 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Heterogeneous and Private Label Sets
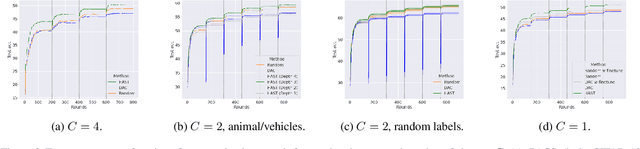
Aug 26, 2025Although common in real-world applications, heterogeneous client label sets are rarely investigated in federated learning (FL). Furthermore, in the cases they are, clients are assumed to be willing to share their entire label sets with other clients. Federated learning with private label sets, shared only with the central server, adds further constraints on learning algorithms and is, in general, a more difficult problem to solve. In this work, we study the effects of label set heterogeneity on model performance, comparing the public and private label settings -- when the union of label sets in the federation is known to clients and when it is not. We apply classical methods for the classifier combination problem to FL using centralized tuning, adapt common FL methods to the private label set setting, and discuss the justification of both approaches under practical assumptions. Our experiments show that reducing the number of labels available to each client harms the performance of all methods substantially. Centralized tuning of client models for representational alignment can help remedy this, but often at the cost of higher variance. Throughout, our proposed adaptations of standard FL methods perform well, showing similar performance in the private label setting as the standard methods achieve in the public setting. This shows that clients can enjoy increased privacy at little cost to model accuracy.
Overcoming label shift in targeted federated learning
Nov 06, 2024



Federated learning enables multiple actors to collaboratively train models without sharing private data. This unlocks the potential for scaling machine learning to diverse applications. Existing algorithms for this task are well-justified when clients and the intended target domain share the same distribution of features and labels, but this assumption is often violated in real-world scenarios. One common violation is label shift, where the label distributions differ across clients or between clients and the target domain, which can significantly degrade model performance. To address this problem, we propose FedPALS, a novel model aggregation scheme that adapts to label shifts by leveraging knowledge of the target label distribution at the central server. Our approach ensures unbiased updates under stochastic gradient descent, ensuring robust generalization across clients with diverse, label-shifted data. Extensive experiments on image classification demonstrate that FedPALS consistently outperforms standard baselines by aligning model aggregation with the target domain. Our findings reveal that conventional federated learning methods suffer severely in cases of extreme client sparsity, highlighting the critical need for target-aware aggregation. FedPALS offers a principled and practical solution to mitigate label distribution mismatch, ensuring models trained in federated settings can generalize effectively to label-shifted target domains.
On the effects of similarity metrics in decentralized deep learning under distributional shift
Sep 16, 2024Decentralized Learning (DL) enables privacy-preserving collaboration among organizations or users to enhance the performance of local deep learning models. However, model aggregation becomes challenging when client data is heterogeneous, and identifying compatible collaborators without direct data exchange remains a pressing issue. In this paper, we investigate the effectiveness of various similarity metrics in DL for identifying peers for model merging, conducting an empirical analysis across multiple datasets with distribution shifts. Our research provides insights into the performance of these metrics, examining their role in facilitating effective collaboration. By exploring the strengths and limitations of these metrics, we contribute to the development of robust DL methods.
Impacts of Color and Texture Distortions on Earth Observation Data in Deep Learning
Mar 07, 2024



Land cover classification and change detection are two important applications of remote sensing and Earth observation (EO) that have benefited greatly from the advances of deep learning. Convolutional and transformer-based U-net models are the state-of-the-art architectures for these tasks, and their performances have been boosted by an increased availability of large-scale annotated EO datasets. However, the influence of different visual characteristics of the input EO data on a model's predictions is not well understood. In this work we systematically examine model sensitivities with respect to several color- and texture-based distortions on the input EO data during inference, given models that have been trained without such distortions. We conduct experiments with multiple state-of-the-art segmentation networks for land cover classification and show that they are in general more sensitive to texture than to color distortions. Beyond revealing intriguing characteristics of widely used land cover classification models, our results can also be used to guide the development of more robust models within the EO domain.
Concept-aware clustering for decentralized deep learning under temporal shift
Jun 22, 2023
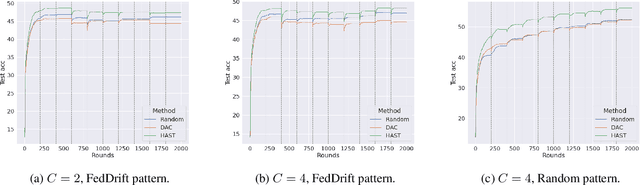
Decentralized deep learning requires dealing with non-iid data across clients, which may also change over time due to temporal shifts. While non-iid data has been extensively studied in distributed settings, temporal shifts have received no attention. To the best of our knowledge, we are first with tackling the novel and challenging problem of decentralized learning with non-iid and dynamic data. We propose a novel algorithm that can automatically discover and adapt to the evolving concepts in the network, without any prior knowledge or estimation of the number of concepts. We evaluate our algorithm on standard benchmark datasets and demonstrate that it outperforms previous methods for decentralized learning.
Grammatical gender in Swedish is predictable using recurrent neural networks
Jun 19, 2023



The grammatical gender of Swedish nouns is a mystery. While there are few rules that can indicate the gender with some certainty, it does in general not depend on either meaning or the structure of the word. In this paper we demonstrate the surprising fact that grammatical gender for Swedish nouns can be predicted with high accuracy using a recurrent neural network (RNN) working on the raw character sequence of the word, without using any contextual information.
Private Node Selection in Personalized Decentralized Learning
Jan 30, 2023



In this paper, we propose a novel approach for privacy-preserving node selection in personalized decentralized learning, which we refer to as Private Personalized Decentralized Learning (PPDL). Our method mitigates the risk of inference attacks through the use of secure aggregation while simultaneously enabling efficient identification of collaborators. This is achieved by leveraging adversarial multi-armed bandit optimization that exploits dependencies between the different arms. Through comprehensive experimentation on various benchmarks under label and covariate shift, we demonstrate that our privacy-preserving approach outperforms previous non-private methods in terms of model performance.
EFFGAN: Ensembles of fine-tuned federated GANs
Jun 23, 2022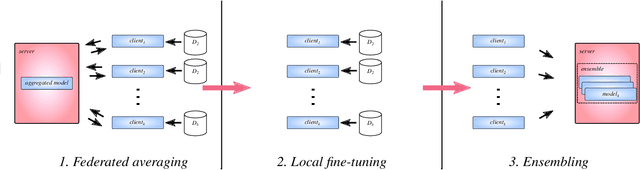


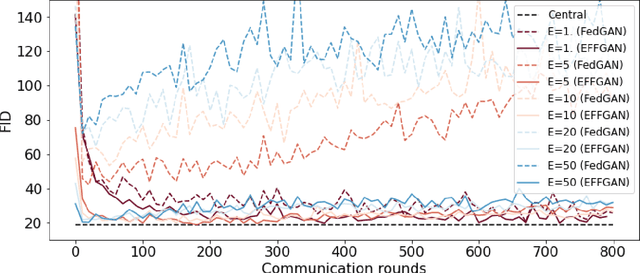
Generative adversarial networks have proven to be a powerful tool for learning complex and high-dimensional data distributions, but issues such as mode collapse have been shown to make it difficult to train them. This is an even harder problem when the data is decentralized over several clients in a federated learning setup, as problems such as client drift and non-iid data make it hard for federated averaging to converge. In this work, we study the task of how to learn a data distribution when training data is heterogeneously decentralized over clients and cannot be shared. Our goal is to sample from this distribution centrally, while the data never leaves the clients. We show using standard benchmark image datasets that existing approaches fail in this setting, experiencing so-called client drift when the local number of epochs becomes to large. We thus propose a novel approach we call EFFGAN: Ensembles of fine-tuned federated GANs. Being an ensemble of local expert generators, EFFGAN is able to learn the data distribution over all clients and mitigate client drift. It is able to train with a large number of local epochs, making it more communication efficient than previous works.
Decentralized adaptive clustering of deep nets is beneficial for client collaboration
Jun 17, 2022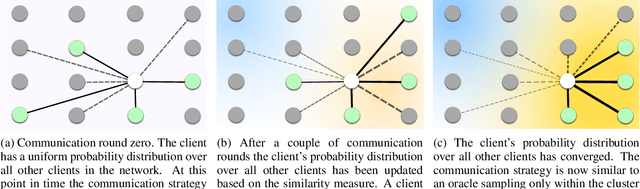
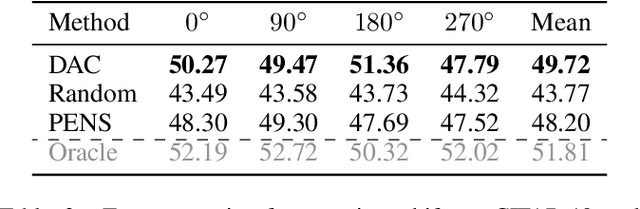
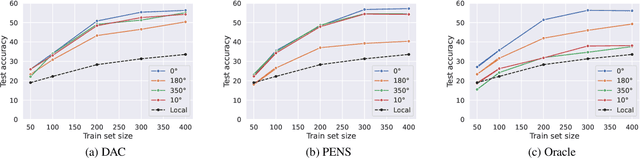

We study the problem of training personalized deep learning models in a decentralized peer-to-peer setting, focusing on the setting where data distributions differ between the clients and where different clients have different local learning tasks. We study both covariate and label shift, and our contribution is an algorithm which for each client finds beneficial collaborations based on a similarity estimate for the local task. Our method does not rely on hyperparameters which are hard to estimate, such as the number of client clusters, but rather continuously adapts to the network topology using soft cluster assignment based on a novel adaptive gossip algorithm. We test the proposed method in various settings where data is not independent and identically distributed among the clients. The experimental evaluation shows that the proposed method performs better than previous state-of-the-art algorithms for this problem setting, and handles situations well where previous methods fail.
Adaptive Expert Models for Personalization in Federated Learning
Jun 15, 2022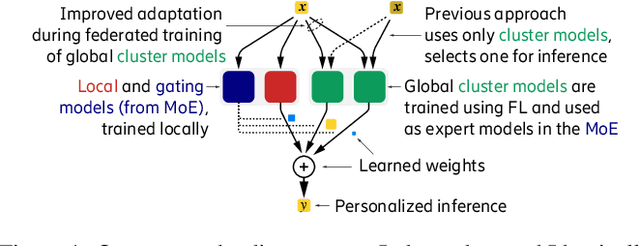

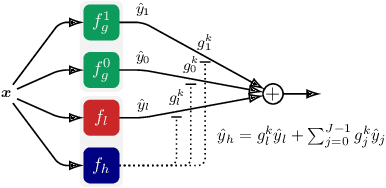
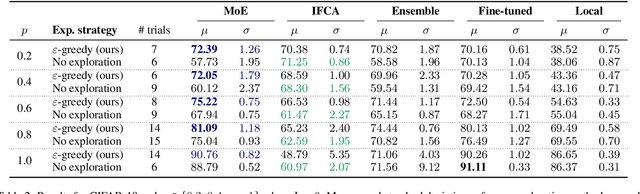
Federated Learning (FL) is a promising framework for distributed learning when data is private and sensitive. However, the state-of-the-art solutions in this framework are not optimal when data is heterogeneous and non-Independent and Identically Distributed (non-IID). We propose a practical and robust approach to personalization in FL that adjusts to heterogeneous and non-IID data by balancing exploration and exploitation of several global models. To achieve our aim of personalization, we use a Mixture of Experts (MoE) that learns to group clients that are similar to each other, while using the global models more efficiently. We show that our approach achieves an accuracy up to 29.78 % and up to 4.38 % better compared to a local model in a pathological non-IID setting, even though we tune our approach in the IID setting.