 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Concept Mapping: The Emergence of Human Abilities in Artificial Neural Networks when Learning Embodied and Self-Supervised
Feb 03, 2021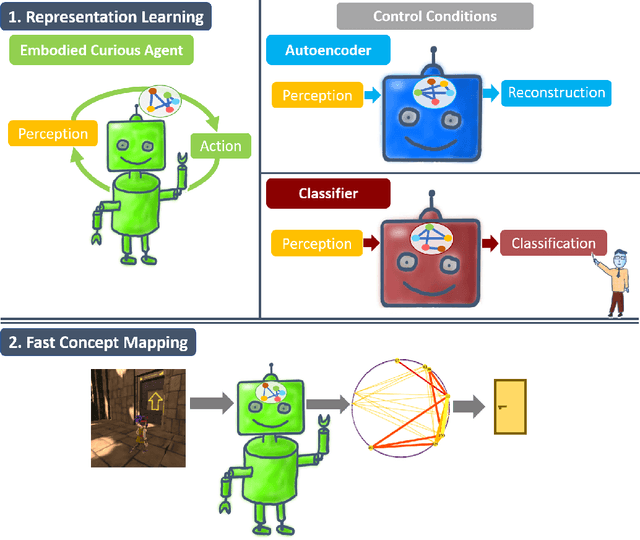
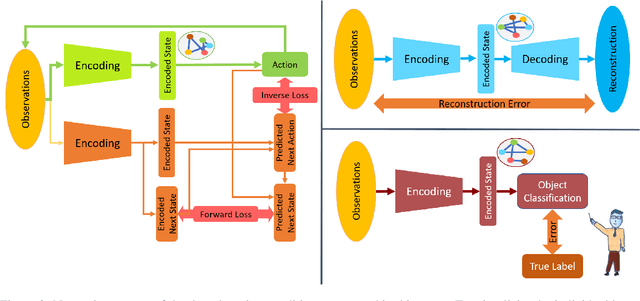
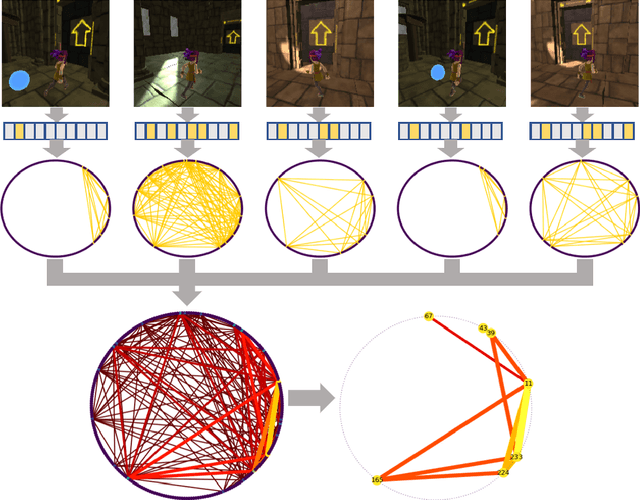
Most artificial neural networks used for object detection and recognition are trained in a fully supervised setup. This is not only very resource consuming as it requires large data sets of labeled examples but also very different from how humans learn. We introduce a setup in which an artificial agent first learns in a simulated world through self-supervised exploration. Following this, the representations learned through interaction with the world can be used to associate semantic concepts such as different types of doors. To do this, we use a method we call fast concept mapping which uses correlated firing patterns of neurons to define and detect semantic concepts. This association works instantaneous with very few labeled examples, similar to what we observe in humans in a phenomenon called fast mapping. Strikingly, this method already identifies objects with as little as one labeled example which highlights the quality of the encoding learned self-supervised through embodiment using curiosity-driven exploration. It therefor presents a feasible strategy for learning concepts without much supervision and shows that through pure interaction with the world meaningful representations of an environment can be learned.
Adaptive Blending Units: Trainable Activation Functions for Deep Neural Networks
Jun 26, 2018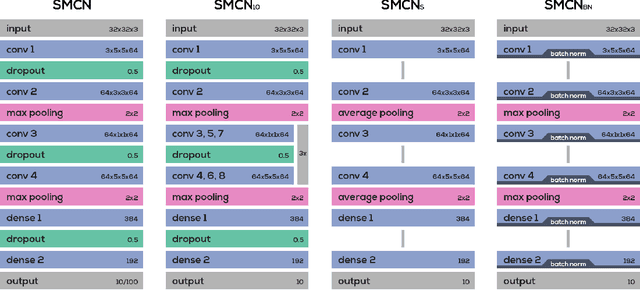
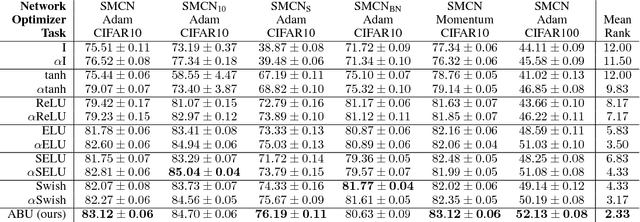
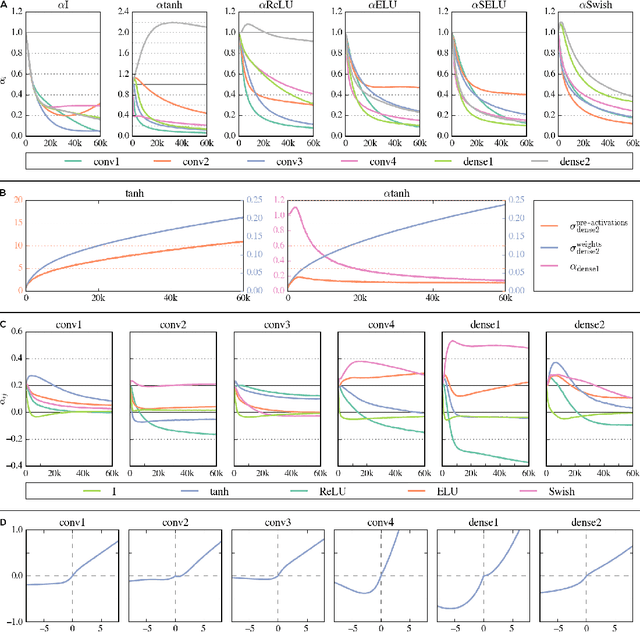

The most widely used activation functions in current deep feed-forward neural networks are rectified linear units (ReLU), and many alternatives have been successfully applied, as well. However, none of the alternatives have managed to consistently outperform the rest and there is no unified theory connecting properties of the task and network with properties of activation functions for most efficient training. A possible solution is to have the network learn its preferred activation functions. In this work, we introduce Adaptive Blending Units (ABUs), a trainable linear combination of a set of activation functions. Since ABUs learn the shape, as well as the overall scaling of the activation function, we also analyze the effects of adaptive scaling in common activation functions. We experimentally demonstrate advantages of both adaptive scaling and ABUs over common activation functions across a set of systematically varied network specifications. We further show that adaptive scaling works by mitigating covariate shifts during training, and that the observed advantages in performance of ABUs likewise rely largely on the activation function's ability to adapt over the course of training.