 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSidelink Positioning: Standardization Advancements, Challenges and Opportunities
Dec 31, 2025With the integration of cellular networks in vertical industries that demand precise location information, such as vehicle-to-everything (V2X), public safety, and Industrial Internet of Things (IIoT), positioning has become an imperative component for future wireless networks. By exploiting a wider spectrum, multiple antennas and flexible architectures, cellular positioning achieves ever-increasing positioning accuracy. Still, it faces fundamental performance degradation when the distance between user equipment (UE) and the base station (BS) is large or in non-line-of-sight (NLoS) scenarios. To this end, the 3rd generation partnership project (3GPP) Rel-18 proposes to standardize sidelink (SL) positioning, which provides unique opportunities to extend the positioning coverage via direct positioning signaling between UEs. Despite the standardization advancements, the capability of SL positioning is controversial, especially how much spectrum is required to achieve the positioning accuracy defined in 3GPP. To this end, this article summarizes the latest standardization advancements of 3GPP on SL positioning comprehensively, covering a) network architecture; b) positioning types; and c) performance requirements. The capability of SL positioning using various positioning methods under different imperfect factors is evaluated and discussed in-depth. Finally, according to the evolution of SL in 3GPP Rel-19, we discuss the possible research directions and challenges of SL positioning.
Adaptive Sentencing Prediction with Guaranteed Accuracy and Legal Interpretability
May 20, 2025Existing research on judicial sentencing prediction predominantly relies on end-to-end models, which often neglect the inherent sentencing logic and lack interpretability-a critical requirement for both scholarly research and judicial practice. To address this challenge, we make three key contributions:First, we propose a novel Saturated Mechanistic Sentencing (SMS) model, which provides inherent legal interpretability by virtue of its foundation in China's Criminal Law. We also introduce the corresponding Momentum Least Mean Squares (MLMS) adaptive algorithm for this model. Second, for the MLMS algorithm based adaptive sentencing predictor, we establish a mathematical theory on the accuracy of adaptive prediction without resorting to any stationarity and independence assumptions on the data. We also provide a best possible upper bound for the prediction accuracy achievable by the best predictor designed in the known parameters case. Third, we construct a Chinese Intentional Bodily Harm (CIBH) dataset. Utilizing this real-world data, extensive experiments demonstrate that our approach achieves a prediction accuracy that is not far from the best possible theoretical upper bound, validating both the model's suitability and the algorithm's accuracy.
Estimating Voltage Drop: Models, Features and Data Representation Towards a Neural Surrogate
Feb 07, 2025



Accurate estimation of voltage drop (IR drop) in modern Application-Specific Integrated Circuits (ASICs) is highly time and resource demanding, due to the growing complexity and the transistor density in recent technology nodes. To mitigate this challenge, we investigate how Machine Learning (ML) techniques, including Extreme Gradient Boosting (XGBoost), Convolutional Neural Network (CNN), and Graph Neural Network (GNN) can aid in reducing the computational effort and implicitly the time required to estimate the IR drop in Integrated Circuits (ICs). Traditional methods, including commercial tools, require considerable time to produce accurate approximations, especially for complicated designs with numerous transistors. ML algorithms, on the other hand, are explored as an alternative solution to offer quick and precise IR drop estimation, but in considerably less time. Our approach leverages ASICs' electrical, timing, and physical to train ML models, ensuring adaptability across diverse designs with minimal adjustments. Experimental results underscore the superiority of ML models over commercial tools, greatly enhancing prediction speed. Particularly, GNNs exhibit promising performance with minimal prediction errors in voltage drop estimation. The incorporation of GNNs marks a groundbreaking advancement in accurate IR drop prediction. This study illustrates the effectiveness of ML algorithms in precisely estimating IR drop and optimizing ASIC sign-off. Utilizing ML models leads to expedited predictions, reducing calculation time and improving energy efficiency, thereby reducing environmental impact through optimized power circuits.
SANDWICH: Towards an Offline, Differentiable, Fully-Trainable Wireless Neural Ray-Tracing Surrogate
Nov 13, 2024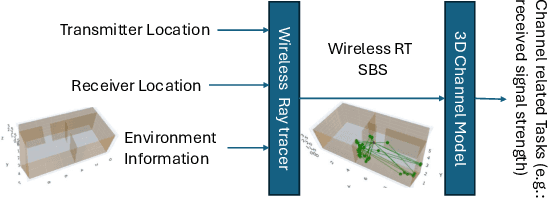
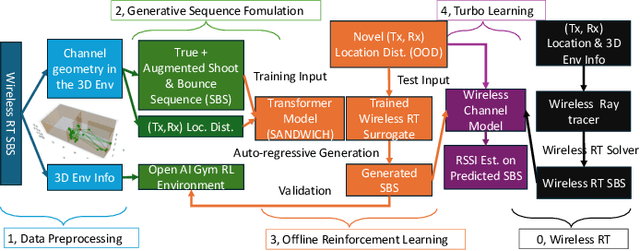
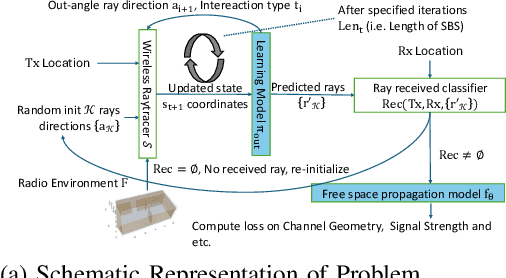
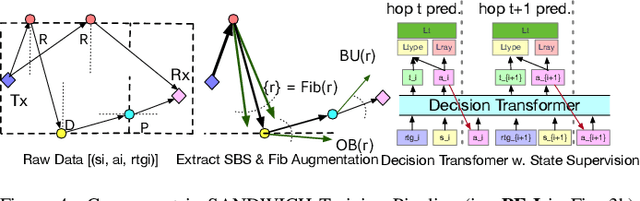
Wireless ray-tracing (RT) is emerging as a key tool for three-dimensional (3D) wireless channel modeling, driven by advances in graphical rendering. Current approaches struggle to accurately model beyond 5G (B5G) network signaling, which often operates at higher frequencies and is more susceptible to environmental conditions and changes. Existing online learning solutions require real-time environmental supervision during training, which is both costly and incompatible with GPU-based processing. In response, we propose a novel approach that redefines ray trajectory generation as a sequential decision-making problem, leveraging generative models to jointly learn the optical, physical, and signal properties within each designated environment. Our work introduces the Scene-Aware Neural Decision Wireless Channel Raytracing Hierarchy (SANDWICH), an innovative offline, fully differentiable approach that can be trained entirely on GPUs. SANDWICH offers superior performance compared to existing online learning methods, outperforms the baseline by 4e^-2 radian in RT accuracy, and only fades 0.5 dB away from toplined channel gain estimation.
Are We Wasting Time? A Fast, Accurate Performance Evaluation Framework for Knowledge Graph Link Predictors
Jan 25, 2024The standard evaluation protocol for measuring the quality of Knowledge Graph Completion methods - the task of inferring new links to be added to a graph - typically involves a step which ranks every entity of a Knowledge Graph to assess their fit as a head or tail of a candidate link to be added. In Knowledge Graphs on a larger scale, this task rapidly becomes prohibitively heavy. Previous approaches mitigate this problem by using random sampling of entities to assess the quality of links predicted or suggested by a method. However, we show that this approach has serious limitations since the ranking metrics produced do not properly reflect true outcomes. In this paper, we present a thorough analysis of these effects along with the following findings. First, we empirically find and theoretically motivate why sampling uniformly at random vastly overestimates the ranking performance of a method. We show that this can be attributed to the effect of easy versus hard negative candidates. Second, we propose a framework that uses relational recommenders to guide the selection of candidates for evaluation. We provide both theoretical and empirical justification of our methodology, and find that simple and fast methods can work extremely well, and that they match advanced neural approaches. Even when a large portion of true candidates for a property are missed, the estimation barely deteriorates. With our proposed framework, we can reduce the time and computation needed similar to random sampling strategies while vastly improving the estimation; on ogbl-wikikg2, we show that accurate estimations of the full, filtered ranking can be obtained in 20 seconds instead of 30 minutes. We conclude that considerable computational effort can be saved by effective preprocessing and sampling methods and still reliably predict performance accurately of the true performance for the entire ranking procedure.
Learning Cellular Coverage from Real Network Configurations using GNNs
Apr 20, 2023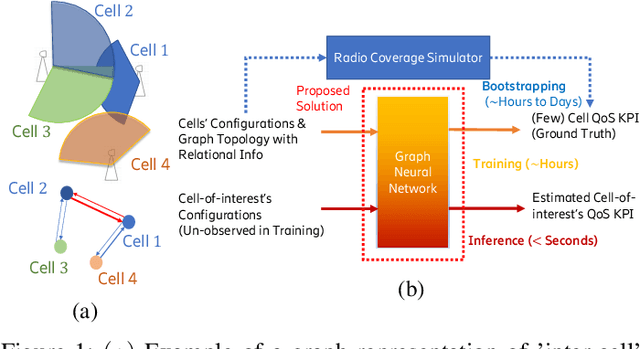
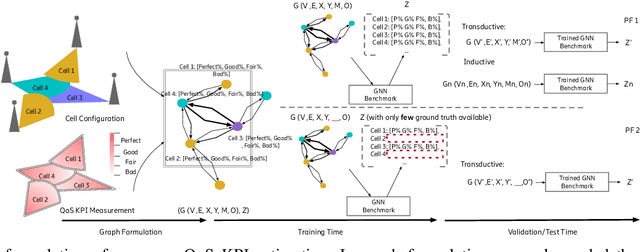
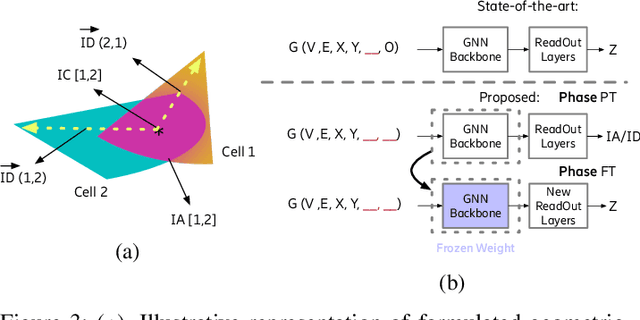
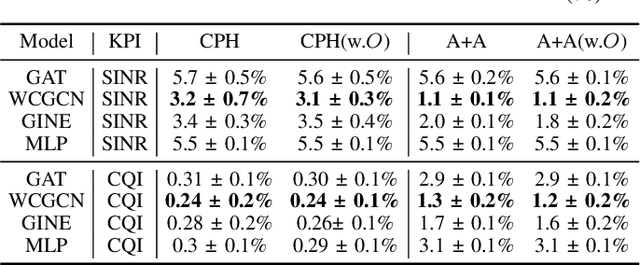
Cellular coverage quality estimation has been a critical task for self-organized networks. In real-world scenarios, deep-learning-powered coverage quality estimation methods cannot scale up to large areas due to little ground truth can be provided during network design & optimization. In addition they fall short in produce expressive embeddings to adequately capture the variations of the cells' configurations. To deal with this challenge, we formulate the task in a graph representation and so that we can apply state-of-the-art graph neural networks, that show exemplary performance. We propose a novel training framework that can both produce quality cell configuration embeddings for estimating multiple KPIs, while we show it is capable of generalising to large (area-wide) scenarios given very few labeled cells. We show that our framework yields comparable accuracy with models that have been trained using massively labeled samples.
A Graph Attention Learning Approach to Antenna Tilt Optimization
Dec 27, 2021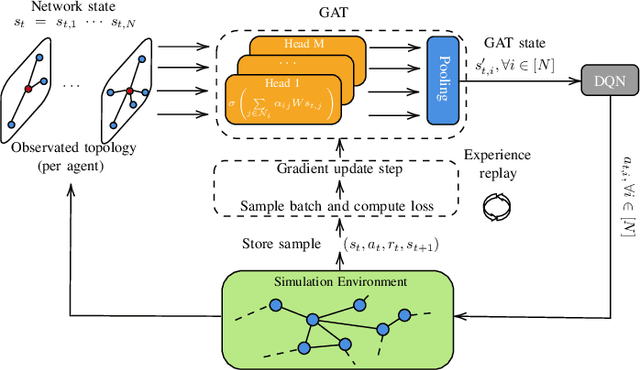
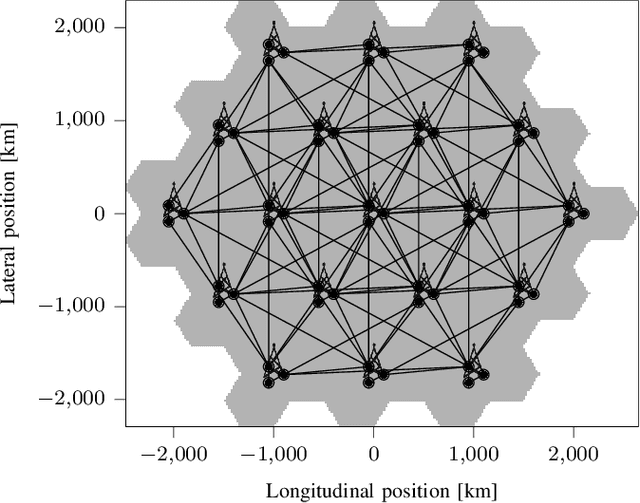
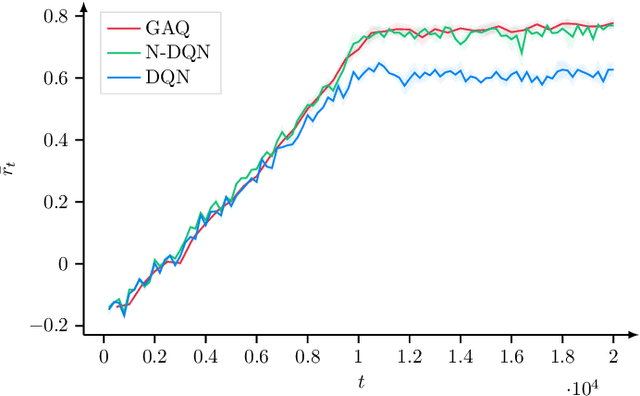

6G will move mobile networks towards increasing levels of complexity. To deal with this complexity, optimization of network parameters is key to ensure high performance and timely adaptivity to dynamic network environments. The optimization of the antenna tilt provides a practical and cost-efficient method to improve coverage and capacity in the network. Previous methods based on Reinforcement Learning (RL) have shown great promise for tilt optimization by learning adaptive policies outperforming traditional tilt optimization methods. However, most existing RL methods are based on single-cell features representation, which fails to fully characterize the agent state, resulting in suboptimal performance. Also, most of such methods lack scalability, due to state-action explosion, and generalization ability. In this paper, we propose a Graph Attention Q-learning (GAQ) algorithm for tilt optimization. GAQ relies on a graph attention mechanism to select relevant neighbors information, improve the agent state representation, and update the tilt control policy based on a history of observations using a Deep Q-Network (DQN). We show that GAQ efficiently captures important network information and outperforms standard DQN with local information by a large margin. In addition, we demonstrate its ability to generalize to network deployments of different sizes and densities.
DoubleEnsemble: A New Ensemble Method Based on Sample Reweighting and Feature Selection for Financial Data Analysis
Oct 03, 2020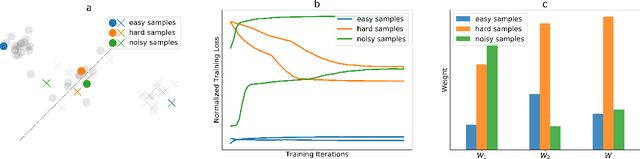
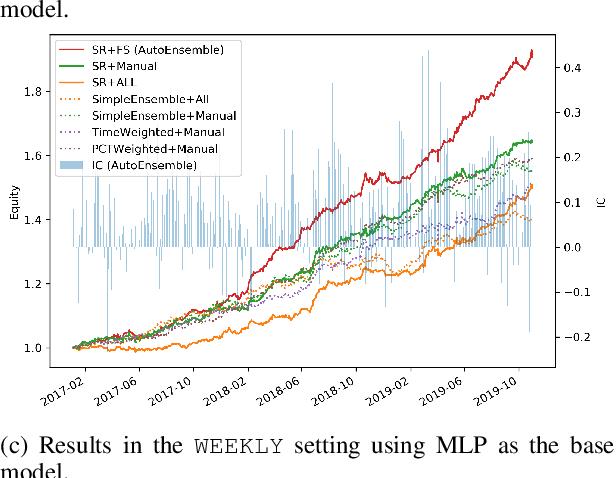
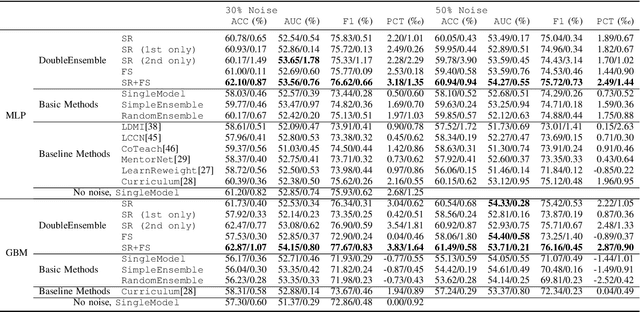
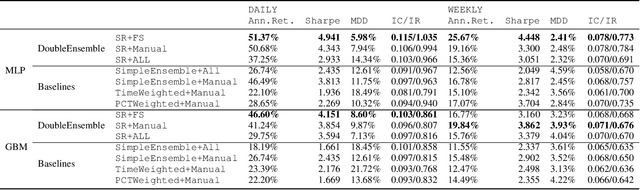
Modern machine learning models (such as deep neural networks and boosting decision tree models) have become increasingly popular in financial market prediction, due to their superior capacity to extract complex non-linear patterns. However, since financial datasets have very low signal-to-noise ratio and are non-stationary, complex models are often very prone to overfitting and suffer from instability issues. Moreover, as various machine learning and data mining tools become more widely used in quantitative trading, many trading firms have been producing an increasing number of features (aka factors). Therefore, how to automatically select effective features becomes an imminent problem. To address these issues, we propose DoubleEnsemble, an ensemble framework leveraging learning trajectory based sample reweighting and shuffling based feature selection. Specifically, we identify the key samples based on the training dynamics on each sample and elicit key features based on the ablation impact of each feature via shuffling. Our model is applicable to a wide range of base models, capable of extracting complex patterns, while mitigating the overfitting and instability issues for financial market prediction. We conduct extensive experiments, including price prediction for cryptocurrencies and stock trading, using both DNN and gradient boosting decision tree as base models. Our experiment results demonstrate that DoubleEnsemble achieves a superior performance compared with several baseline methods.
SVM via Saddle Point Optimization: New Bounds and Distributed Algorithms
Jan 28, 2018
We study two important SVM variants: hard-margin SVM (for linearly separable cases) and $\nu$-SVM (for linearly non-separable cases). We propose new algorithms from the perspective of saddle point optimization. Our algorithms achieve $(1-\epsilon)$-approximations with running time $\tilde{O}(nd+n\sqrt{d / \epsilon})$ for both variants, where $n$ is the number of points and $d$ is the dimensionality. To the best of our knowledge, the current best algorithm for $\nu$-SVM is based on quadratic programming approach which requires $\Omega(n^2 d)$ time in worst case~\cite{joachims1998making,platt199912}. In the paper, we provide the first nearly linear time algorithm for $\nu$-SVM. The current best algorithm for hard margin SVM achieved by Gilbert algorithm~\cite{gartner2009coresets} requires $O(nd / \epsilon )$ time. Our algorithm improves the running time by a factor of $\sqrt{d}/\sqrt{\epsilon}$. Moreover, our algorithms can be implemented in the distributed settings naturally. We prove that our algorithms require $\tilde{O}(k(d +\sqrt{d/\epsilon}))$ communication cost, where $k$ is the number of clients, which almost matches the theoretical lower bound. Numerical experiments support our theory and show that our algorithms converge faster on high dimensional, large and dense data sets, as compared to previous methods.