 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureGAN: Anticipating the Future Frames of Video Sequences using Spatio-Temporal 3d Convolutions in Progressively Growing Autoencoder GANs
Paper and Code


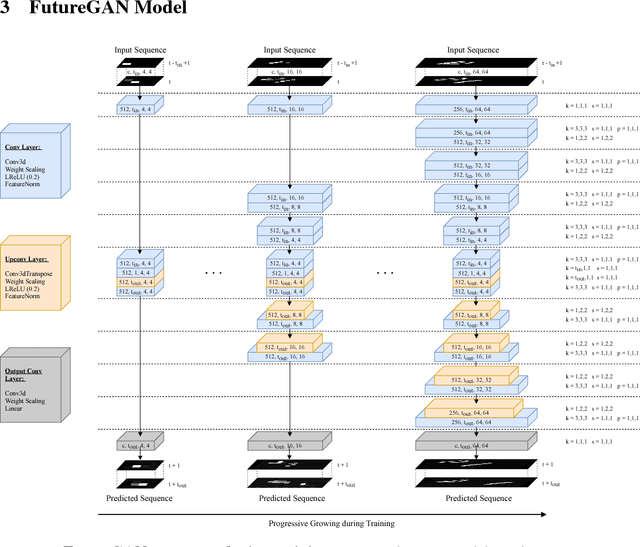

We propose a new Autoencoder GAN model, FutureGAN, that predicts future frames of a video sequence given a sequence of past frames. Our approach extends the recently introduced progressive growing of GANs (PGGAN) architecture by Karras et al. [18]. During training, the resolution of the input and output frames is gradually increased by progressively adding layers in both the discriminator and the generator network. To learn representations that effectively capture the spatial and temporal components of a frame sequence, we use spatio-temporal 3d convolutions. We already achieve promising results for frame resolutions of 128 x 128 px over a variety of datasets ranging from synthetic to natural frame sequences, while theoretically not being limited to a specific frame resolution. The FutureGAN learns to generate plausible futures, learning representations that seem to effectively capture the spatial and the temporal transformations of the input frames. A great advantage of our architecture, in comparison to the majority of other video prediction models, is its simplicity. The model receives solely the raw pixel values as an input, generating output frames effectively, without relying on additional constraints, conditions, or complex pixel-based error loss metrics.