 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting upcoming visual features during eye movements yields scene representations aligned with human visual cortex
Nov 16, 2025

Scenes are complex, yet structured collections of parts, including objects and surfaces, that exhibit spatial and semantic relations to one another. An effective visual system therefore needs unified scene representations that relate scene parts to their location and their co-occurrence. We hypothesize that this structure can be learned self-supervised from natural experience by exploiting the temporal regularities of active vision: each fixation reveals a locally-detailed glimpse that is statistically related to the previous one via co-occurrence and saccade-conditioned spatial regularities. We instantiate this idea with Glimpse Prediction Networks (GPNs) -- recurrent models trained to predict the feature embedding of the next glimpse along human-like scanpaths over natural scenes. GPNs successfully learn co-occurrence structure and, when given relative saccade location vectors, show sensitivity to spatial arrangement. Furthermore, recurrent variants of GPNs were able to integrate information across glimpses into a unified scene representation. Notably, these scene representations align strongly with human fMRI responses during natural-scene viewing across mid/high-level visual cortex. Critically, GPNs outperform architecture- and dataset-matched controls trained with explicit semantic objectives, and match or exceed strong modern vision baselines, leaving little unique variance for those alternatives. These results establish next-glimpse prediction during active vision as a biologically plausible, self-supervised route to brain-aligned scene representations learned from natural visual experience.
Sparks of cognitive flexibility: self-guided context inference for flexible stimulus-response mapping by attentional routing
Feb 21, 2025Flexible cognition demands discovering hidden rules to quickly adapt stimulus-response mappings. Standard neural networks struggle in tasks requiring rapid, context-driven remapping. Recently, Hummos (2023) introduced a fast-and-slow learning algorithm to mitigate this shortfall, but its scalability to complex, image-computable tasks was unclear. Here, we propose the Wisconsin Neural Network (WiNN), which expands on fast-and-slow learning for real-world tasks demanding flexible rule-based behavior. WiNN employs a pretrained convolutional neural network for vision, coupled with an adjustable "context state" that guides attention to relevant features. If WiNN produces an incorrect response, it first iteratively updates its context state to refocus attention on task-relevant cues, then performs minimal parameter updates to attention and readout layers. This strategy preserves generalizable representations in the sensory network, reducing catastrophic forgetting. We evaluate WiNN on an image-based extension of the Wisconsin Card Sorting Task, revealing several markers of cognitive flexibility: (i) WiNN autonomously infers underlying rules, (ii) requires fewer examples to do so than control models reliant on large-scale parameter updates, (iii) can perform context-based rule inference solely via context-state adjustments-further enhanced by slow updates of attention and readout parameters, and (iv) generalizes to unseen compositional rules through context-state inference alone. By blending fast context inference with targeted attentional guidance, WiNN achieves "sparks" of flexibility. This approach offers a path toward context-sensitive models that retain knowledge while rapidly adapting to complex, rule-based tasks.
Balancing stability and plasticity in continual learning: the readout-decomposition of activation change (RDAC) framework
Oct 10, 2023Continual learning (CL) algorithms strive to acquire new knowledge while preserving prior information. However, this stability-plasticity trade-off remains a central challenge. This paper introduces a framework that dissects this trade-off, offering valuable insights into CL algorithms. The Readout-Decomposition of Activation Change (RDAC) framework first addresses the stability-plasticity dilemma and its relation to catastrophic forgetting. It relates learning-induced activation changes in the range of prior readouts to the degree of stability and changes in the null space to the degree of plasticity. In deep non-linear networks tackling split-CIFAR-110 tasks, the framework clarifies the stability-plasticity trade-offs of the popular regularization algorithms Synaptic intelligence (SI), Elastic-weight consolidation (EWC), and learning without Forgetting (LwF), and replay-based algorithms Gradient episodic memory (GEM), and data replay. GEM and data replay preserved stability and plasticity, while SI, EWC, and LwF traded off plasticity for stability. The inability of the regularization algorithms to maintain plasticity was linked to them restricting the change of activations in the null space of the prior readout. Additionally, for one-hidden-layer linear neural networks, we derived a gradient decomposition algorithm to restrict activation change only in the range of the prior readouts, to maintain high stability while not further sacrificing plasticity. Results demonstrate that the algorithm maintained stability without significant plasticity loss. The RDAC framework informs the behavior of existing CL algorithms and paves the way for novel CL approaches. Finally, it sheds light on the connection between learning-induced activation/representation changes and the stability-plasticity dilemma, also offering insights into representational drift in biological systems.
Diagnosing Catastrophe: Large parts of accuracy loss in continual learning can be accounted for by readout misalignment
Oct 09, 2023Unlike primates, training artificial neural networks on changing data distributions leads to a rapid decrease in performance on old tasks. This phenomenon is commonly referred to as catastrophic forgetting. In this paper, we investigate the representational changes that underlie this performance decrease and identify three distinct processes that together account for the phenomenon. The largest component is a misalignment between hidden representations and readout layers. Misalignment occurs due to learning on additional tasks and causes internal representations to shift. Representational geometry is partially conserved under this misalignment and only a small part of the information is irrecoverably lost. All types of representational changes scale with the dimensionality of hidden representations. These insights have implications for deep learning applications that need to be continuously updated, but may also aid aligning ANN models to the rather robust biological vision.
Characterising representation dynamics in recurrent neural networks for object recognition
Aug 23, 2023Recurrent neural networks (RNNs) have yielded promising results for both recognizing objects in challenging conditions and modeling aspects of primate vision. However, the representational dynamics of recurrent computations remain poorly understood, especially in large-scale visual models. Here, we studied such dynamics in RNNs trained for object classification on MiniEcoset, a novel subset of ecoset. We report two main insights. First, upon inference, representations continued to evolve after correct classification, suggesting a lack of the notion of being ``done with classification''. Second, focusing on ``readout zones'' as a way to characterize the activation trajectories, we observe that misclassified representations exhibit activation patterns with lower L2 norm, and are positioned more peripherally in the readout zones. Such arrangements help the misclassified representations move into the correct zones as time progresses. Our findings generalize to networks with lateral and top-down connections, and include both additive and multiplicative interactions with the bottom-up sweep. The results therefore contribute to a general understanding of RNN dynamics in naturalistic tasks. We hope that the analysis framework will aid future investigations of other types of RNNs, including understanding of representational dynamics in primate vision.
Category-orthogonal object features guide information processing in recurrent neural networks trained for object categorization
Nov 15, 2021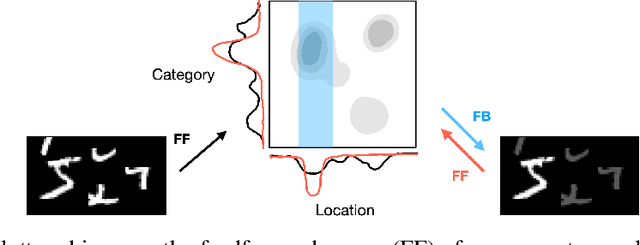
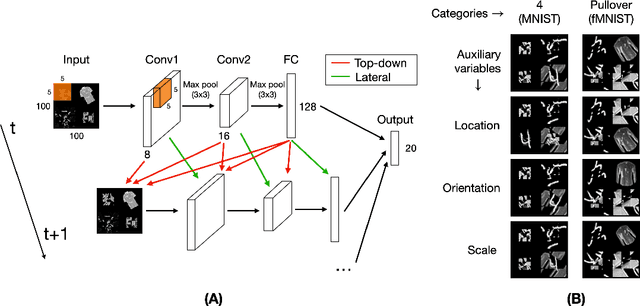
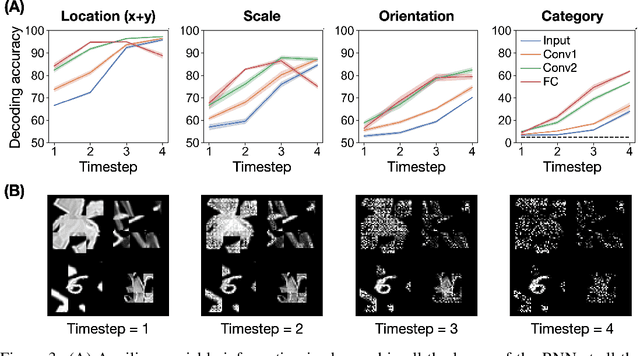
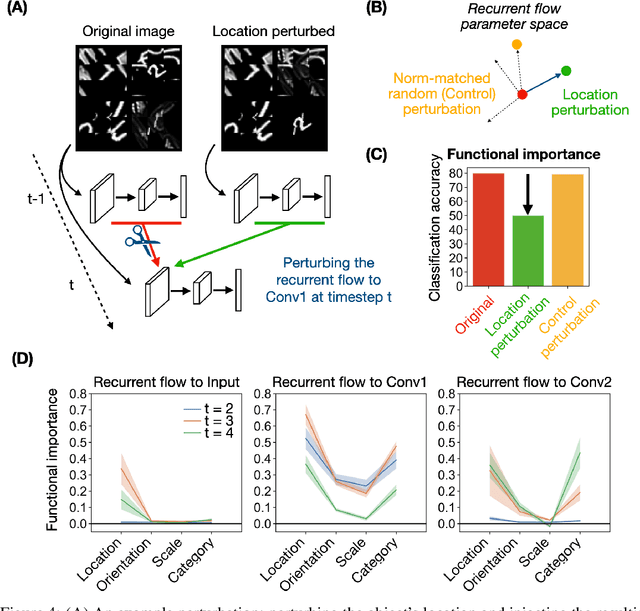
Recurrent neural networks (RNNs) have been shown to perform better than feedforward architectures in visual object categorization tasks, especially in challenging conditions such as cluttered images. However, little is known about the exact computational role of recurrent information flow in these conditions. Here we test RNNs trained for object categorization on the hypothesis that recurrence iteratively aids object categorization via the communication of category-orthogonal auxiliary variables (the location, orientation, and scale of the object). Using diagnostic linear readouts, we find that: (a) information about auxiliary variables increases across time in all network layers, (b) this information is indeed present in the recurrent information flow, and (c) its manipulation significantly affects task performance. These observations confirm the hypothesis that category-orthogonal auxiliary variable information is conveyed through recurrent connectivity and is used to optimize category inference in cluttered environments.
Learning robust visual representations using data augmentation invariance
Jun 11, 2019

Deep convolutional neural networks trained for image object categorization have shown remarkable similarities with representations found across the primate ventral visual stream. Yet, artificial and biological networks still exhibit important differences. Here we investigate one such property: increasing invariance to identity-preserving image transformations found along the ventral stream. Despite theoretical evidence that invariance should emerge naturally from the optimization process, we present empirical evidence that the activations of convolutional neural networks trained for object categorization are not robust to identity-preserving image transformations commonly used in data augmentation. As a solution, we propose data augmentation invariance, an unsupervised learning objective which improves the robustness of the learned representations by promoting the similarity between the activations of augmented image samples. Our results show that this approach is a simple, yet effective and efficient (10 % increase in training time) way of increasing the invariance of the models while obtaining similar categorization performance.