 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentBeats: Agentifying Agent Assessment for Openness, Standardization, and Reproducibility
Jun 11, 2026Agent systems are advancing quickly across domains, but their evaluation remains fragmented. Most benchmarks rely on fixed, LLM-centric harnesses that require heavy integration, create test-production mismatch, and limit fair comparison across diverse agent designs. The root problem is the lack of an open, agent-agnostic assessment interface. We advocate Agentified Agent Assessment (AAA), where evaluation is performed by judge agents and all participants interact through standardized protocols: A2A for task management and MCP for tool access. Conventional benchmarking defines two separate interfaces, one for the benchmark and one for the agent, while AAA only needs one; this yields a generic, unified framework that separates assessment logic from agent implementation and enables reproducible, interoperable, and multi-agent evaluation. We further introduce AgentBeats as a concrete realization of AAA: we identify five practical operation modes that make standardized assessment compatible with real-world constraints on openness, privacy, and reproducibility. To evaluate our design at scale, we conduct two studies: a five-month open competition that drew 298 judge agents across 12 categories together with 467 subject agents from independent participants, showing that AAA applies across a heterogeneous range of benchmarks; and a case study on coding agents that confirms agentified evaluation preserves fidelity with the public record while surfacing previously missing head-to-head results, yielding research insights about agent design. Combining a community-scale field study and a controlled coding case study, we verify that AAA delivers coverage, practicality, and fidelity across heterogeneous scenarios at scale. Together, AAA and AgentBeats offer a clear path toward open, standardized, and reproducible agent assessment.
Mem-$π$: Adaptive Memory through Learning When and What to Generate
May 20, 2026We present Mem-$π$, a framework for adaptive memory in large language model (LLM) agents, where useful guidance is generated on demand rather than retrieved from external memory stores. Existing memory-augmented agents typically rely on similarity-based retrieval from episodic memory banks or skill libraries, returning static entries that often misalign with the current context. In contrast, Mem-$π$ uses a dedicated language or vision-language model with its own parameters, separate from the downstream agent, to generate context-specific guidance for complex tasks. Conditioned on the current agent context, the model jointly decides when to produce guidance and what guidance to produce. We train it with a decision-content decoupled reinforcement learning (RL) objective, enabling it to abstain when generation would not help and otherwise produce concise, useful guidance. Across diverse agentic benchmarks spanning web navigation, terminal-based tool use, and text-based embodied interaction, Mem-$π$ consistently outperforms retrieval-based and prior RL-optimized memory baselines, achieving over 30% relative improvement on web navigation tasks.
Knowing When Not to Answer: Evaluating Abstention in Multimodal Reasoning Systems
Apr 16, 2026Effective abstention (EA), recognizing evidence insufficiency and refraining from answering, is critical for reliable multimodal systems. Yet existing evaluation paradigms for vision-language models (VLMs) and multi-agent systems (MAS) assume answerability, pushing models to always respond. Abstention has been studied in text-only settings but remains underexplored multimodally; current benchmarks either ignore unanswerability or rely on coarse methods that miss realistic failure modes. We introduce MM-AQA, a benchmark that constructs unanswerable instances from answerable ones via transformations along two axes: visual modality dependency and evidence sufficiency. Evaluating three frontier VLMs spanning closed and open-source models and two MAS architectures across 2079 samples, we find: (1) under standard prompting, VLMs rarely abstain; even simple confidence baselines outperform this setup, (2) MAS improves abstention but introduces an accuracy-abstention trade-off, (3) sequential designs match or exceed iterative variants, suggesting the bottleneck is miscalibration rather than reasoning depth, and (4) models abstain when image or text evidence is absent, but attempt reconciliation with degraded or contradictory evidence. Effective multimodal abstention requires abstention-aware training rather than better prompting or more agents.
CUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
Privileged Information Distillation for Language Models
Feb 04, 2026Training-time privileged information (PI) can enable language models to succeed on tasks they would otherwise fail, making it a powerful tool for reinforcement learning in hard, long-horizon settings. However, transferring capabilities learned with PI to policies that must act without it at inference time remains a fundamental challenge. We study this problem in the context of distilling frontier models for multi-turn agentic environments, where closed-source systems typically hide their internal reasoning and expose only action trajectories. This breaks standard distillation pipelines, since successful behavior is observable but the reasoning process is not. For this, we introduce π-Distill, a joint teacher-student objective that trains a PI-conditioned teacher and an unconditioned student simultaneously using the same model. Additionally, we also introduce On-Policy Self-Distillation (OPSD), an alternative approach that trains using Reinforcement Learning (RL) with a reverse KL-penalty between the student and the PI-conditioned teacher. We show that both of these algorithms effectively distill frontier agents using action-only PI. Specifically we find that π-Distill and in some cases OPSD, outperform industry standard practices (Supervised finetuning followed by RL) that assume access to full Chain-of-Thought supervision across multiple agentic benchmarks, models, and forms of PI. We complement our results with extensive analysis that characterizes the factors enabling effective learning with PI, focusing primarily on π-Distill and characterizing when OPSD is competitive.
Just-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Oct 05, 2025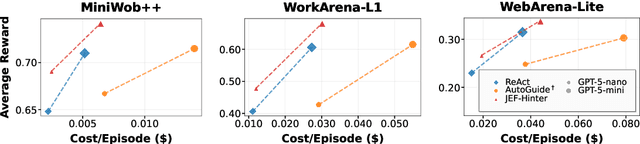
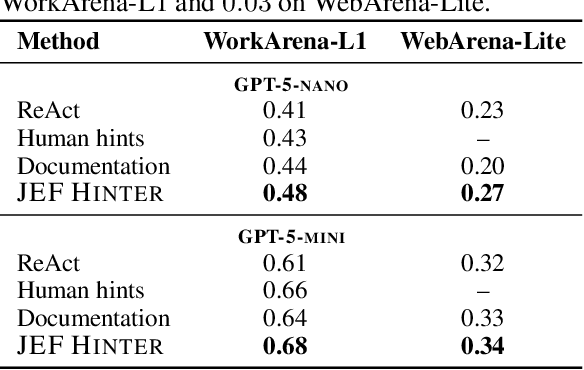
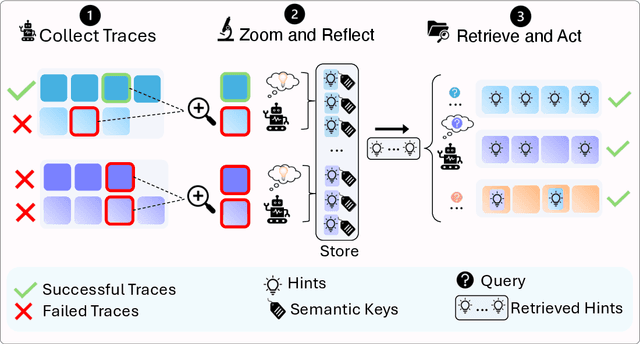
Large language model (LLM) agents perform well in sequential decision-making tasks, but improving them on unfamiliar domains often requires costly online interactions or fine-tuning on large expert datasets. These strategies are impractical for closed-source models and expensive for open-source ones, with risks of catastrophic forgetting. Offline trajectories offer reusable knowledge, yet demonstration-based methods struggle because raw traces are long, noisy, and tied to specific tasks. We present Just-in-time Episodic Feedback Hinter (JEF Hinter), an agentic system that distills offline traces into compact, context-aware hints. A zooming mechanism highlights decisive steps in long trajectories, capturing both strategies and pitfalls. Unlike prior methods, JEF Hinter leverages both successful and failed trajectories, extracting guidance even when only failure data is available, while supporting parallelized hint generation and benchmark-independent prompting. At inference, a retriever selects relevant hints for the current state, providing targeted guidance with transparency and traceability. Experiments on MiniWoB++, WorkArena-L1, and WebArena-Lite show that JEF Hinter consistently outperforms strong baselines, including human- and document-based hints.
EarthView: A Large Scale Remote Sensing Dataset for Self-Supervision
Jan 14, 2025This paper presents EarthView, a comprehensive dataset specifically designed for self-supervision on remote sensing data, intended to enhance deep learning applications on Earth monitoring tasks. The dataset spans 15 tera pixels of global remote-sensing data, combining imagery from a diverse range of sources, including NEON, Sentinel, and a novel release of 1m spatial resolution data from Satellogic. Our dataset provides a wide spectrum of image data with varying resolutions, harnessed from different sensors and organized coherently into an accessible HuggingFace dataset in parquet format. This data spans five years, from 2017 to 2022. Accompanying the dataset, we introduce EarthMAE, a tailored Masked Autoencoder, developed to tackle the distinct challenges of remote sensing data. Trained in a self-supervised fashion, EarthMAE effectively processes different data modalities such as hyperspectral, multispectral, topographical data, segmentation maps, and temporal structure. This model helps us show that pre-training on Satellogic data improves performance on downstream tasks. While there is still a gap to fill in MAE for heterogeneous data, we regard this innovative combination of an expansive, diverse dataset and a versatile model adapted for self-supervised learning as a stride forward in deep learning for Earth monitoring.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks
Nov 28, 2024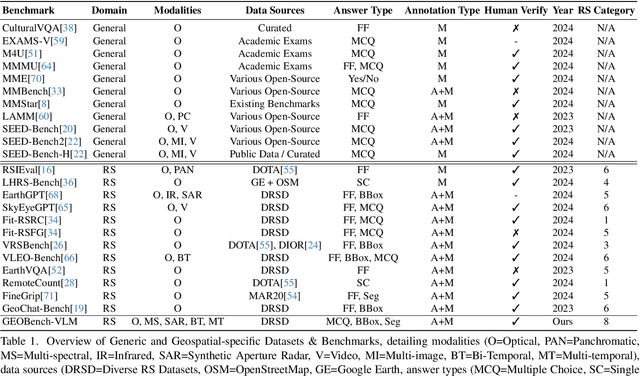
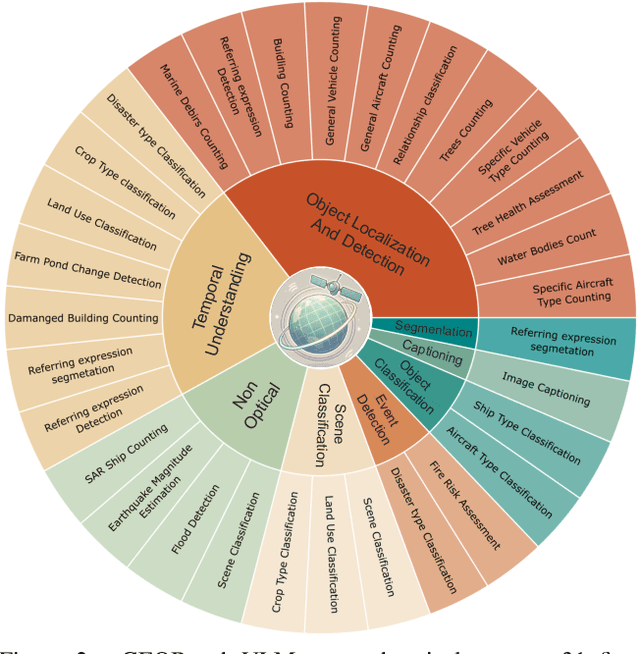
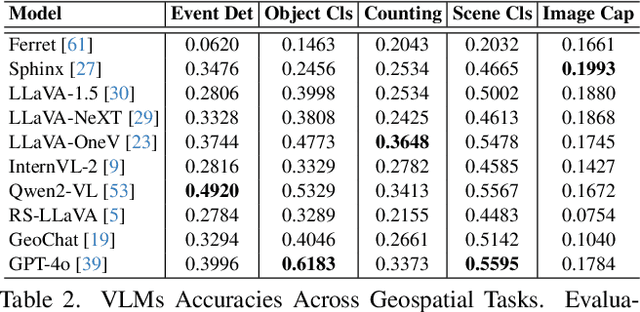
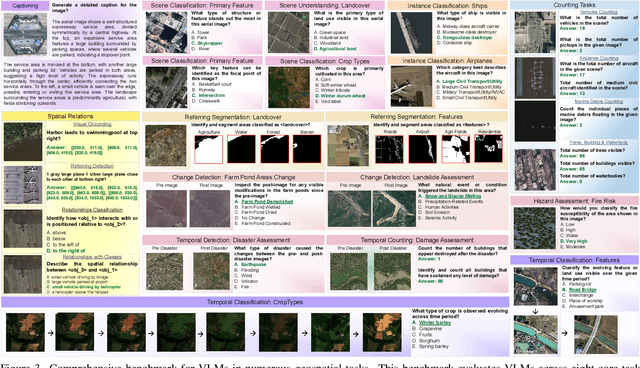
While numerous recent benchmarks focus on evaluating generic Vision-Language Models (VLMs), they fall short in addressing the unique demands of geospatial applications. Generic VLM benchmarks are not designed to handle the complexities of geospatial data, which is critical for applications such as environmental monitoring, urban planning, and disaster management. Some of the unique challenges in geospatial domain include temporal analysis for changes, counting objects in large quantities, detecting tiny objects, and understanding relationships between entities occurring in Remote Sensing imagery. To address this gap in the geospatial domain, we present GEOBench-VLM, a comprehensive benchmark specifically designed to evaluate VLMs on geospatial tasks, including scene understanding, object counting, localization, fine-grained categorization, and temporal analysis. Our benchmark features over 10,000 manually verified instructions and covers a diverse set of variations in visual conditions, object type, and scale. We evaluate several state-of-the-art VLMs to assess their accuracy within the geospatial context. The results indicate that although existing VLMs demonstrate potential, they face challenges when dealing with geospatial-specific examples, highlighting the room for further improvements. Specifically, the best-performing GPT4o achieves only 40\% accuracy on MCQs, which is only double the random guess performance. Our benchmark is publicly available at https://github.com/The-AI-Alliance/GEO-Bench-VLM .
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .