 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeap: Inductive Link Prediction via Learnable TopologyAugmentation
Mar 05, 2025Link prediction is a crucial task in many downstream applications of graph machine learning. To this end, Graph Neural Network (GNN) is a widely used technique for link prediction, mainly in transductive settings, where the goal is to predict missing links between existing nodes. However, many real-life applications require an inductive setting that accommodates for new nodes, coming into an existing graph. Thus, recently inductive link prediction has attracted considerable attention, and a multi-layer perceptron (MLP) is the popular choice of most studies to learn node representations. However, these approaches have limited expressivity and do not fully capture the graph's structural signal. Therefore, in this work we propose LEAP, an inductive link prediction method based on LEArnable toPology augmentation. Unlike previous methods, LEAP models the inductive bias from both the structure and node features, and hence is more expressive. To the best of our knowledge, this is the first attempt to provide structural contexts for new nodes via learnable augmentation in inductive settings. Extensive experiments on seven real-world homogeneous and heterogeneous graphs demonstrates that LEAP significantly surpasses SOTA methods. The improvements are up to 22\% and 17\% in terms of AUC and average precision, respectively. The code and datasets are available on GitHub (https://github.com/AhmedESamy/LEAP/)
SANDWICH: Towards an Offline, Differentiable, Fully-Trainable Wireless Neural Ray-Tracing Surrogate
Nov 13, 2024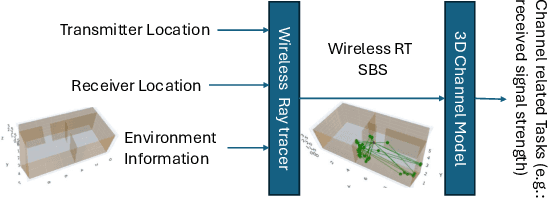
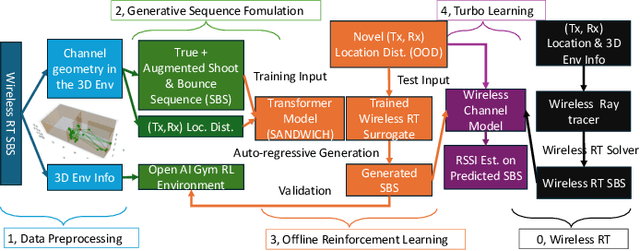
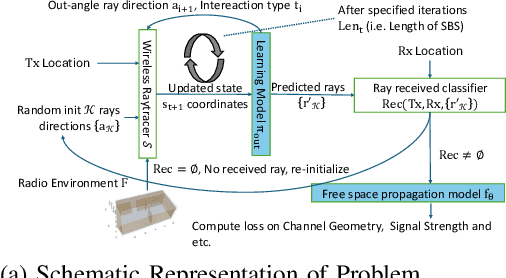
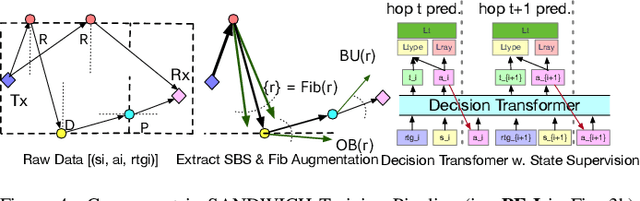
Wireless ray-tracing (RT) is emerging as a key tool for three-dimensional (3D) wireless channel modeling, driven by advances in graphical rendering. Current approaches struggle to accurately model beyond 5G (B5G) network signaling, which often operates at higher frequencies and is more susceptible to environmental conditions and changes. Existing online learning solutions require real-time environmental supervision during training, which is both costly and incompatible with GPU-based processing. In response, we propose a novel approach that redefines ray trajectory generation as a sequential decision-making problem, leveraging generative models to jointly learn the optical, physical, and signal properties within each designated environment. Our work introduces the Scene-Aware Neural Decision Wireless Channel Raytracing Hierarchy (SANDWICH), an innovative offline, fully differentiable approach that can be trained entirely on GPUs. SANDWICH offers superior performance compared to existing online learning methods, outperforms the baseline by 4e^-2 radian in RT accuracy, and only fades 0.5 dB away from toplined channel gain estimation.
On the effects of similarity metrics in decentralized deep learning under distributional shift
Sep 16, 2024Decentralized Learning (DL) enables privacy-preserving collaboration among organizations or users to enhance the performance of local deep learning models. However, model aggregation becomes challenging when client data is heterogeneous, and identifying compatible collaborators without direct data exchange remains a pressing issue. In this paper, we investigate the effectiveness of various similarity metrics in DL for identifying peers for model merging, conducting an empirical analysis across multiple datasets with distribution shifts. Our research provides insights into the performance of these metrics, examining their role in facilitating effective collaboration. By exploring the strengths and limitations of these metrics, we contribute to the development of robust DL methods.
Are We Wasting Time? A Fast, Accurate Performance Evaluation Framework for Knowledge Graph Link Predictors
Jan 25, 2024The standard evaluation protocol for measuring the quality of Knowledge Graph Completion methods - the task of inferring new links to be added to a graph - typically involves a step which ranks every entity of a Knowledge Graph to assess their fit as a head or tail of a candidate link to be added. In Knowledge Graphs on a larger scale, this task rapidly becomes prohibitively heavy. Previous approaches mitigate this problem by using random sampling of entities to assess the quality of links predicted or suggested by a method. However, we show that this approach has serious limitations since the ranking metrics produced do not properly reflect true outcomes. In this paper, we present a thorough analysis of these effects along with the following findings. First, we empirically find and theoretically motivate why sampling uniformly at random vastly overestimates the ranking performance of a method. We show that this can be attributed to the effect of easy versus hard negative candidates. Second, we propose a framework that uses relational recommenders to guide the selection of candidates for evaluation. We provide both theoretical and empirical justification of our methodology, and find that simple and fast methods can work extremely well, and that they match advanced neural approaches. Even when a large portion of true candidates for a property are missed, the estimation barely deteriorates. With our proposed framework, we can reduce the time and computation needed similar to random sampling strategies while vastly improving the estimation; on ogbl-wikikg2, we show that accurate estimations of the full, filtered ranking can be obtained in 20 seconds instead of 30 minutes. We conclude that considerable computational effort can be saved by effective preprocessing and sampling methods and still reliably predict performance accurately of the true performance for the entire ranking procedure.
Learning Cellular Coverage from Real Network Configurations using GNNs
Apr 20, 2023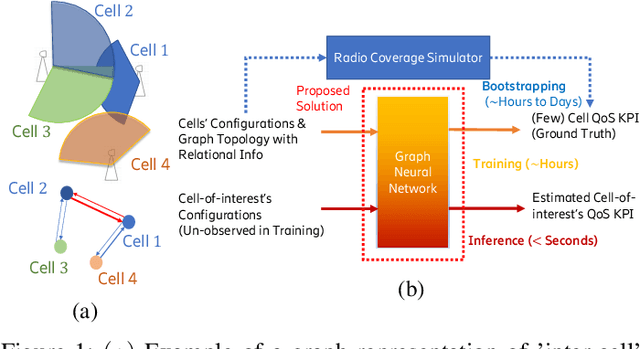
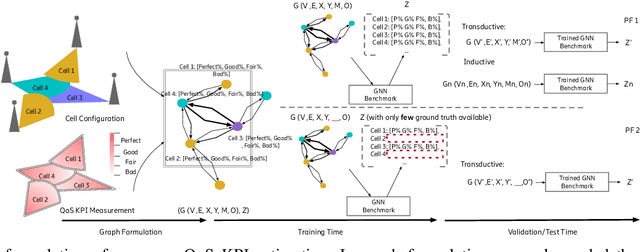
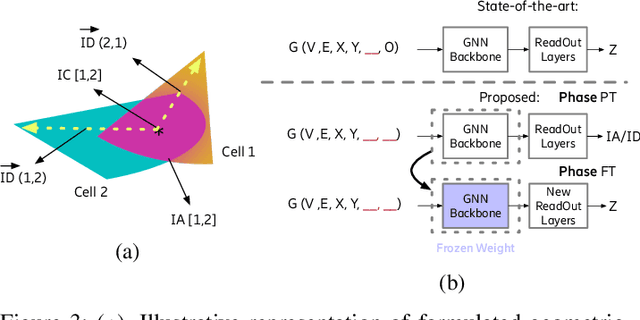
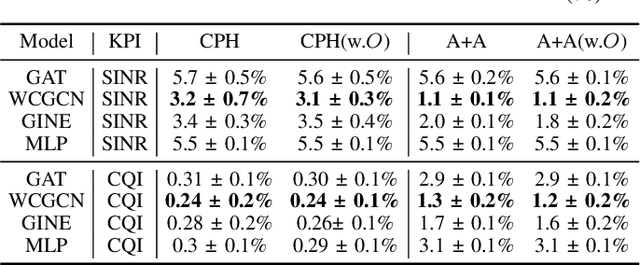
Cellular coverage quality estimation has been a critical task for self-organized networks. In real-world scenarios, deep-learning-powered coverage quality estimation methods cannot scale up to large areas due to little ground truth can be provided during network design & optimization. In addition they fall short in produce expressive embeddings to adequately capture the variations of the cells' configurations. To deal with this challenge, we formulate the task in a graph representation and so that we can apply state-of-the-art graph neural networks, that show exemplary performance. We propose a novel training framework that can both produce quality cell configuration embeddings for estimating multiple KPIs, while we show it is capable of generalising to large (area-wide) scenarios given very few labeled cells. We show that our framework yields comparable accuracy with models that have been trained using massively labeled samples.
Decentralized adaptive clustering of deep nets is beneficial for client collaboration
Jun 17, 2022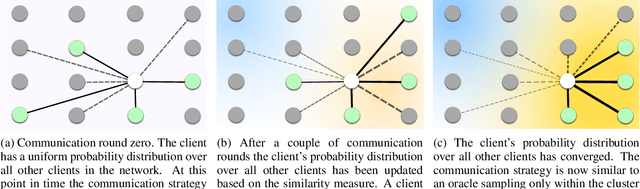
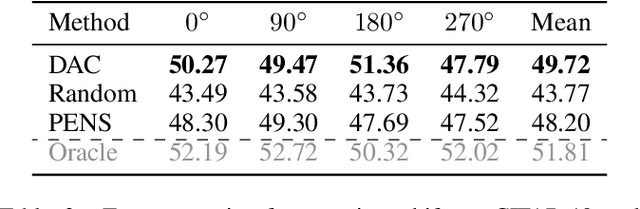
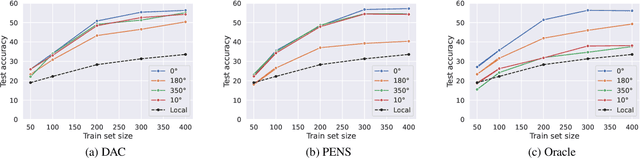

We study the problem of training personalized deep learning models in a decentralized peer-to-peer setting, focusing on the setting where data distributions differ between the clients and where different clients have different local learning tasks. We study both covariate and label shift, and our contribution is an algorithm which for each client finds beneficial collaborations based on a similarity estimate for the local task. Our method does not rely on hyperparameters which are hard to estimate, such as the number of client clusters, but rather continuously adapts to the network topology using soft cluster assignment based on a novel adaptive gossip algorithm. We test the proposed method in various settings where data is not independent and identically distributed among the clients. The experimental evaluation shows that the proposed method performs better than previous state-of-the-art algorithms for this problem setting, and handles situations well where previous methods fail.
Jointly Learnable Data Augmentations for Self-Supervised GNNs
Aug 23, 2021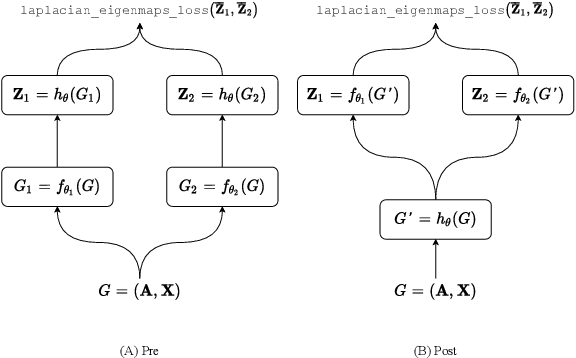

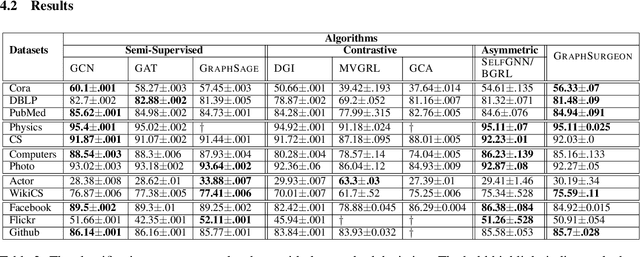

Self-supervised Learning (SSL) aims at learning representations of objects without relying on manual labeling. Recently, a number of SSL methods for graph representation learning have achieved performance comparable to SOTA semi-supervised GNNs. A Siamese network, which relies on data augmentation, is the popular architecture used in these methods. However, these methods rely on heuristically crafted data augmentation techniques. Furthermore, they use either contrastive terms or other tricks (e.g., asymmetry) to avoid trivial solutions that can occur in Siamese networks. In this study, we propose, GraphSurgeon, a novel SSL method for GNNs with the following features. First, instead of heuristics we propose a learnable data augmentation method that is jointly learned with the embeddings by leveraging the inherent signal encoded in the graph. In addition, we take advantage of the flexibility of the learnable data augmentation and introduce a new strategy that augments in the embedding space, called post augmentation. This strategy has a significantly lower memory overhead and run-time cost. Second, as it is difficult to sample truly contrastive terms, we avoid explicit negative sampling. Third, instead of relying on engineering tricks, we use a scalable constrained optimization objective motivated by Laplacian Eigenmaps to avoid trivial solutions. To validate the practical use of GraphSurgeon, we perform empirical evaluation using 14 public datasets across a number of domains and ranging from small to large scale graphs with hundreds of millions of edges. Our finding shows that GraphSurgeon is comparable to six SOTA semi-supervised and on par with five SOTA self-supervised baselines in node classification tasks. The source code is available at https://github.com/zekarias-tilahun/graph-surgeon.
A Deep Graph Reinforcement Learning Model for Improving User Experience in Live Video Streaming
Jul 28, 2021



In this paper we present a deep graph reinforcement learning model to predict and improve the user experience during a live video streaming event, orchestrated by an agent/tracker. We first formulate the user experience prediction problem as a classification task, accounting for the fact that most of the viewers at the beginning of an event have poor quality of experience due to low-bandwidth connections and limited interactions with the tracker. In our model we consider different factors that influence the quality of user experience and train the proposed model on diverse state-action transitions when viewers interact with the tracker. In addition, provided that past events have various user experience characteristics we follow a gradient boosting strategy to compute a global model that learns from different events. Our experiments with three real-world datasets of live video streaming events demonstrate the superiority of the proposed model against several baseline strategies. Moreover, as the majority of the viewers at the beginning of an event has poor experience, we show that our model can significantly increase the number of viewers with high quality experience by at least 75% over the first streaming minutes. Our evaluation datasets and implementation are publicly available at https://publicresearch.z13.web.core.windows.net
Federated Word2Vec: Leveraging Federated Learning to Encourage Collaborative Representation Learning
Apr 19, 2021
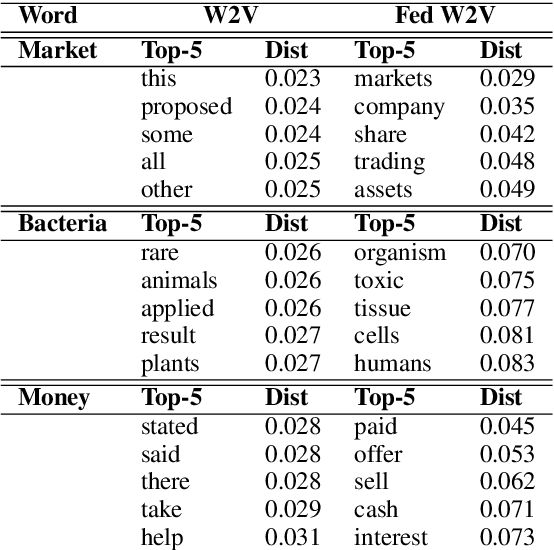
Large scale contextual representation models have significantly advanced NLP in recent years, understanding the semantics of text to a degree never seen before. However, they need to process large amounts of data to achieve high-quality results. Joining and accessing all these data from multiple sources can be extremely challenging due to privacy and regulatory reasons. Federated Learning can solve these limitations by training models in a distributed fashion, taking advantage of the hardware of the devices that generate the data. We show the viability of training NLP models, specifically Word2Vec, with the Federated Learning protocol. In particular, we focus on a scenario in which a small number of organizations each hold a relatively large corpus. The results show that neither the quality of the results nor the convergence time in Federated Word2Vec deteriorates as compared to centralised Word2Vec.
Self-supervised Graph Neural Networks without explicit negative sampling
Apr 09, 2021
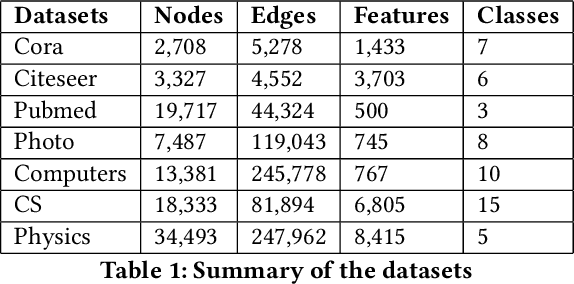

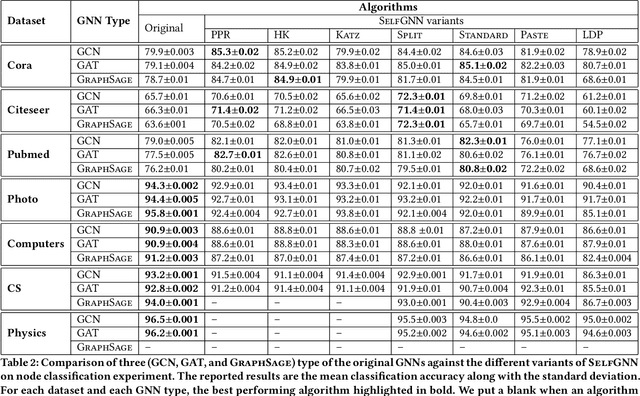
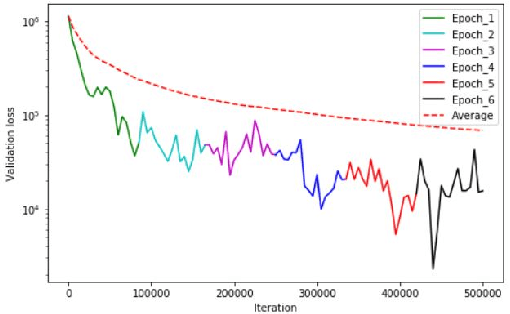
Real world data is mostly unlabeled or only few instances are labeled. Manually labeling data is a very expensive and daunting task. This calls for unsupervised learning techniques that are powerful enough to achieve comparable results as semi-supervised/supervised techniques. Contrastive self-supervised learning has emerged as a powerful direction, in some cases outperforming supervised techniques. In this study, we propose, SelfGNN, a novel contrastive self-supervised graph neural network (GNN) without relying on explicit contrastive terms. We leverage Batch Normalization, which introduces implicit contrastive terms, without sacrificing performance. Furthermore, as data augmentation is key in contrastive learning, we introduce four feature augmentation (FA) techniques for graphs. Though graph topological augmentation (TA) is commonly used, our empirical findings show that FA perform as good as TA. Moreover, FA incurs no computational overhead, unlike TA, which often has O(N^3) time complexity, N-number of nodes. Our empirical evaluation on seven publicly available real-world data shows that, SelfGNN is powerful and leads to a performance comparable with SOTA supervised GNNs and always better than SOTA semi-supervised and unsupervised GNNs. The source code is available at https://github.com/zekarias-tilahun/SelfGNN.