 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Federated Learning for Fine-tuning of Large Language Models
Feb 01, 2021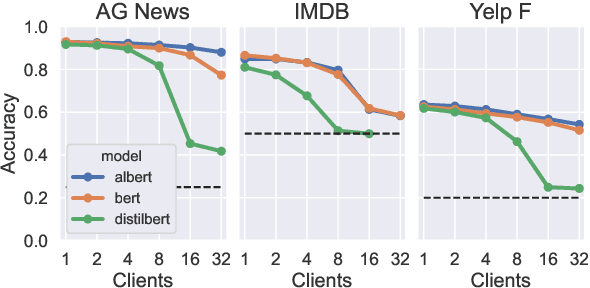
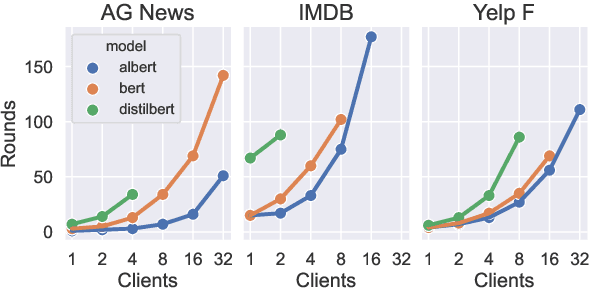
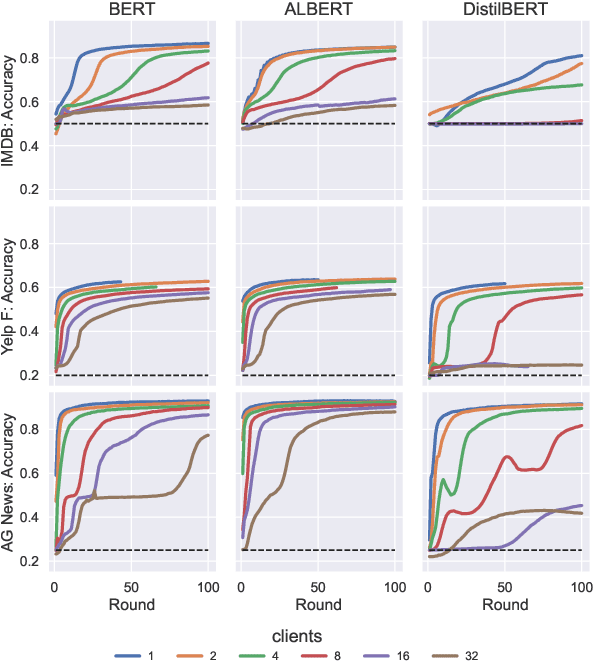
Federated learning (FL) is a promising approach to distributed compute, as well as distributed data, and provides a level of privacy and compliance to legal frameworks. This makes FL attractive for both consumer and healthcare applications. While the area is actively being explored, few studies have examined FL in the context of larger language models and there is a lack of comprehensive reviews of robustness across tasks, architectures, numbers of clients, and other relevant factors. In this paper, we explore the fine-tuning of Transformer-based language models in a federated learning setting. We evaluate three popular BERT-variants of different sizes (BERT, ALBERT, and DistilBERT) on a number of text classification tasks such as sentiment analysis and author identification. We perform an extensive sweep over the number of clients, ranging up to 32, to evaluate the impact of distributed compute on task performance in the federated averaging setting. While our findings suggest that the large sizes of the evaluated models are not generally prohibitive to federated training, we found that the different models handle federated averaging to a varying degree. Most notably, DistilBERT converges significantly slower with larger numbers of clients, and under some circumstances, even collapses to chance level performance. Investigating this issue presents an interesting perspective for future research.
Federated learning using a mixture of experts
Oct 05, 2020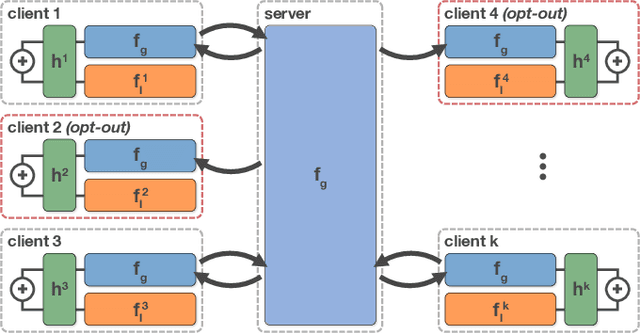

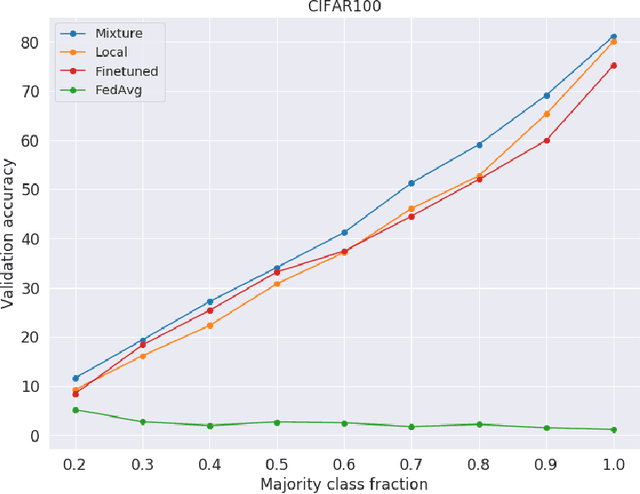

Federated learning has received attention for its efficiency and privacy benefits, in settings where data is distributed among devices. Although federated learning shows significant promise as a key approach when data cannot be shared or centralized, current incarnations show limited privacy properties and have shortcomings when applied to common real-world scenarios. One such scenario is heterogeneous data among devices, where data may come from different generating distributions. In this paper, we propose a federated learning framework using a mixture of experts to balance the specialist nature of a locally trained model with the generalist knowledge of a global model in a federated learning setting. Our results show that the mixture of experts model is better suited as a personalized model for devices when data is heterogeneous, outperforming both global and local models. Furthermore, our framework gives strict privacy guarantees, which allows clients to select parts of their data that may be excluded from the federation. The evaluation shows that the proposed solution is robust to the setting where some users require a strict privacy setting and do not disclose their models to a central server at all, opting out from the federation partially or entirely. The proposed framework is general enough to include any kind of machine learning models, and can even use combinations of different kinds.
Adaptive Blending Units: Trainable Activation Functions for Deep Neural Networks
Jun 26, 2018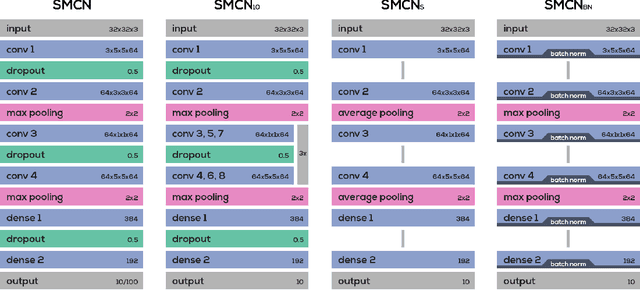
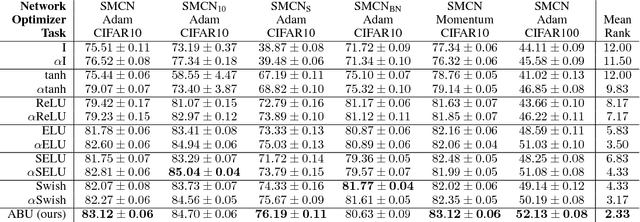
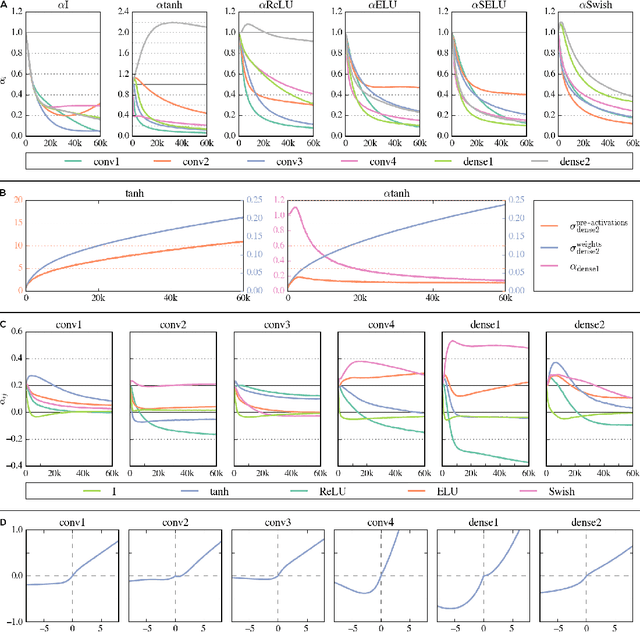

The most widely used activation functions in current deep feed-forward neural networks are rectified linear units (ReLU), and many alternatives have been successfully applied, as well. However, none of the alternatives have managed to consistently outperform the rest and there is no unified theory connecting properties of the task and network with properties of activation functions for most efficient training. A possible solution is to have the network learn its preferred activation functions. In this work, we introduce Adaptive Blending Units (ABUs), a trainable linear combination of a set of activation functions. Since ABUs learn the shape, as well as the overall scaling of the activation function, we also analyze the effects of adaptive scaling in common activation functions. We experimentally demonstrate advantages of both adaptive scaling and ABUs over common activation functions across a set of systematically varied network specifications. We further show that adaptive scaling works by mitigating covariate shifts during training, and that the observed advantages in performance of ABUs likewise rely largely on the activation function's ability to adapt over the course of training.