 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to restart? Exploring escalating restarts on convergence
Mar 04, 2026Learning rate scheduling plays a critical role in the optimization of deep neural networks, directly influencing convergence speed, stability, and generalization. While existing schedulers such as cosine annealing, cyclical learning rates, and warm restarts have shown promise, they often rely on fixed or periodic triggers that are agnostic to the training dynamics, such as stagnation or convergence behavior. In this work, we propose a simple yet effective strategy, which we call Stochastic Gradient Descent with Escalating Restarts (SGD-ER). It adaptively increases the learning rate upon convergence. Our method monitors training progress and triggers restarts when stagnation is detected, linearly escalating the learning rate to escape sharp local minima and explore flatter regions of the loss landscape. We evaluate SGD-ER across CIFAR-10, CIFAR-100, and TinyImageNet on a range of architectures including ResNet-18/34/50, VGG-16, and DenseNet-101. Compared to standard schedulers, SGD-ER improves test accuracy by 0.5-4.5%, demonstrating the benefit of convergence-aware escalating restarts for better local optima.
Adaptive Graph Pruning with Sudden-Events Evaluation for Traffic Prediction using Online Semi-Decentralized ST-GNNs
Dec 19, 2025Spatio-Temporal Graph Neural Networks (ST-GNNs) are well-suited for processing high-frequency data streams from geographically distributed sensors in smart mobility systems. However, their deployment at the edge across distributed compute nodes (cloudlets) createssubstantial communication overhead due to repeated transmission of overlapping node features between neighbouring cloudlets. To address this, we propose an adaptive pruning algorithm that dynamically filters redundant neighbour features while preserving the most informative spatial context for prediction. The algorithm adjusts pruning rates based on recent model performance, allowing each cloudlet to focus on regions experiencing traffic changes without compromising accuracy. Additionally, we introduce the Sudden Event Prediction Accuracy (SEPA), a novel event-focused metric designed to measure responsiveness to traffic slowdowns and recoveries, which are often missed by standard error metrics. We evaluate our approach in an online semi-decentralized setting with traditional FL, server-free FL, and Gossip Learning on two large-scale traffic datasets, PeMS-BAY and PeMSD7-M, across short-, mid-, and long-term prediction horizons. Experiments show that, in contrast to standard metrics, SEPA exposes the true value of spatial connectivity in predicting dynamic and irregular traffic. Our adaptive pruning algorithm maintains prediction accuracy while significantly lowering communication cost in all online semi-decentralized settings, demonstrating that communication can be reduced without compromising responsiveness to critical traffic events.
Semi-decentralized Training of Spatio-Temporal Graph Neural Networks for Traffic Prediction
Dec 04, 2024In smart mobility, large networks of geographically distributed sensors produce vast amounts of high-frequency spatio-temporal data that must be processed in real time to avoid major disruptions. Traditional centralized approaches are increasingly unsuitable to this task, as they struggle to scale with expanding sensor networks, and reliability issues in central components can easily affect the whole deployment. To address these challenges, we explore and adapt semi-decentralized training techniques for Spatio-Temporal Graph Neural Networks (ST-GNNs) in smart mobility domain. We implement a simulation framework where sensors are grouped by proximity into multiple cloudlets, each handling a subgraph of the traffic graph, fetching node features from other cloudlets to train its own local ST-GNN model, and exchanging model updates with other cloudlets to ensure consistency, enhancing scalability and removing reliance on a centralized aggregator. We perform extensive comparative evaluation of four different ST-GNN training setups -- centralized, traditional FL, server-free FL, and Gossip Learning -- on large-scale traffic datasets, the METR-LA and PeMS-BAY datasets, for short-, mid-, and long-term vehicle speed predictions. Experimental results show that semi-decentralized setups are comparable to centralized approaches in performance metrics, while offering advantages in terms of scalability and fault tolerance. In addition, we highlight often overlooked issues in existing literature for distributed ST-GNNs, such as the variation in model performance across different geographical areas due to region-specific traffic patterns, and the significant communication overhead and computational costs that arise from the large receptive field of GNNs, leading to substantial data transfers and increased computation of partial embeddings.
Adaptive Expert Models for Personalization in Federated Learning
Jun 15, 2022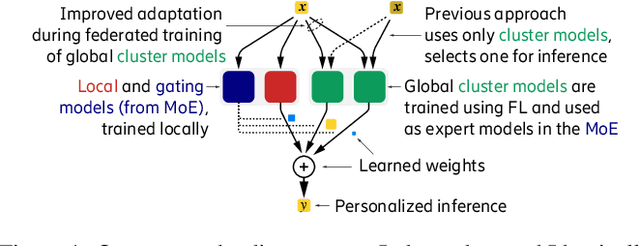

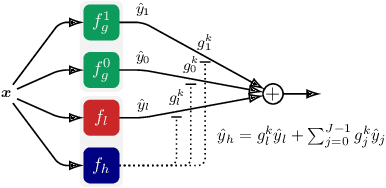
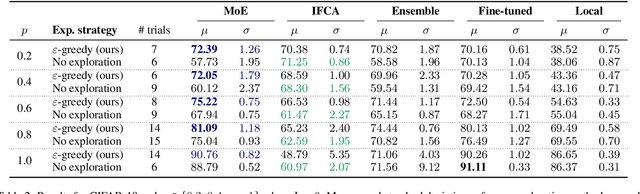
Federated Learning (FL) is a promising framework for distributed learning when data is private and sensitive. However, the state-of-the-art solutions in this framework are not optimal when data is heterogeneous and non-Independent and Identically Distributed (non-IID). We propose a practical and robust approach to personalization in FL that adjusts to heterogeneous and non-IID data by balancing exploration and exploitation of several global models. To achieve our aim of personalization, we use a Mixture of Experts (MoE) that learns to group clients that are similar to each other, while using the global models more efficiently. We show that our approach achieves an accuracy up to 29.78 % and up to 4.38 % better compared to a local model in a pathological non-IID setting, even though we tune our approach in the IID setting.