 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Traffic Scene Predictions with Generative Adversarial Networks
Sep 24, 2019
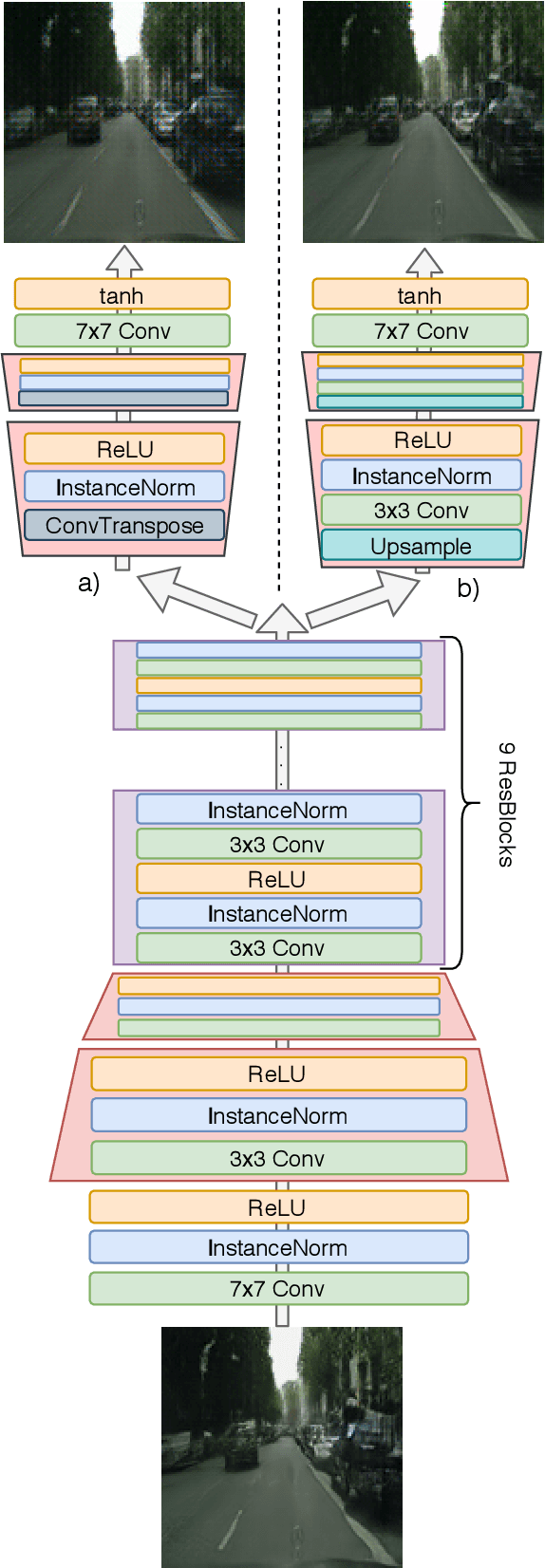

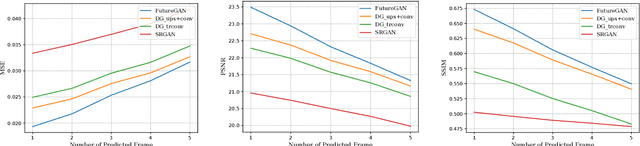
We present a new two-stage pipeline for predicting frames of traffic scenes where relevant objects can still reliably be detected. Using a recent video prediction network, we first generate a sequence of future frames based on past frames. A second network then enhances these frames in order to make them appear more realistic. This ensures the quality of the predicted frames to be sufficient to enable accurate detection of objects, which is especially important for autonomously driving cars. To verify this two-stage approach, we conducted experiments on the Cityscapes dataset. For enhancing, we trained two image-to-image translation methods based on generative adversarial networks, one for blind motion deblurring and one for image super-resolution. All resulting predictions were quantitatively evaluated using both traditional metrics and a state-of-the-art object detection network showing that the enhanced frames appear qualitatively improved. While the traditional image comparison metrics, i.e., MSE, PSNR, and SSIM, failed to confirm this visual impression, the object detection evaluation resembles it well. The best performing prediction-enhancement pipeline is able to increase the average precision values for detecting cars by about 9% for each prediction step, compared to the non-enhanced predictions.
FutureGAN: Anticipating the Future Frames of Video Sequences using Spatio-Temporal 3d Convolutions in Progressively Growing Autoencoder GANs
Oct 02, 2018

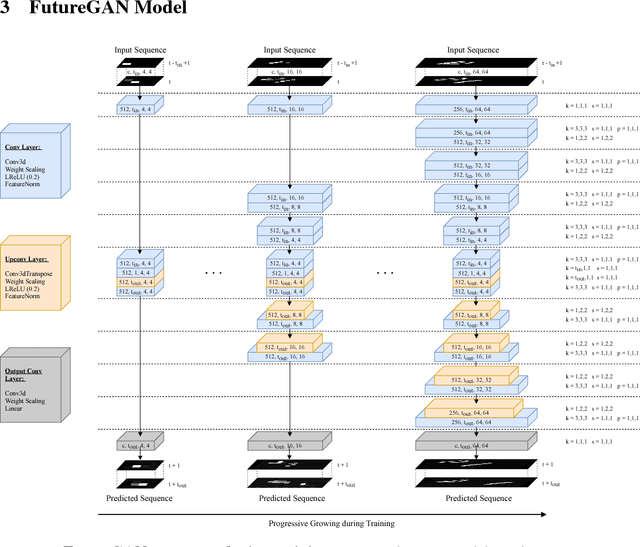

We propose a new Autoencoder GAN model, FutureGAN, that predicts future frames of a video sequence given a sequence of past frames. Our approach extends the recently introduced progressive growing of GANs (PGGAN) architecture by Karras et al. [18]. During training, the resolution of the input and output frames is gradually increased by progressively adding layers in both the discriminator and the generator network. To learn representations that effectively capture the spatial and temporal components of a frame sequence, we use spatio-temporal 3d convolutions. We already achieve promising results for frame resolutions of 128 x 128 px over a variety of datasets ranging from synthetic to natural frame sequences, while theoretically not being limited to a specific frame resolution. The FutureGAN learns to generate plausible futures, learning representations that seem to effectively capture the spatial and the temporal transformations of the input frames. A great advantage of our architecture, in comparison to the majority of other video prediction models, is its simplicity. The model receives solely the raw pixel values as an input, generating output frames effectively, without relying on additional constraints, conditions, or complex pixel-based error loss metrics.