 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing stability and plasticity in continual learning: the readout-decomposition of activation change (RDAC) framework
Oct 10, 2023Continual learning (CL) algorithms strive to acquire new knowledge while preserving prior information. However, this stability-plasticity trade-off remains a central challenge. This paper introduces a framework that dissects this trade-off, offering valuable insights into CL algorithms. The Readout-Decomposition of Activation Change (RDAC) framework first addresses the stability-plasticity dilemma and its relation to catastrophic forgetting. It relates learning-induced activation changes in the range of prior readouts to the degree of stability and changes in the null space to the degree of plasticity. In deep non-linear networks tackling split-CIFAR-110 tasks, the framework clarifies the stability-plasticity trade-offs of the popular regularization algorithms Synaptic intelligence (SI), Elastic-weight consolidation (EWC), and learning without Forgetting (LwF), and replay-based algorithms Gradient episodic memory (GEM), and data replay. GEM and data replay preserved stability and plasticity, while SI, EWC, and LwF traded off plasticity for stability. The inability of the regularization algorithms to maintain plasticity was linked to them restricting the change of activations in the null space of the prior readout. Additionally, for one-hidden-layer linear neural networks, we derived a gradient decomposition algorithm to restrict activation change only in the range of the prior readouts, to maintain high stability while not further sacrificing plasticity. Results demonstrate that the algorithm maintained stability without significant plasticity loss. The RDAC framework informs the behavior of existing CL algorithms and paves the way for novel CL approaches. Finally, it sheds light on the connection between learning-induced activation/representation changes and the stability-plasticity dilemma, also offering insights into representational drift in biological systems.
Diagnosing Catastrophe: Large parts of accuracy loss in continual learning can be accounted for by readout misalignment
Oct 09, 2023Unlike primates, training artificial neural networks on changing data distributions leads to a rapid decrease in performance on old tasks. This phenomenon is commonly referred to as catastrophic forgetting. In this paper, we investigate the representational changes that underlie this performance decrease and identify three distinct processes that together account for the phenomenon. The largest component is a misalignment between hidden representations and readout layers. Misalignment occurs due to learning on additional tasks and causes internal representations to shift. Representational geometry is partially conserved under this misalignment and only a small part of the information is irrecoverably lost. All types of representational changes scale with the dimensionality of hidden representations. These insights have implications for deep learning applications that need to be continuously updated, but may also aid aligning ANN models to the rather robust biological vision.
Fast Concept Mapping: The Emergence of Human Abilities in Artificial Neural Networks when Learning Embodied and Self-Supervised
Feb 03, 2021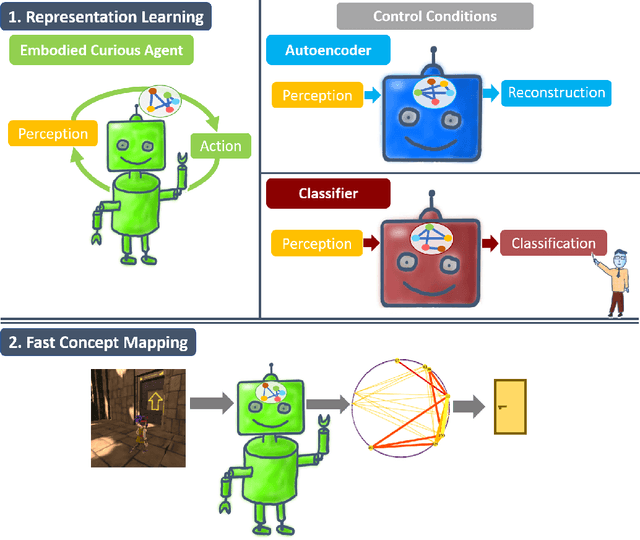
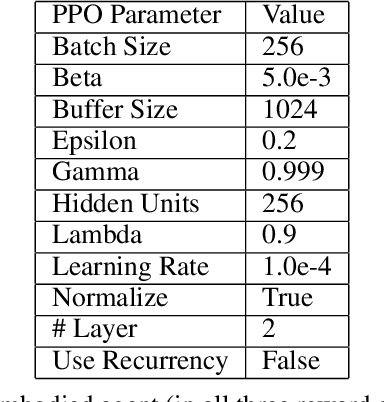
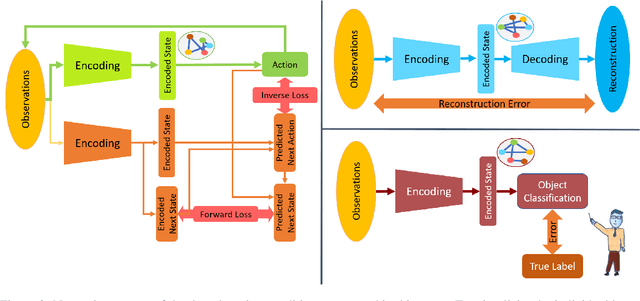
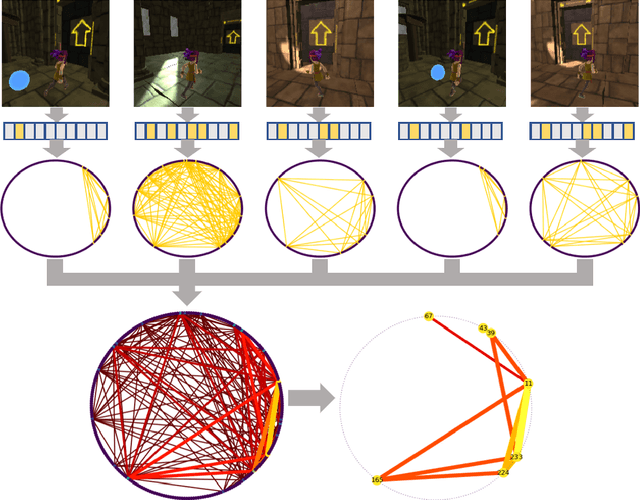
Most artificial neural networks used for object detection and recognition are trained in a fully supervised setup. This is not only very resource consuming as it requires large data sets of labeled examples but also very different from how humans learn. We introduce a setup in which an artificial agent first learns in a simulated world through self-supervised exploration. Following this, the representations learned through interaction with the world can be used to associate semantic concepts such as different types of doors. To do this, we use a method we call fast concept mapping which uses correlated firing patterns of neurons to define and detect semantic concepts. This association works instantaneous with very few labeled examples, similar to what we observe in humans in a phenomenon called fast mapping. Strikingly, this method already identifies objects with as little as one labeled example which highlights the quality of the encoding learned self-supervised through embodiment using curiosity-driven exploration. It therefor presents a feasible strategy for learning concepts without much supervision and shows that through pure interaction with the world meaningful representations of an environment can be learned.
Enhancing Traffic Scene Predictions with Generative Adversarial Networks
Sep 24, 2019
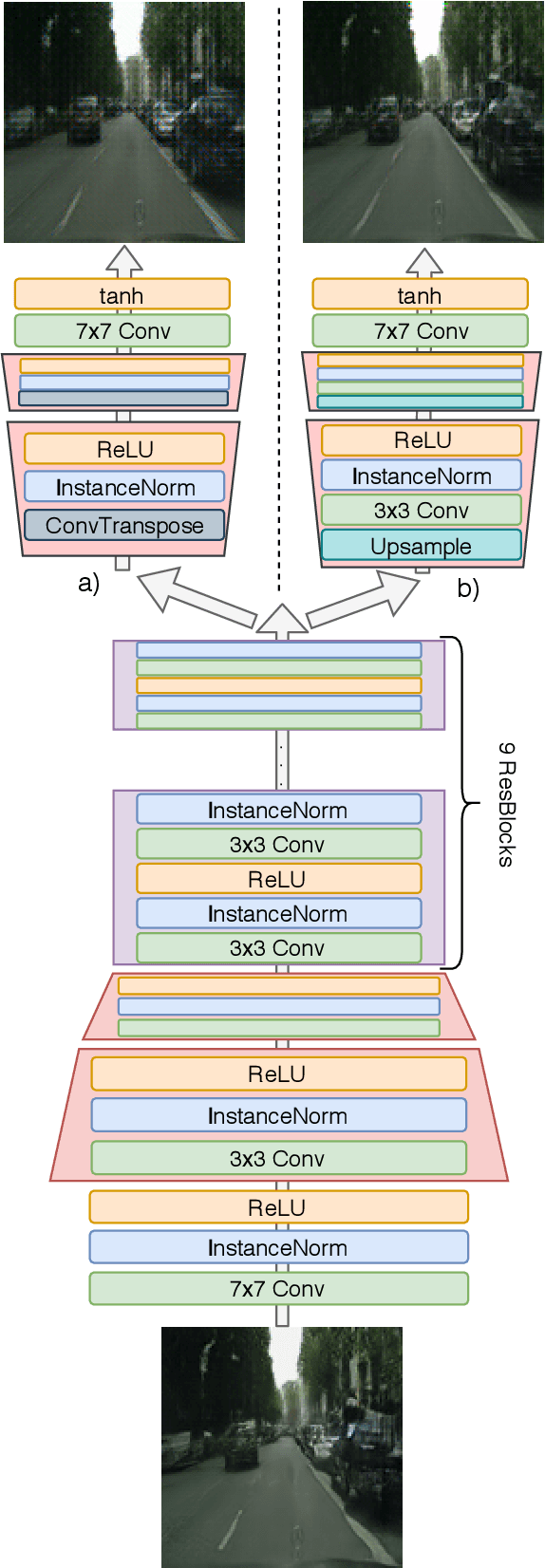

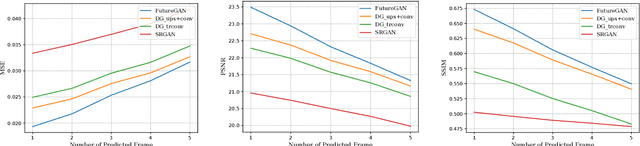
We present a new two-stage pipeline for predicting frames of traffic scenes where relevant objects can still reliably be detected. Using a recent video prediction network, we first generate a sequence of future frames based on past frames. A second network then enhances these frames in order to make them appear more realistic. This ensures the quality of the predicted frames to be sufficient to enable accurate detection of objects, which is especially important for autonomously driving cars. To verify this two-stage approach, we conducted experiments on the Cityscapes dataset. For enhancing, we trained two image-to-image translation methods based on generative adversarial networks, one for blind motion deblurring and one for image super-resolution. All resulting predictions were quantitatively evaluated using both traditional metrics and a state-of-the-art object detection network showing that the enhanced frames appear qualitatively improved. While the traditional image comparison metrics, i.e., MSE, PSNR, and SSIM, failed to confirm this visual impression, the object detection evaluation resembles it well. The best performing prediction-enhancement pipeline is able to increase the average precision values for detecting cars by about 9% for each prediction step, compared to the non-enhanced predictions.
Further advantages of data augmentation on convolutional neural networks
Jun 26, 2019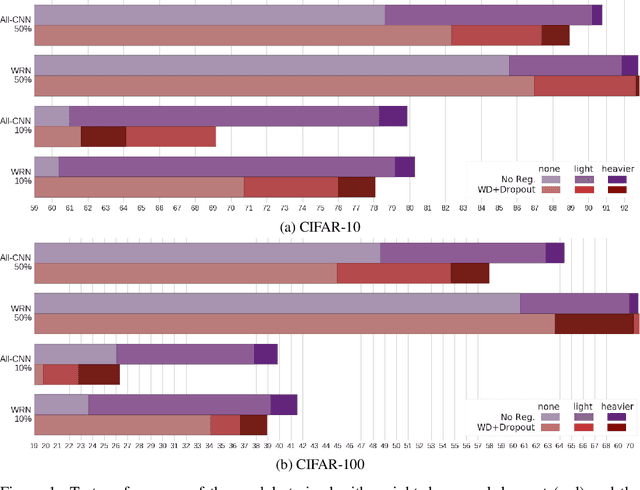
Data augmentation is a popular technique largely used to enhance the training of convolutional neural networks. Although many of its benefits are well known by deep learning researchers and practitioners, its implicit regularization effects, as compared to popular explicit regularization techniques, such as weight decay and dropout, remain largely unstudied. As a matter of fact, convolutional neural networks for image object classification are typically trained with both data augmentation and explicit regularization, assuming the benefits of all techniques are complementary. In this paper, we systematically analyze these techniques through ablation studies of different network architectures trained with different amounts of training data. Our results unveil a largely ignored advantage of data augmentation: networks trained with just data augmentation more easily adapt to different architectures and amount of training data, as opposed to weight decay and dropout, which require specific fine-tuning of their hyperparameters.
* Preprint of the manuscript accepted for presentation at the International Conference on Artificial Neural Networks (ICANN) 2018. Best Paper Award
Learning robust visual representations using data augmentation invariance
Jun 11, 2019

Deep convolutional neural networks trained for image object categorization have shown remarkable similarities with representations found across the primate ventral visual stream. Yet, artificial and biological networks still exhibit important differences. Here we investigate one such property: increasing invariance to identity-preserving image transformations found along the ventral stream. Despite theoretical evidence that invariance should emerge naturally from the optimization process, we present empirical evidence that the activations of convolutional neural networks trained for object categorization are not robust to identity-preserving image transformations commonly used in data augmentation. As a solution, we propose data augmentation invariance, an unsupervised learning objective which improves the robustness of the learned representations by promoting the similarity between the activations of augmented image samples. Our results show that this approach is a simple, yet effective and efficient (10 % increase in training time) way of increasing the invariance of the models while obtaining similar categorization performance.
Data augmentation instead of explicit regularization
Aug 01, 2018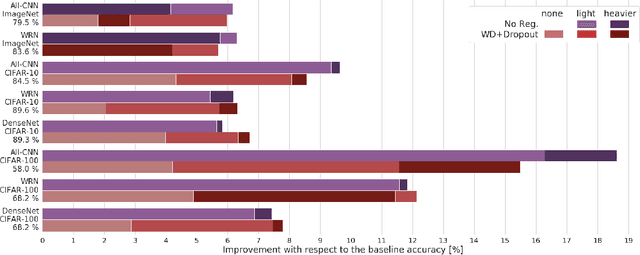
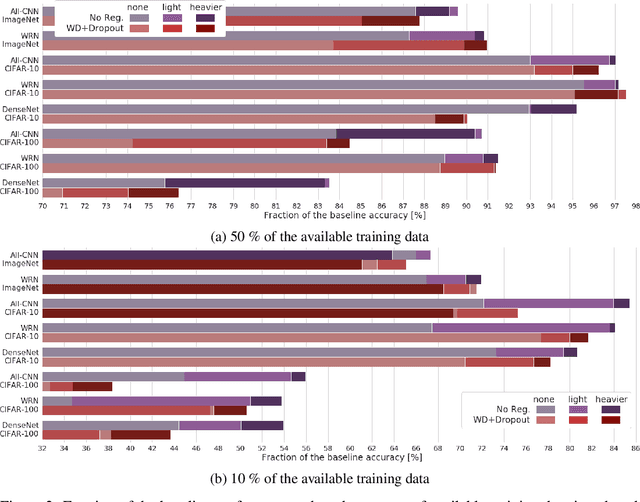
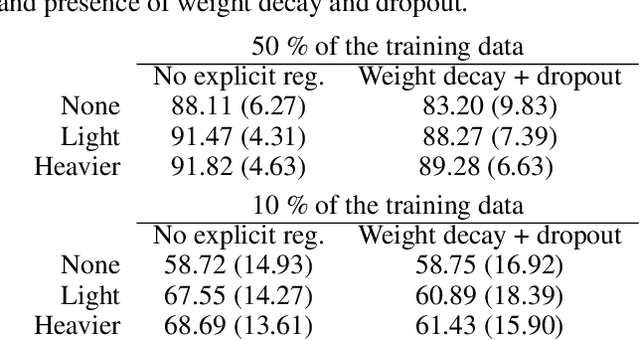
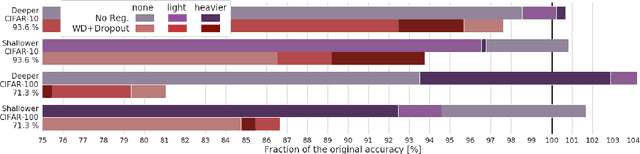
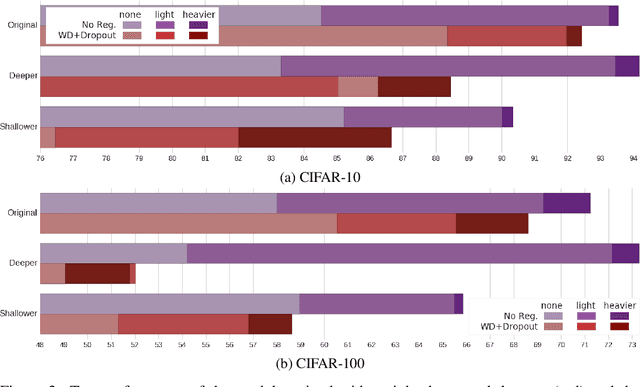
Modern deep artificial neural networks have achieved impressive results through models with very large capacity---compared to the number of training examples---that control overfitting with the help of different forms of regularization. Regularization can be implicit, as is the case of stochastic gradient descent and parameter sharing in convolutional layers, or explicit. Most common explicit regularization techniques, such as weight decay and dropout, reduce the effective capacity of the model and typically require the use of deeper and wider architectures to compensate for the reduced capacity. Although these techniques have been proven successful in terms of improved generalization, they seem to waste capacity. In contrast, data augmentation techniques do not reduce the effective capacity and improve generalization by increasing the number of training examples. In this paper we systematically analyze the effect of data augmentation on some popular architectures and conclude that data augmentation alone---without any other explicit regularization techniques---can achieve the same performance or higher as regularized models, especially when training with fewer examples, and exhibits much higher adaptability to changes in the architecture.
Do deep nets really need weight decay and dropout?
Jul 12, 2018
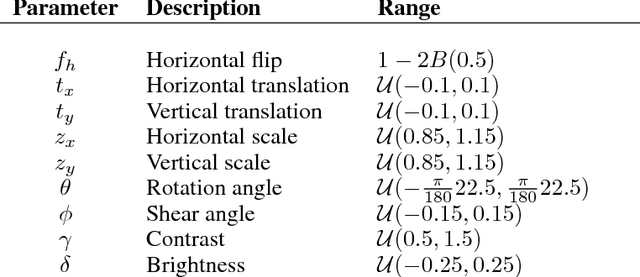
The impressive success of modern deep neural networks on computer vision tasks has been achieved through models of very large capacity compared to the number of available training examples. This overparameterization is often said to be controlled with the help of different regularization techniques, mainly weight decay and dropout. However, since these techniques reduce the effective capacity of the model, typically even deeper and wider architectures are required to compensate for the reduced capacity. Therefore, there seems to be a waste of capacity in this practice. In this paper we build upon recent research that suggests that explicit regularization may not be as important as widely believed and carry out an ablation study that concludes that weight decay and dropout may not be necessary for object recognition if enough data augmentation is introduced.