 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Flow Networks: Theory and Applications to Structure Learning
Jan 09, 2025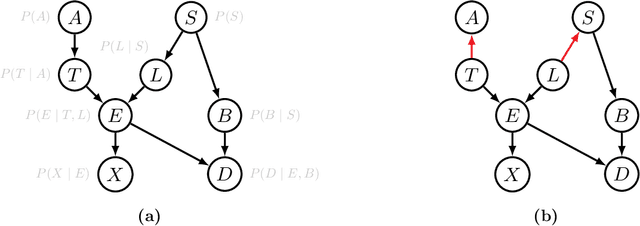
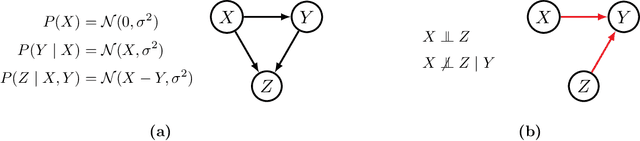
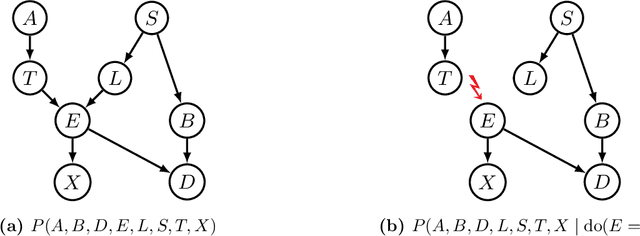
Without any assumptions about data generation, multiple causal models may explain our observations equally well. To avoid selecting a single arbitrary model that could result in unsafe decisions if it does not match reality, it is therefore essential to maintain a notion of epistemic uncertainty about our possible candidates. This thesis studies the problem of structure learning from a Bayesian perspective, approximating the posterior distribution over the structure of a causal model, represented as a directed acyclic graph (DAG), given data. It introduces Generative Flow Networks (GFlowNets), a novel class of probabilistic models designed for modeling distributions over discrete and compositional objects such as graphs. They treat generation as a sequential decision making problem, constructing samples of a target distribution defined up to a normalization constant piece by piece. In the first part of this thesis, we present the mathematical foundations of GFlowNets, their connections to existing domains of machine learning and statistics such as variational inference and reinforcement learning, and their extensions beyond discrete problems. In the second part of this thesis, we show how GFlowNets can approximate the posterior distribution over DAG structures of causal Bayesian Networks, along with the parameters of its causal mechanisms, given observational and experimental data.
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Jul 24, 2024
Gymnasium is an open-source library providing an API for reinforcement learning environments. Its main contribution is a central abstraction for wide interoperability between benchmark environments and training algorithms. Gymnasium comes with various built-in environments and utilities to simplify researchers' work along with being supported by most training libraries. This paper outlines the main design decisions for Gymnasium, its key features, and the differences to alternative APIs.
Discrete Probabilistic Inference as Control in Multi-path Environments
Feb 15, 2024



We consider the problem of sampling from a discrete and structured distribution as a sequential decision problem, where the objective is to find a stochastic policy such that objects are sampled at the end of this sequential process proportionally to some predefined reward. While we could use maximum entropy Reinforcement Learning (MaxEnt RL) to solve this problem for some distributions, it has been shown that in general, the distribution over states induced by the optimal policy may be biased in cases where there are multiple ways to generate the same object. To address this issue, Generative Flow Networks (GFlowNets) learn a stochastic policy that samples objects proportionally to their reward by approximately enforcing a conservation of flows across the whole Markov Decision Process (MDP). In this paper, we extend recent methods correcting the reward in order to guarantee that the marginal distribution induced by the optimal MaxEnt RL policy is proportional to the original reward, regardless of the structure of the underlying MDP. We also prove that some flow-matching objectives found in the GFlowNet literature are in fact equivalent to well-established MaxEnt RL algorithms with a corrected reward. Finally, we study empirically the performance of multiple MaxEnt RL and GFlowNet algorithms on multiple problems involving sampling from discrete distributions.
Benchmarking Bayesian Causal Discovery Methods for Downstream Treatment Effect Estimation
Jul 30, 2023



The practical utility of causality in decision-making is widespread and brought about by the intertwining of causal discovery and causal inference. Nevertheless, a notable gap exists in the evaluation of causal discovery methods, where insufficient emphasis is placed on downstream inference. To address this gap, we evaluate seven established baseline causal discovery methods including a newly proposed method based on GFlowNets, on the downstream task of treatment effect estimation. Through the implementation of a distribution-level evaluation, we offer valuable and unique insights into the efficacy of these causal discovery methods for treatment effect estimation, considering both synthetic and real-world scenarios, as well as low-data scenarios. The results of our study demonstrate that some of the algorithms studied are able to effectively capture a wide range of useful and diverse ATE modes, while some tend to learn many low-probability modes which impacts the (unrelaxed) recall and precision.
Generative Flow Networks: a Markov Chain Perspective
Jul 04, 2023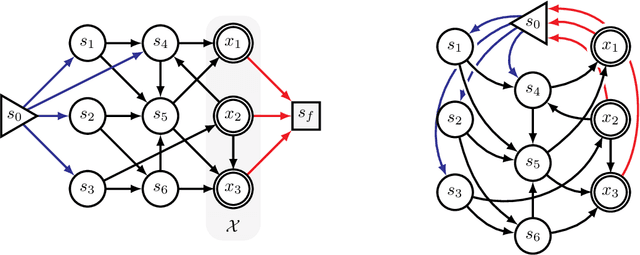

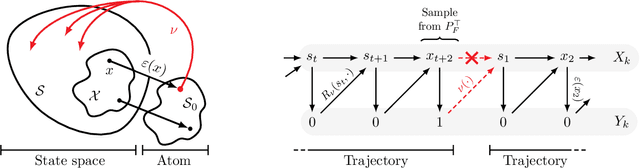
While Markov chain Monte Carlo methods (MCMC) provide a general framework to sample from a probability distribution defined up to normalization, they often suffer from slow convergence to the target distribution when the latter is highly multi-modal. Recently, Generative Flow Networks (GFlowNets) have been proposed as an alternative framework to mitigate this issue when samples have a clear compositional structure, by treating sampling as a sequential decision making problem. Although they were initially introduced from the perspective of flow networks, the recent advances of GFlowNets draw more and more inspiration from the Markov chain literature, bypassing completely the need for flows. In this paper, we formalize this connection and offer a new perspective for GFlowNets using Markov chains, showing a unifying view for GFlowNets regardless of the nature of the state space as recurrent Markov chains. Positioning GFlowNets under the same theoretical framework as MCMC methods also allows us to identify the similarities between both frameworks, and most importantly to highlight their
BatchGFN: Generative Flow Networks for Batch Active Learning
Jun 26, 2023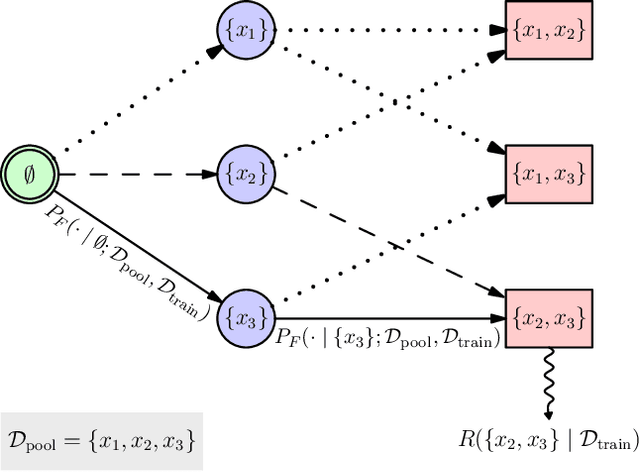
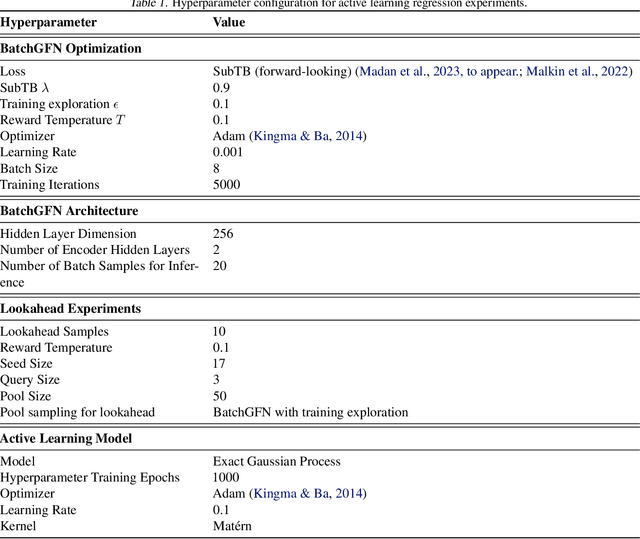
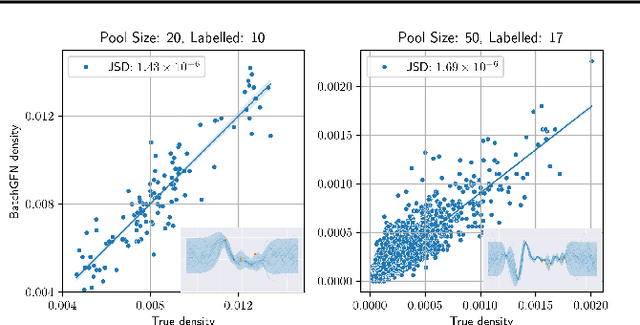
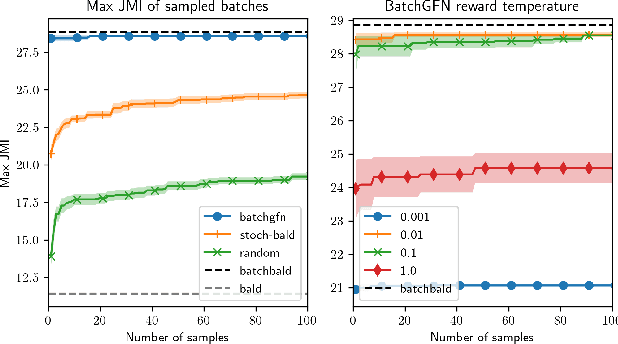
We introduce BatchGFN -- a novel approach for pool-based active learning that uses generative flow networks to sample sets of data points proportional to a batch reward. With an appropriate reward function to quantify the utility of acquiring a batch, such as the joint mutual information between the batch and the model parameters, BatchGFN is able to construct highly informative batches for active learning in a principled way. We show our approach enables sampling near-optimal utility batches at inference time with a single forward pass per point in the batch in toy regression problems. This alleviates the computational complexity of batch-aware algorithms and removes the need for greedy approximations to find maximizers for the batch reward. We also present early results for amortizing training across acquisition steps, which will enable scaling to real-world tasks.
Joint Bayesian Inference of Graphical Structure and Parameters with a Single Generative Flow Network
May 30, 2023



Generative Flow Networks (GFlowNets), a class of generative models over discrete and structured sample spaces, have been previously applied to the problem of inferring the marginal posterior distribution over the directed acyclic graph (DAG) of a Bayesian Network, given a dataset of observations. Based on recent advances extending this framework to non-discrete sample spaces, we propose in this paper to approximate the joint posterior over not only the structure of a Bayesian Network, but also the parameters of its conditional probability distributions. We use a single GFlowNet whose sampling policy follows a two-phase process: the DAG is first generated sequentially one edge at a time, and then the corresponding parameters are picked once the full structure is known. Since the parameters are included in the posterior distribution, this leaves more flexibility for the local probability models of the Bayesian Network, making our approach applicable even to non-linear models parametrized by neural networks. We show that our method, called JSP-GFN, offers an accurate approximation of the joint posterior, while comparing favorably against existing methods on both simulated and real data.
GFlowNets for AI-Driven Scientific Discovery
Feb 01, 2023



Tackling the most pressing problems for humanity, such as the climate crisis and the threat of global pandemics, requires accelerating the pace of scientific discovery. While science has traditionally relied on trial and error and even serendipity to a large extent, the last few decades have seen a surge of data-driven scientific discoveries. However, in order to truly leverage large-scale data sets and high-throughput experimental setups, machine learning methods will need to be further improved and better integrated in the scientific discovery pipeline. A key challenge for current machine learning methods in this context is the efficient exploration of very large search spaces, which requires techniques for estimating reducible (epistemic) uncertainty and generating sets of diverse and informative experiments to perform. This motivated a new probabilistic machine learning framework called GFlowNets, which can be applied in the modeling, hypotheses generation and experimental design stages of the experimental science loop. GFlowNets learn to sample from a distribution given indirectly by a reward function corresponding to an unnormalized probability, which enables sampling diverse, high-reward candidates. GFlowNets can also be used to form efficient and amortized Bayesian posterior estimators for causal models conditioned on the already acquired experimental data. Having such posterior models can then provide estimators of epistemic uncertainty and information gain that can drive an experimental design policy. Altogether, here we will argue that GFlowNets can become a valuable tool for AI-driven scientific discovery, especially in scenarios of very large candidate spaces where we have access to cheap but inaccurate measurements or to expensive but accurate measurements. This is a common setting in the context of drug and material discovery, which we use as examples throughout the paper.
A theory of continuous generative flow networks
Jan 30, 2023



Generative flow networks (GFlowNets) are amortized variational inference algorithms that are trained to sample from unnormalized target distributions over compositional objects. A key limitation of GFlowNets until this time has been that they are restricted to discrete spaces. We present a theory for generalized GFlowNets, which encompasses both existing discrete GFlowNets and ones with continuous or hybrid state spaces, and perform experiments with two goals in mind. First, we illustrate critical points of the theory and the importance of various assumptions. Second, we empirically demonstrate how observations about discrete GFlowNets transfer to the continuous case and show strong results compared to non-GFlowNet baselines on several previously studied tasks. This work greatly widens the perspectives for the application of GFlowNets in probabilistic inference and various modeling settings.
Synergies Between Disentanglement and Sparsity: a Multi-Task Learning Perspective
Nov 26, 2022

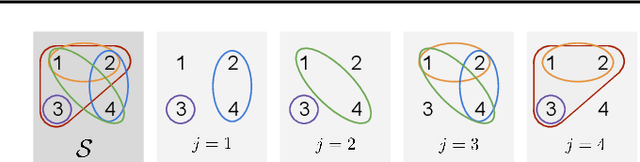
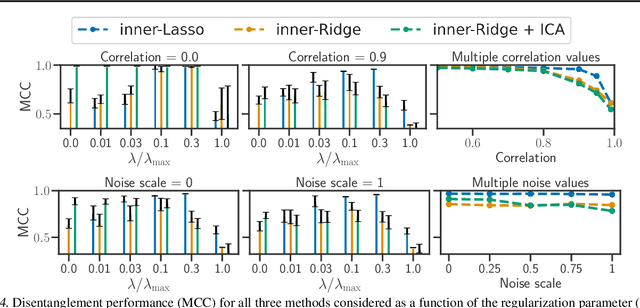
Although disentangled representations are often said to be beneficial for downstream tasks, current empirical and theoretical understanding is limited. In this work, we provide evidence that disentangled representations coupled with sparse base-predictors improve generalization. In the context of multi-task learning, we prove a new identifiability result that provides conditions under which maximally sparse base-predictors yield disentangled representations. Motivated by this theoretical result, we propose a practical approach to learn disentangled representations based on a sparsity-promoting bi-level optimization problem. Finally, we explore a meta-learning version of this algorithm based on group Lasso multiclass SVM base-predictors, for which we derive a tractable dual formulation. It obtains competitive results on standard few-shot classification benchmarks, while each task is using only a fraction of the learned representations.