 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogarithmic-time Schedules for Scaling Language Models with Momentum
Feb 05, 2026In practice, the hyperparameters $(β_1, β_2)$ and weight-decay $λ$ in AdamW are typically kept at fixed values. Is there any reason to do otherwise? We show that for large-scale language model training, the answer is yes: by exploiting the power-law structure of language data, one can design time-varying schedules for $(β_1, β_2, λ)$ that deliver substantial performance gains. We study logarithmic-time scheduling, in which the optimizer's gradient memory horizon grows with training time. Although naive variants of this are unstable, we show that suitable damping mechanisms restore stability while preserving the benefits of longer memory. Based on this, we present ADANA, an AdamW-like optimizer that couples log-time schedules with explicit damping to balance stability and performance. We empirically evaluate ADANA across transformer scalings (45M to 2.6B parameters), comparing against AdamW, Muon, and AdEMAMix. When properly tuned, ADANA achieves up to 40% compute efficiency relative to a tuned AdamW, with gains that persist--and even improve--as model scale increases. We further show that similar benefits arise when applying logarithmic-time scheduling to AdEMAMix, and that logarithmic-time weight-decay alone can yield significant improvements. Finally, we present variants of ADANA that mitigate potential failure modes and improve robustness.
Dimension-adapted Momentum Outscales SGD
May 22, 2025We investigate scaling laws for stochastic momentum algorithms with small batch on the power law random features model, parameterized by data complexity, target complexity, and model size. When trained with a stochastic momentum algorithm, our analysis reveals four distinct loss curve shapes determined by varying data-target complexities. While traditional stochastic gradient descent with momentum (SGD-M) yields identical scaling law exponents to SGD, dimension-adapted Nesterov acceleration (DANA) improves these exponents by scaling momentum hyperparameters based on model size and data complexity. This outscaling phenomenon, which also improves compute-optimal scaling behavior, is achieved by DANA across a broad range of data and target complexities, while traditional methods fall short. Extensive experiments on high-dimensional synthetic quadratics validate our theoretical predictions and large-scale text experiments with LSTMs show DANA's improved loss exponents over SGD hold in a practical setting.
Scaling Exponents Across Parameterizations and Optimizers
Jul 08, 2024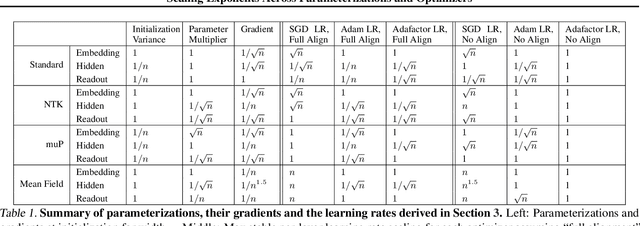



Robust and effective scaling of models from small to large width typically requires the precise adjustment of many algorithmic and architectural details, such as parameterization and optimizer choices. In this work, we propose a new perspective on parameterization by investigating a key assumption in prior work about the alignment between parameters and data and derive new theoretical results under weaker assumptions and a broader set of optimizers. Our extensive empirical investigation includes tens of thousands of models trained with all combinations of three optimizers, four parameterizations, several alignment assumptions, more than a dozen learning rates, and fourteen model sizes up to 26.8B parameters. We find that the best learning rate scaling prescription would often have been excluded by the assumptions in prior work. Our results show that all parameterizations, not just maximal update parameterization (muP), can achieve hyperparameter transfer; moreover, our novel per-layer learning rate prescription for standard parameterization outperforms muP. Finally, we demonstrate that an overlooked aspect of parameterization, the epsilon parameter in Adam, must be scaled correctly to avoid gradient underflow and propose Adam-atan2, a new numerically stable, scale-invariant version of Adam that eliminates the epsilon hyperparameter entirely.
Nonparametric Partial Disentanglement via Mechanism Sparsity: Sparse Actions, Interventions and Sparse Temporal Dependencies
Jan 10, 2024This work introduces a novel principle for disentanglement we call mechanism sparsity regularization, which applies when the latent factors of interest depend sparsely on observed auxiliary variables and/or past latent factors. We propose a representation learning method that induces disentanglement by simultaneously learning the latent factors and the sparse causal graphical model that explains them. We develop a nonparametric identifiability theory that formalizes this principle and shows that the latent factors can be recovered by regularizing the learned causal graph to be sparse. More precisely, we show identifiablity up to a novel equivalence relation we call "consistency", which allows some latent factors to remain entangled (hence the term partial disentanglement). To describe the structure of this entanglement, we introduce the notions of entanglement graphs and graph preserving functions. We further provide a graphical criterion which guarantees complete disentanglement, that is identifiability up to permutations and element-wise transformations. We demonstrate the scope of the mechanism sparsity principle as well as the assumptions it relies on with several worked out examples. For instance, the framework shows how one can leverage multi-node interventions with unknown targets on the latent factors to disentangle them. We further draw connections between our nonparametric results and the now popular exponential family assumption. Lastly, we propose an estimation procedure based on variational autoencoders and a sparsity constraint and demonstrate it on various synthetic datasets. This work is meant to be a significantly extended version of Lachapelle et al. (2022).
Small-scale proxies for large-scale Transformer training instabilities
Sep 25, 2023



Teams that have trained large Transformer-based models have reported training instabilities at large scale that did not appear when training with the same hyperparameters at smaller scales. Although the causes of such instabilities are of scientific interest, the amount of resources required to reproduce them has made investigation difficult. In this work, we seek ways to reproduce and study training stability and instability at smaller scales. First, we focus on two sources of training instability described in previous work: the growth of logits in attention layers (Dehghani et al., 2023) and divergence of the output logits from the log probabilities (Chowdhery et al., 2022). By measuring the relationship between learning rate and loss across scales, we show that these instabilities also appear in small models when training at high learning rates, and that mitigations previously employed at large scales are equally effective in this regime. This prompts us to investigate the extent to which other known optimizer and model interventions influence the sensitivity of the final loss to changes in the learning rate. To this end, we study methods such as warm-up, weight decay, and the $\mu$Param (Yang et al., 2022), and combine techniques to train small models that achieve similar losses across orders of magnitude of learning rate variation. Finally, to conclude our exploration we study two cases where instabilities can be predicted before they emerge by examining the scaling behavior of model activation and gradient norms.
GFlowNet-EM for learning compositional latent variable models
Feb 13, 2023Latent variable models (LVMs) with discrete compositional latents are an important but challenging setting due to a combinatorially large number of possible configurations of the latents. A key tradeoff in modeling the posteriors over latents is between expressivity and tractable optimization. For algorithms based on expectation-maximization (EM), the E-step is often intractable without restrictive approximations to the posterior. We propose the use of GFlowNets, algorithms for sampling from an unnormalized density by learning a stochastic policy for sequential construction of samples, for this intractable E-step. By training GFlowNets to sample from the posterior over latents, we take advantage of their strengths as amortized variational inference algorithms for complex distributions over discrete structures. Our approach, GFlowNet-EM, enables the training of expressive LVMs with discrete compositional latents, as shown by experiments on non-context-free grammar induction and on images using discrete variational autoencoders (VAEs) without conditional independence enforced in the encoder.
GFlowNets and variational inference
Oct 02, 2022
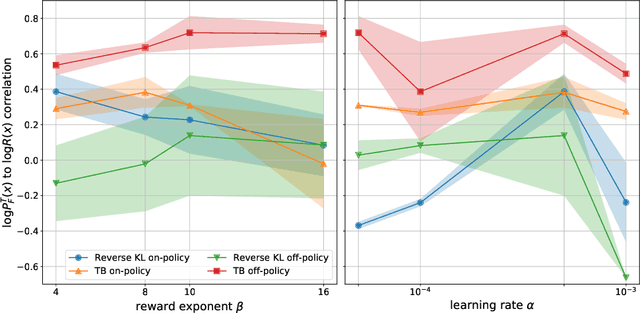
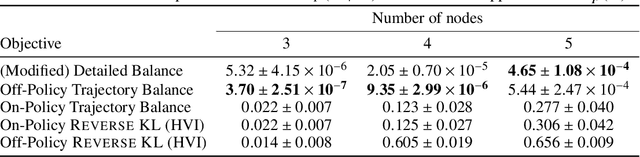

This paper builds bridges between two families of probabilistic algorithms: (hierarchical) variational inference (VI), which is typically used to model distributions over continuous spaces, and generative flow networks (GFlowNets), which have been used for distributions over discrete structures such as graphs. We demonstrate that, in certain cases, VI algorithms are equivalent to special cases of GFlowNets in the sense of equality of expected gradients of their learning objectives. We then point out the differences between the two families and show how these differences emerge experimentally. Notably, GFlowNets, which borrow ideas from reinforcement learning, are more amenable than VI to off-policy training without the cost of high gradient variance induced by importance sampling. We argue that this property of GFlowNets can provide advantages for capturing diversity in multimodal target distributions.
Cycles in Causal Learning
Jul 24, 2020In the causal learning setting, we wish to learn cause-and-effect relationships between variables such that we can correctly infer the effect of an intervention. While the difference between a cyclic structure and an acyclic structure may be just a single edge, cyclic causal structures have qualitatively different behavior under intervention: cycles cause feedback loops when the downstream effect of an intervention propagates back to the source variable. We present three theoretical observations about probability distributions with self-referential factorizations, i.e. distributions that could be graphically represented with a cycle. First, we prove that self-referential distributions in two variables are, in fact, independent. Second, we prove that self-referential distributions in N variables have zero mutual information. Lastly, we prove that self-referential distributions that factorize in a cycle, also factorize as though the cycle were reversed. These results suggest that cyclic causal dependence may exist even where observational data suggest independence among variables. Methods based on estimating mutual information, or heuristics based on independent causal mechanisms, are likely to fail to learn cyclic casual structures. We encourage future work in causal learning that carefully considers cycles.