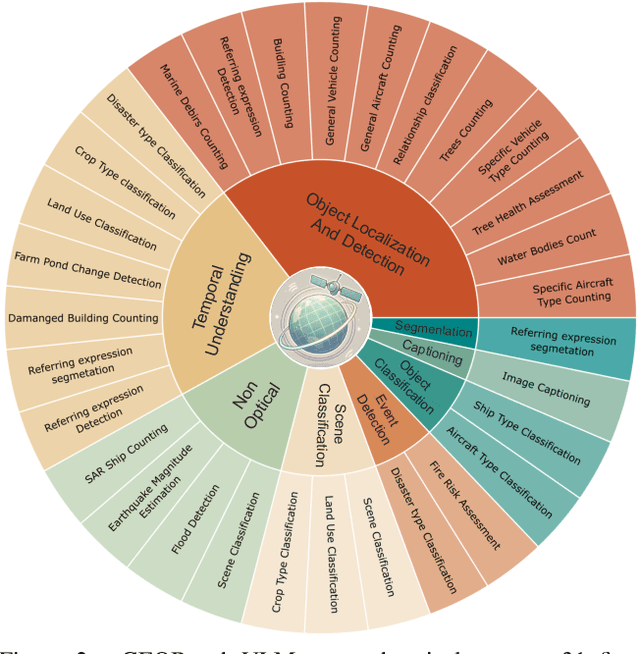
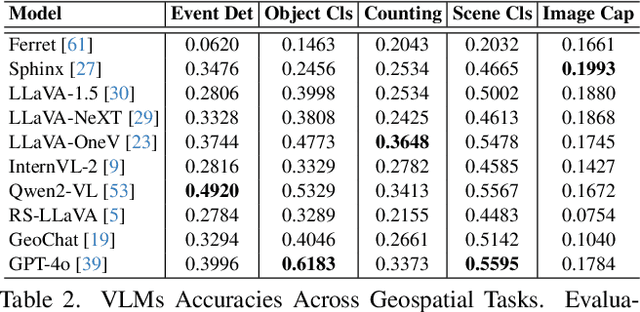
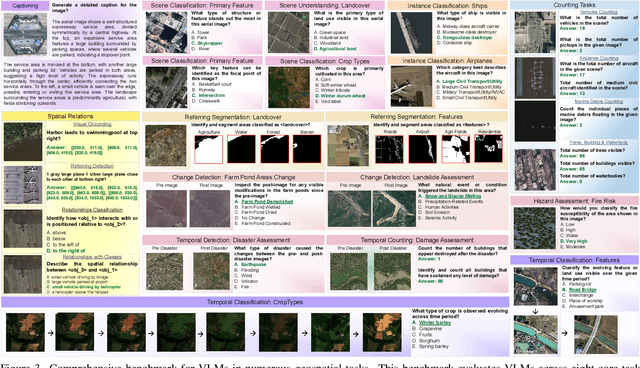
While numerous recent benchmarks focus on evaluating generic Vision-Language Models (VLMs), they fall short in addressing the unique demands of geospatial applications. Generic VLM benchmarks are not designed to handle the complexities of geospatial data, which is critical for applications such as environmental monitoring, urban planning, and disaster management. Some of the unique challenges in geospatial domain include temporal analysis for changes, counting objects in large quantities, detecting tiny objects, and understanding relationships between entities occurring in Remote Sensing imagery. To address this gap in the geospatial domain, we present GEOBench-VLM, a comprehensive benchmark specifically designed to evaluate VLMs on geospatial tasks, including scene understanding, object counting, localization, fine-grained categorization, and temporal analysis. Our benchmark features over 10,000 manually verified instructions and covers a diverse set of variations in visual conditions, object type, and scale. We evaluate several state-of-the-art VLMs to assess their accuracy within the geospatial context. The results indicate that although existing VLMs demonstrate potential, they face challenges when dealing with geospatial-specific examples, highlighting the room for further improvements. Specifically, the best-performing GPT4o achieves only 40\% accuracy on MCQs, which is only double the random guess performance. Our benchmark is publicly available at https://github.com/The-AI-Alliance/GEO-Bench-VLM .
Improving Single Domain-Generalized Object Detection: A Focus on Diversification and Alignment
May 23, 2024



In this work, we tackle the problem of domain generalization for object detection, specifically focusing on the scenario where only a single source domain is available. We propose an effective approach that involves two key steps: diversifying the source domain and aligning detections based on class prediction confidence and localization. Firstly, we demonstrate that by carefully selecting a set of augmentations, a base detector can outperform existing methods for single domain generalization by a good margin. This highlights the importance of domain diversification in improving the performance of object detectors. Secondly, we introduce a method to align detections from multiple views, considering both classification and localization outputs. This alignment procedure leads to better generalized and well-calibrated object detector models, which are crucial for accurate decision-making in safety-critical applications. Our approach is detector-agnostic and can be seamlessly applied to both single-stage and two-stage detectors. To validate the effectiveness of our proposed methods, we conduct extensive experiments and ablations on challenging domain-shift scenarios. The results consistently demonstrate the superiority of our approach compared to existing methods. Our code and models are available at: https://github.com/msohaildanish/DivAlign
GeoChat: Grounded Large Vision-Language Model for Remote Sensing
Nov 24, 2023Recent advancements in Large Vision-Language Models (VLMs) have shown great promise in natural image domains, allowing users to hold a dialogue about given visual content. However, such general-domain VLMs perform poorly for Remote Sensing (RS) scenarios, leading to inaccurate or fabricated information when presented with RS domain-specific queries. Such a behavior emerges due to the unique challenges introduced by RS imagery. For example, to handle high-resolution RS imagery with diverse scale changes across categories and many small objects, region-level reasoning is necessary alongside holistic scene interpretation. Furthermore, the lack of domain-specific multimodal instruction following data as well as strong backbone models for RS make it hard for the models to align their behavior with user queries. To address these limitations, we propose GeoChat - the first versatile remote sensing VLM that offers multitask conversational capabilities with high-resolution RS images. Specifically, GeoChat can not only answer image-level queries but also accepts region inputs to hold region-specific dialogue. Furthermore, it can visually ground objects in its responses by referring to their spatial coordinates. To address the lack of domain-specific datasets, we generate a novel RS multimodal instruction-following dataset by extending image-text pairs from existing diverse RS datasets. We establish a comprehensive benchmark for RS multitask conversations and compare with a number of baseline methods. GeoChat demonstrates robust zero-shot performance on various RS tasks, e.g., image and region captioning, visual question answering, scene classification, visually grounded conversations and referring detection. Our code is available at https://github.com/mbzuai-oryx/geochat.
Towards Low-Cost and Efficient Malaria Detection
Nov 26, 2021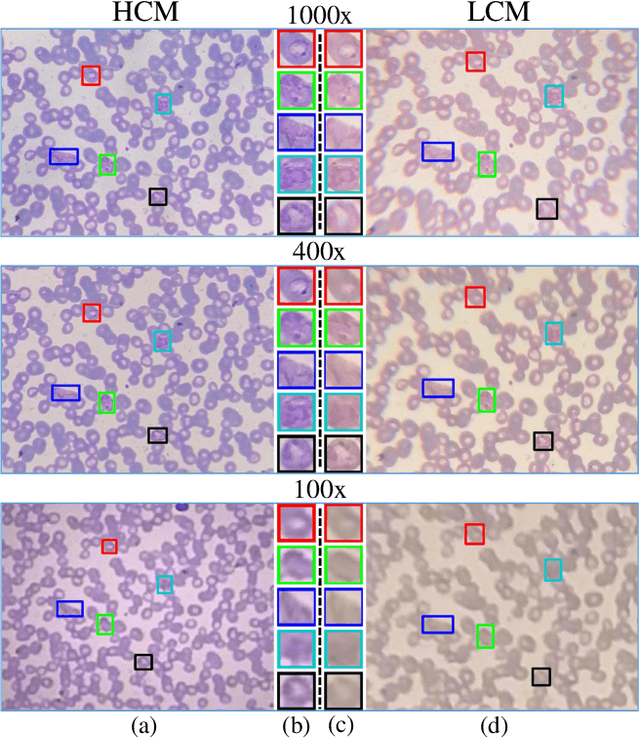
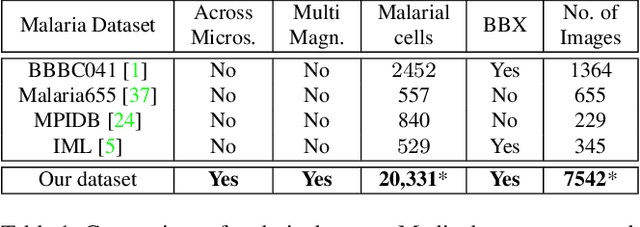
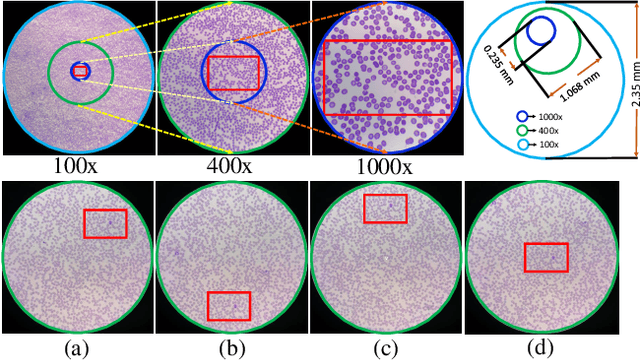

Malaria, a fatal but curable disease claims hundreds of thousands of lives every year. Early and correct diagnosis is vital to avoid health complexities, however, it depends upon the availability of costly microscopes and trained experts to analyze blood-smear slides. Deep learning-based methods have the potential to not only decrease the burden of experts but also improve diagnostic accuracy on low-cost microscopes. However, this is hampered by the absence of a reasonable size dataset. One of the most challenging aspects is the reluctance of the experts to annotate the dataset at low magnification on low-cost microscopes. We present a dataset to further the research on malaria microscopy over the low-cost microscopes at low magnification. Our large-scale dataset consists of images of blood-smear slides from several malaria-infected patients, collected through microscopes at two different cost spectrums and multiple magnifications. Malarial cells are annotated for the localization and life-stage classification task on the images collected through the high-cost microscope at high magnification. We design a mechanism to transfer these annotations from the high-cost microscope at high magnification to the low-cost microscope, at multiple magnifications. Multiple object detectors and domain adaptation methods are presented as the baselines. Furthermore, a partially supervised domain adaptation method is introduced to adapt the object-detector to work on the images collected from the low-cost microscope. The dataset will be made publicly available after publication.