 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Neural PDE Surrogates for Prediction and Downscaling: Application to Ocean Currents
Jul 24, 2025Accurate modeling of physical systems governed by partial differential equations is a central challenge in scientific computing. In oceanography, high-resolution current data are critical for coastal management, environmental monitoring, and maritime safety. However, available satellite products, such as Copernicus data for sea water velocity at ~0.08 degrees spatial resolution and global ocean models, often lack the spatial granularity required for detailed local analyses. In this work, we (a) introduce a supervised deep learning framework based on neural operators for solving PDEs and providing arbitrary resolution solutions, and (b) propose downscaling models with an application to Copernicus ocean current data. Additionally, our method can model surrogate PDEs and predict solutions at arbitrary resolution, regardless of the input resolution. We evaluated our model on real-world Copernicus ocean current data and synthetic Navier-Stokes simulation datasets.
OBELiX: A Curated Dataset of Crystal Structures and Experimentally Measured Ionic Conductivities for Lithium Solid-State Electrolytes
Feb 20, 2025



Solid-state electrolyte batteries are expected to replace liquid electrolyte lithium-ion batteries in the near future thanks to their higher theoretical energy density and improved safety. However, their adoption is currently hindered by their lower effective ionic conductivity, a quantity that governs charge and discharge rates. Identifying highly ion-conductive materials using conventional theoretical calculations and experimental validation is both time-consuming and resource-intensive. While machine learning holds the promise to expedite this process, relevant ionic conductivity and structural data is scarce. Here, we present OBELiX, a domain-expert-curated database of $\sim$600 synthesized solid electrolyte materials and their experimentally measured room temperature ionic conductivities gathered from literature. Each material is described by their measured composition, space group and lattice parameters. A full-crystal description in the form of a crystallographic information file (CIF) is provided for ~320 structures for which atomic positions were available. We discuss various statistics and features of the dataset and provide training and testing splits that avoid data leakage. Finally, we benchmark seven existing ML models on the task of predicting ionic conductivity and discuss their performance. The goal of this work is to facilitate the use of machine learning for solid-state electrolyte materials discovery.
Improved Off-policy Reinforcement Learning in Biological Sequence Design
Oct 06, 2024
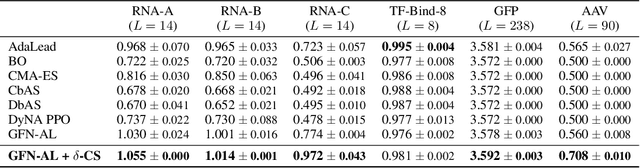
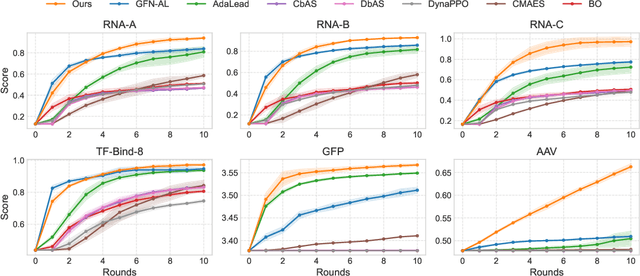
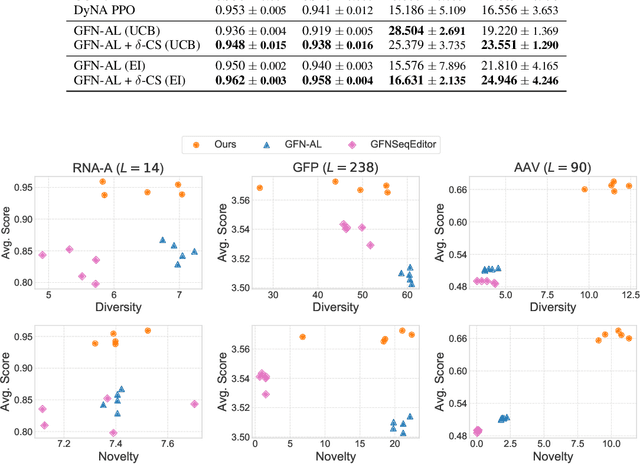
Designing biological sequences with desired properties is a significant challenge due to the combinatorially vast search space and the high cost of evaluating each candidate sequence. To address these challenges, reinforcement learning (RL) methods, such as GFlowNets, utilize proxy models for rapid reward evaluation and annotated data for policy training. Although these approaches have shown promise in generating diverse and novel sequences, the limited training data relative to the vast search space often leads to the misspecification of proxy for out-of-distribution inputs. We introduce $\delta$-Conservative Search, a novel off-policy search method for training GFlowNets designed to improve robustness against proxy misspecification. The key idea is to incorporate conservativeness, controlled by parameter $\delta$, to constrain the search to reliable regions. Specifically, we inject noise into high-score offline sequences by randomly masking tokens with a Bernoulli distribution of parameter $\delta$ and then denoise masked tokens using the GFlowNet policy. Additionally, $\delta$ is adaptively adjusted based on the uncertainty of the proxy model for each data point. This enables the reflection of proxy uncertainty to determine the level of conservativeness. Experimental results demonstrate that our method consistently outperforms existing machine learning methods in discovering high-score sequences across diverse tasks-including DNA, RNA, protein, and peptide design-especially in large-scale scenarios.
Towards equilibrium molecular conformation generation with GFlowNets
Oct 20, 2023



Sampling diverse, thermodynamically feasible molecular conformations plays a crucial role in predicting properties of a molecule. In this paper we propose to use GFlowNet for sampling conformations of small molecules from the Boltzmann distribution, as determined by the molecule's energy. The proposed approach can be used in combination with energy estimation methods of different fidelity and discovers a diverse set of low-energy conformations for highly flexible drug-like molecules. We demonstrate that GFlowNet can reproduce molecular potential energy surfaces by sampling proportionally to the Boltzmann distribution.
A theory of continuous generative flow networks
Jan 30, 2023



Generative flow networks (GFlowNets) are amortized variational inference algorithms that are trained to sample from unnormalized target distributions over compositional objects. A key limitation of GFlowNets until this time has been that they are restricted to discrete spaces. We present a theory for generalized GFlowNets, which encompasses both existing discrete GFlowNets and ones with continuous or hybrid state spaces, and perform experiments with two goals in mind. First, we illustrate critical points of the theory and the importance of various assumptions. Second, we empirically demonstrate how observations about discrete GFlowNets transfer to the continuous case and show strong results compared to non-GFlowNet baselines on several previously studied tasks. This work greatly widens the perspectives for the application of GFlowNets in probabilistic inference and various modeling settings.
PhAST: Physics-Aware, Scalable, and Task-specific GNNs for Accelerated Catalyst Design
Nov 22, 2022Mitigating the climate crisis requires a rapid transition towards lower carbon energy. Catalyst materials play a crucial role in the electrochemical reactions involved in a great number of industrial processes key to this transition, such as renewable energy storage and electrofuel synthesis. To reduce the amount of energy spent on such processes, we must quickly discover more efficient catalysts to drive the electrochemical reactions. Machine learning (ML) holds the potential to efficiently model the properties of materials from large amounts of data, and thus to accelerate electrocatalyst design. The Open Catalyst Project OC20 data set was constructed to that end. However, most existing ML models trained on OC20 are still neither scalable nor accurate enough for practical applications. Here, we propose several task-specific innovations, applicable to most architectures, which increase both computational efficiency and accuracy. In particular, we propose improvements in (1) the graph creation step, (2) atom representations and (3) the energy prediction head. We describe these contributions and evaluate them on several architectures, showing up to 5$\times$ reduction in inference time without sacrificing accuracy.
Further advantages of data augmentation on convolutional neural networks
Jun 26, 2019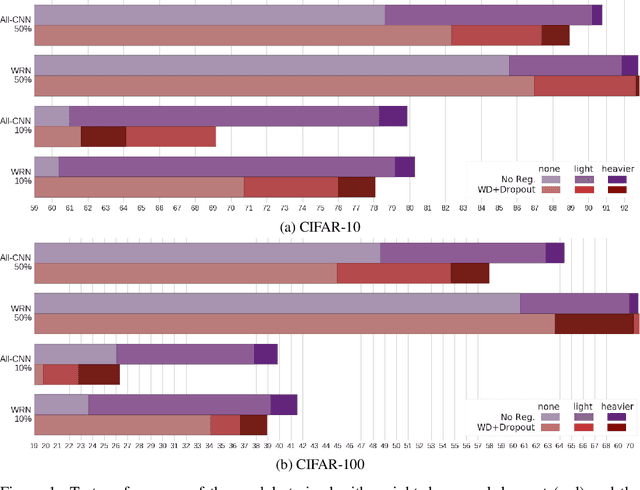
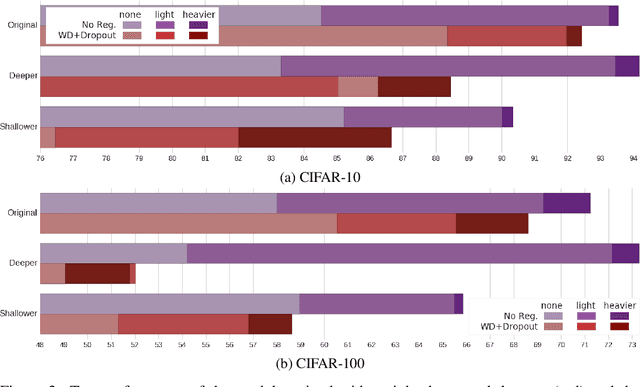
Data augmentation is a popular technique largely used to enhance the training of convolutional neural networks. Although many of its benefits are well known by deep learning researchers and practitioners, its implicit regularization effects, as compared to popular explicit regularization techniques, such as weight decay and dropout, remain largely unstudied. As a matter of fact, convolutional neural networks for image object classification are typically trained with both data augmentation and explicit regularization, assuming the benefits of all techniques are complementary. In this paper, we systematically analyze these techniques through ablation studies of different network architectures trained with different amounts of training data. Our results unveil a largely ignored advantage of data augmentation: networks trained with just data augmentation more easily adapt to different architectures and amount of training data, as opposed to weight decay and dropout, which require specific fine-tuning of their hyperparameters.
* Preprint of the manuscript accepted for presentation at the International Conference on Artificial Neural Networks (ICANN) 2018. Best Paper Award
Learning robust visual representations using data augmentation invariance
Jun 11, 2019

Deep convolutional neural networks trained for image object categorization have shown remarkable similarities with representations found across the primate ventral visual stream. Yet, artificial and biological networks still exhibit important differences. Here we investigate one such property: increasing invariance to identity-preserving image transformations found along the ventral stream. Despite theoretical evidence that invariance should emerge naturally from the optimization process, we present empirical evidence that the activations of convolutional neural networks trained for object categorization are not robust to identity-preserving image transformations commonly used in data augmentation. As a solution, we propose data augmentation invariance, an unsupervised learning objective which improves the robustness of the learned representations by promoting the similarity between the activations of augmented image samples. Our results show that this approach is a simple, yet effective and efficient (10 % increase in training time) way of increasing the invariance of the models while obtaining similar categorization performance.
Data augmentation instead of explicit regularization
Aug 01, 2018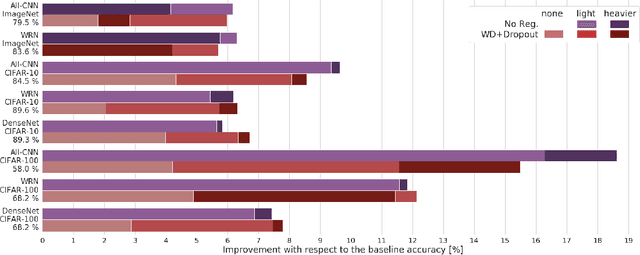
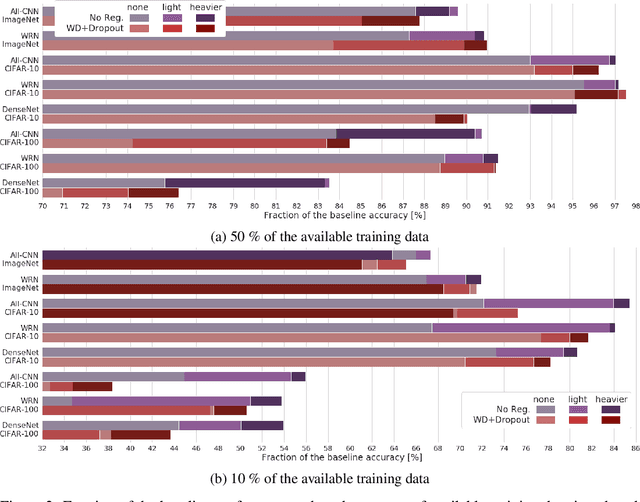
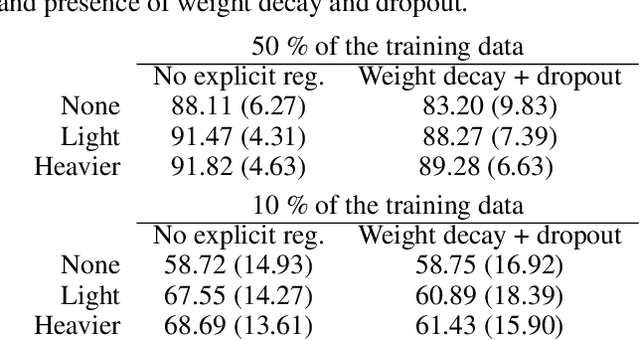
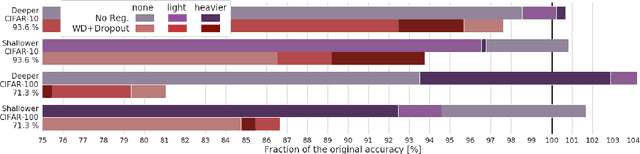
Modern deep artificial neural networks have achieved impressive results through models with very large capacity---compared to the number of training examples---that control overfitting with the help of different forms of regularization. Regularization can be implicit, as is the case of stochastic gradient descent and parameter sharing in convolutional layers, or explicit. Most common explicit regularization techniques, such as weight decay and dropout, reduce the effective capacity of the model and typically require the use of deeper and wider architectures to compensate for the reduced capacity. Although these techniques have been proven successful in terms of improved generalization, they seem to waste capacity. In contrast, data augmentation techniques do not reduce the effective capacity and improve generalization by increasing the number of training examples. In this paper we systematically analyze the effect of data augmentation on some popular architectures and conclude that data augmentation alone---without any other explicit regularization techniques---can achieve the same performance or higher as regularized models, especially when training with fewer examples, and exhibits much higher adaptability to changes in the architecture.
Do deep nets really need weight decay and dropout?
Jul 12, 2018
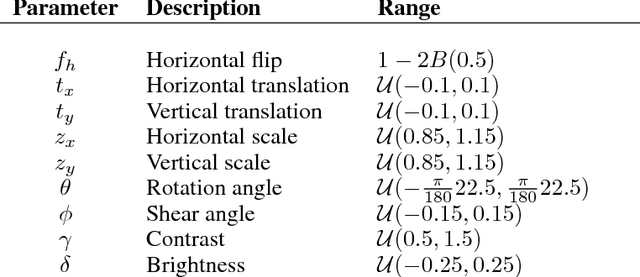
The impressive success of modern deep neural networks on computer vision tasks has been achieved through models of very large capacity compared to the number of available training examples. This overparameterization is often said to be controlled with the help of different regularization techniques, mainly weight decay and dropout. However, since these techniques reduce the effective capacity of the model, typically even deeper and wider architectures are required to compensate for the reduced capacity. Therefore, there seems to be a waste of capacity in this practice. In this paper we build upon recent research that suggests that explicit regularization may not be as important as widely believed and carry out an ablation study that concludes that weight decay and dropout may not be necessary for object recognition if enough data augmentation is introduced.