 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Voltage Drop: Models, Features and Data Representation Towards a Neural Surrogate
Feb 07, 2025



Accurate estimation of voltage drop (IR drop) in modern Application-Specific Integrated Circuits (ASICs) is highly time and resource demanding, due to the growing complexity and the transistor density in recent technology nodes. To mitigate this challenge, we investigate how Machine Learning (ML) techniques, including Extreme Gradient Boosting (XGBoost), Convolutional Neural Network (CNN), and Graph Neural Network (GNN) can aid in reducing the computational effort and implicitly the time required to estimate the IR drop in Integrated Circuits (ICs). Traditional methods, including commercial tools, require considerable time to produce accurate approximations, especially for complicated designs with numerous transistors. ML algorithms, on the other hand, are explored as an alternative solution to offer quick and precise IR drop estimation, but in considerably less time. Our approach leverages ASICs' electrical, timing, and physical to train ML models, ensuring adaptability across diverse designs with minimal adjustments. Experimental results underscore the superiority of ML models over commercial tools, greatly enhancing prediction speed. Particularly, GNNs exhibit promising performance with minimal prediction errors in voltage drop estimation. The incorporation of GNNs marks a groundbreaking advancement in accurate IR drop prediction. This study illustrates the effectiveness of ML algorithms in precisely estimating IR drop and optimizing ASIC sign-off. Utilizing ML models leads to expedited predictions, reducing calculation time and improving energy efficiency, thereby reducing environmental impact through optimized power circuits.
Learning Cellular Coverage from Real Network Configurations using GNNs
Apr 20, 2023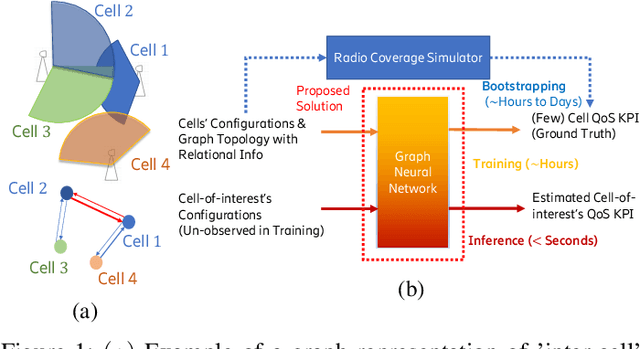
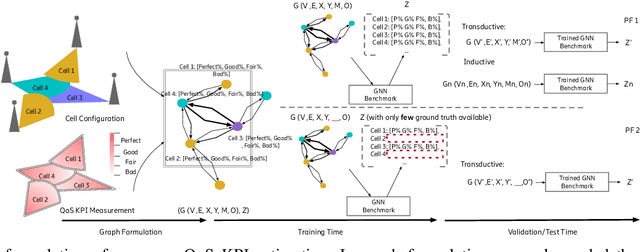
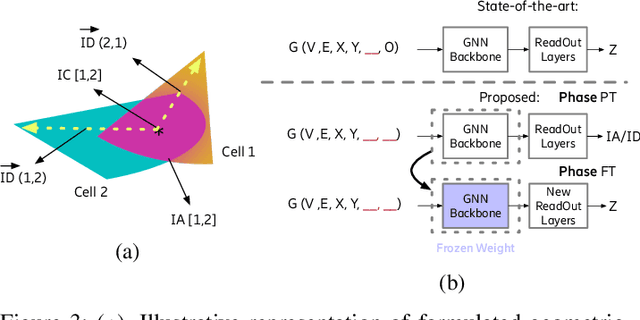
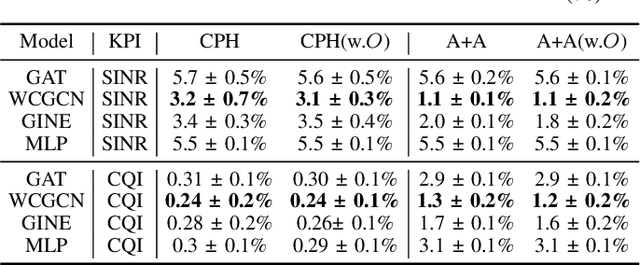
Cellular coverage quality estimation has been a critical task for self-organized networks. In real-world scenarios, deep-learning-powered coverage quality estimation methods cannot scale up to large areas due to little ground truth can be provided during network design & optimization. In addition they fall short in produce expressive embeddings to adequately capture the variations of the cells' configurations. To deal with this challenge, we formulate the task in a graph representation and so that we can apply state-of-the-art graph neural networks, that show exemplary performance. We propose a novel training framework that can both produce quality cell configuration embeddings for estimating multiple KPIs, while we show it is capable of generalising to large (area-wide) scenarios given very few labeled cells. We show that our framework yields comparable accuracy with models that have been trained using massively labeled samples.
Unsupervised Key-phrase Extraction and Clustering for Classification Scheme in Scientific Publications
Feb 08, 2021



Several methods have been explored for automating parts of Systematic Mapping (SM) and Systematic Review (SR) methodologies. Challenges typically evolve around the gaps in semantic understanding of text, as well as lack of domain and background knowledge necessary to bridge that gap. In this paper we investigate possible ways of automating parts of the SM/SR process, i.e. that of extracting keywords and key-phrases from scientific documents using unsupervised methods, which are then used as a basis to construct the corresponding Classification Scheme using semantic key-phrase clustering techniques. Specifically, we explore the effect of ensemble scores measure in key-phrase extraction, we explore semantic network based word embedding in embedding representation of phrase semantics and finally we also explore how clustering can be used to group related key-phrases. The evaluation is conducted on a dataset of publications pertaining the domain of "Explainable AI" which we constructed using standard publicly available digital libraries and sets of indexing terms (keywords). Results shows that: ensemble ranking score does improve the key-phrase extraction performance. Semantic-network based word embedding based on the ConceptNet Semantic Network has similar performance with contextualized word embedding, however the former are computationally more efficient. Finally Semantic key-phrase clustering at term-level can group similar terms together that can be suitable for classification scheme.