 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Antenna Tilt Control Policies: A Contextual Linear Bandit Approach
Jan 06, 2022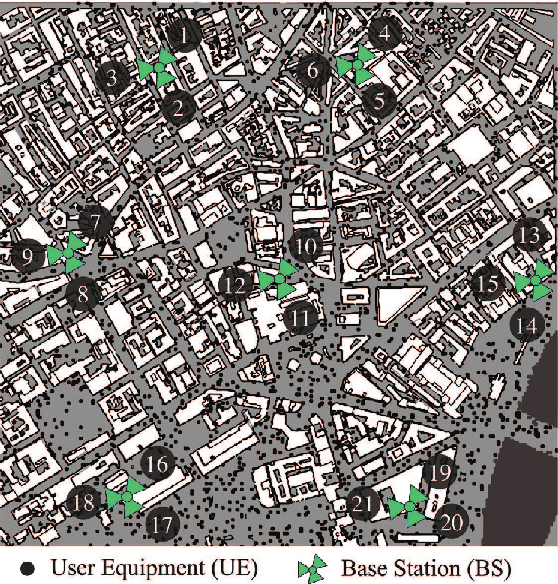
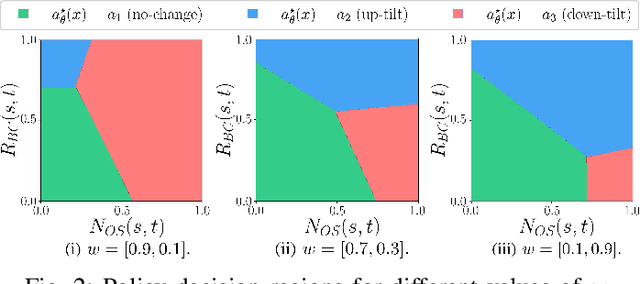
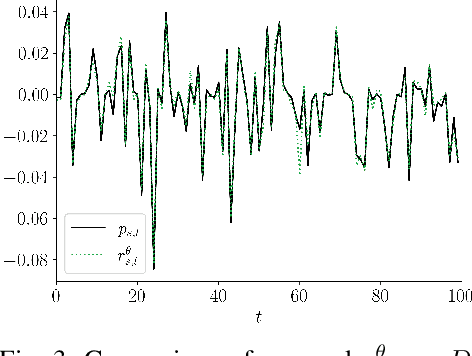
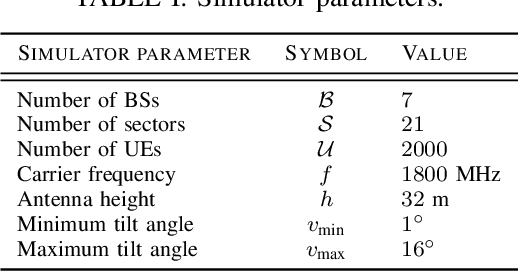
Controlling antenna tilts in cellular networks is imperative to reach an efficient trade-off between network coverage and capacity. In this paper, we devise algorithms learning optimal tilt control policies from existing data (in the so-called passive learning setting) or from data actively generated by the algorithms (the active learning setting). We formalize the design of such algorithms as a Best Policy Identification (BPI) problem in Contextual Linear Multi-Arm Bandits (CL-MAB). An arm represents an antenna tilt update; the context captures current network conditions; the reward corresponds to an improvement of performance, mixing coverage and capacity; and the objective is to identify, with a given level of confidence, an approximately optimal policy (a function mapping the context to an arm with maximal reward). For CL-MAB in both active and passive learning settings, we derive information-theoretical lower bounds on the number of samples required by any algorithm returning an approximately optimal policy with a given level of certainty, and devise algorithms achieving these fundamental limits. We apply our algorithms to the Remote Electrical Tilt (RET) optimization problem in cellular networks, and show that they can produce optimal tilt update policy using much fewer data samples than naive or existing rule-based learning algorithms.
A Graph Attention Learning Approach to Antenna Tilt Optimization
Dec 27, 2021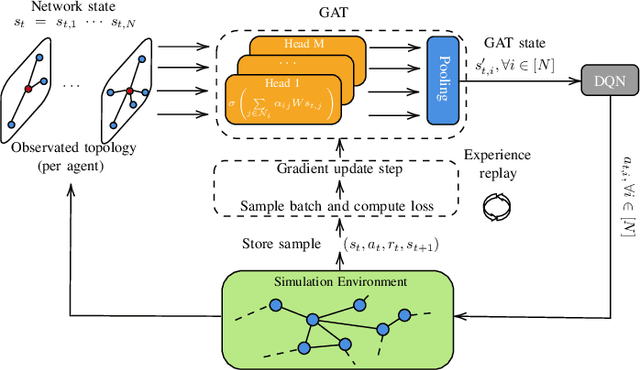
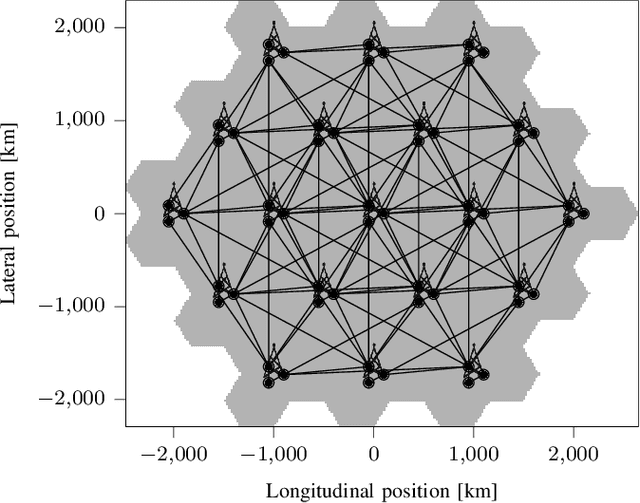
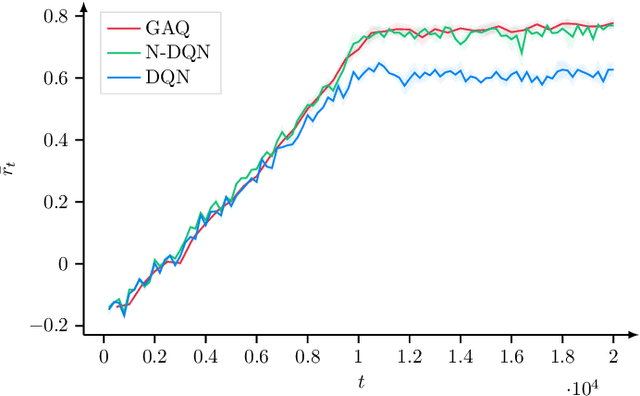

6G will move mobile networks towards increasing levels of complexity. To deal with this complexity, optimization of network parameters is key to ensure high performance and timely adaptivity to dynamic network environments. The optimization of the antenna tilt provides a practical and cost-efficient method to improve coverage and capacity in the network. Previous methods based on Reinforcement Learning (RL) have shown great promise for tilt optimization by learning adaptive policies outperforming traditional tilt optimization methods. However, most existing RL methods are based on single-cell features representation, which fails to fully characterize the agent state, resulting in suboptimal performance. Also, most of such methods lack scalability, due to state-action explosion, and generalization ability. In this paper, we propose a Graph Attention Q-learning (GAQ) algorithm for tilt optimization. GAQ relies on a graph attention mechanism to select relevant neighbors information, improve the agent state representation, and update the tilt control policy based on a history of observations using a Deep Q-Network (DQN). We show that GAQ efficiently captures important network information and outperforms standard DQN with local information by a large margin. In addition, we demonstrate its ability to generalize to network deployments of different sizes and densities.
Fueling the Next Quantum Leap in Cellular Networks: Embracing AI in 5G Evolution towards 6G
Nov 20, 2021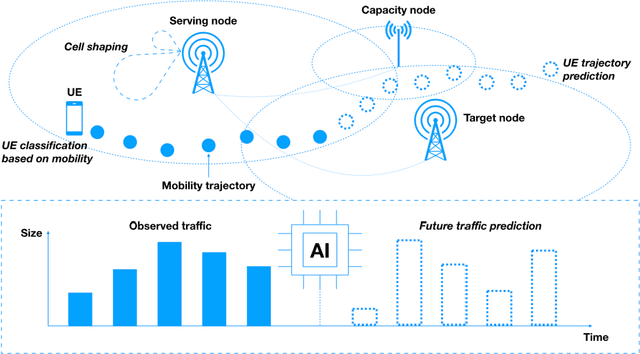
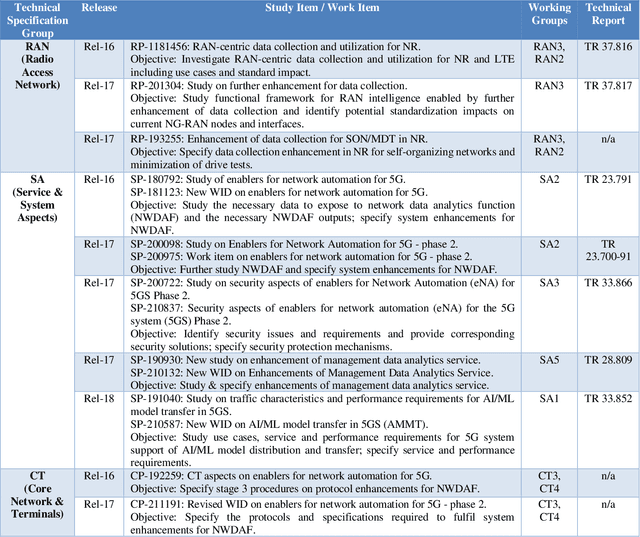
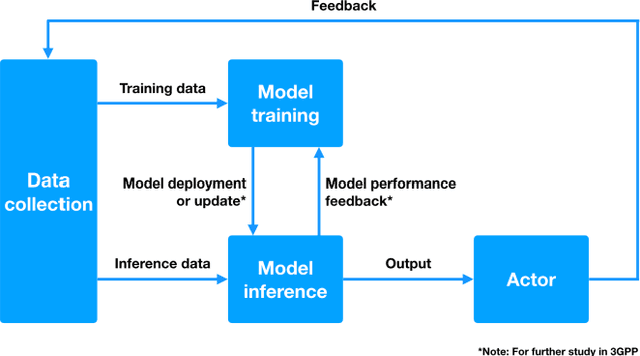
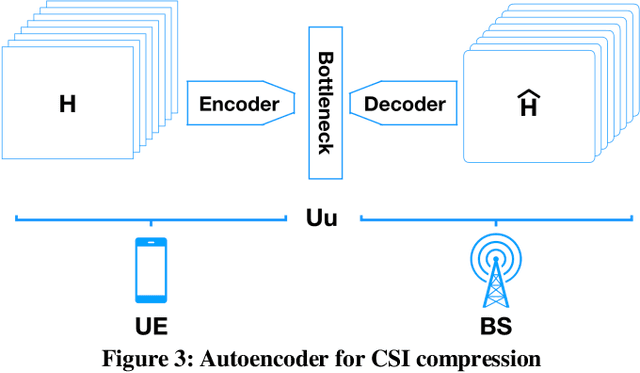
Cellular networks, such as 5G systems, are becoming increasingly complex for supporting various deployment scenarios and applications. Embracing artificial intelligence (AI) in 5G evolution is critical to managing the complexity and fueling the next quantum leap in 6G cellular networks. In this article, we share our experience and best practices in applying AI in cellular networks. We first present a primer on the state of the art of AI in cellular networks, including basic concepts and recent key advances. Then we discuss 3GPP standardization aspects and share various design rationales influencing standardization. We also present case studies with real network data to showcase how AI can improve network performance and enable network automation.
Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems
Sep 10, 2021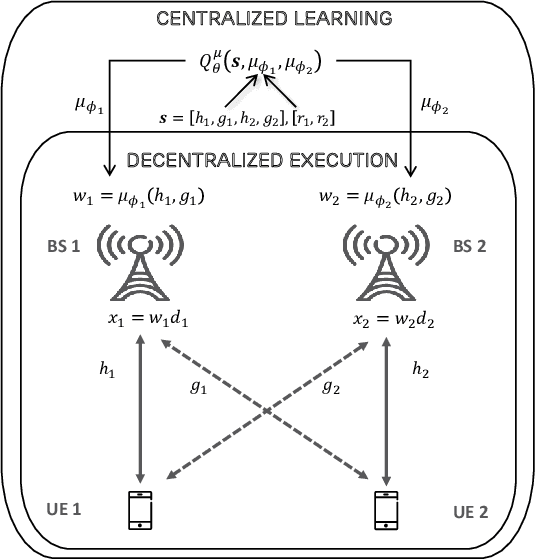
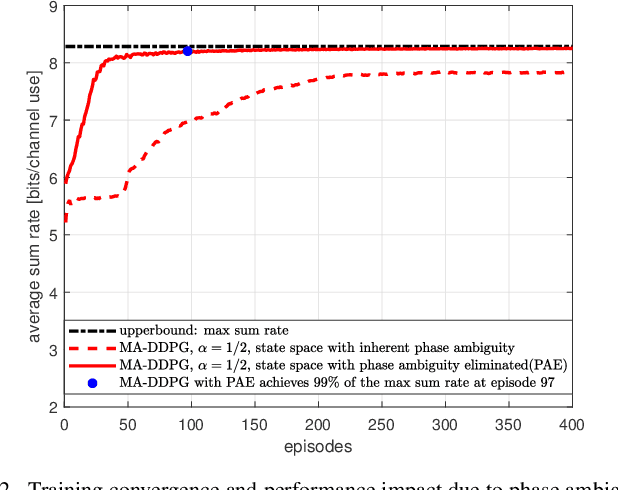
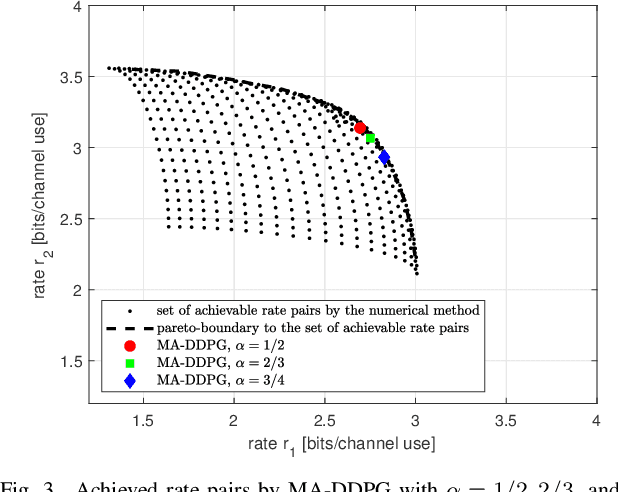

A multi-agent deep reinforcement learning (MADRL) is a promising approach to challenging problems in wireless environments involving multiple decision-makers (or actors) with high-dimensional continuous action space. In this paper, we present a MADRL-based approach that can jointly optimize precoders to achieve the outer-boundary, called pareto-boundary, of the achievable rate region for a multiple-input single-output (MISO) interference channel (IFC). In order to address two main challenges, namely, multiple actors (or agents) with partial observability and multi-dimensional continuous action space in MISO IFC setup, we adopt a multi-agent deep deterministic policy gradient (MA-DDPG) framework in which decentralized actors with partial observability can learn a multi-dimensional continuous policy in a centralized manner with the aid of shared critic with global information. Meanwhile, we will also address a phase ambiguity issue with the conventional complex baseband representation of signals widely used in radio communications. In order to mitigate the impact of phase ambiguity on training performance, we propose a training method, called phase ambiguity elimination (PAE), that leads to faster learning and better performance of MA-DDPG in wireless communication systems. The simulation results exhibit that MA-DDPG is capable of learning a near-optimal precoding strategy in a MISO IFC environment. To the best of our knowledge, this is the first work to demonstrate that the MA-DDPG framework can jointly optimize precoders to achieve the pareto-boundary of achievable rate region in a multi-cell multi-user multi-antenna system.
Deep reinforcement learning approach to MIMO precoding problem: Optimality and Robustness
Jun 30, 2020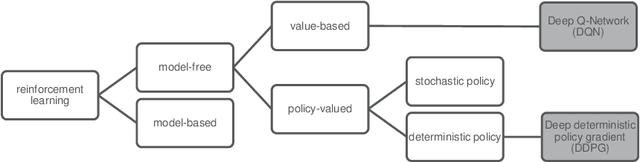

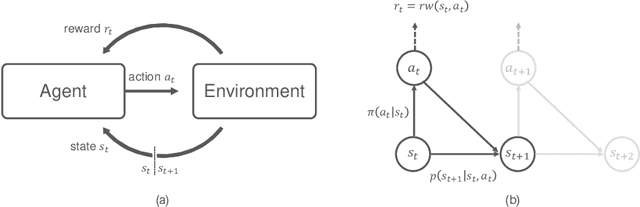
In this paper, we propose a deep reinforcement learning (RL)-based precoding framework that can be used to learn an optimal precoding policy for complex multiple-input multiple-output (MIMO) precoding problems. We model the precoding problem for a single-user MIMO system as an RL problem in which a learning agent sequentially selects the precoders to serve the environment of MIMO system based on contextual information about the environmental conditions, while simultaneously adapting the precoder selection policy based on the reward feedback from the environment to maximize a numerical reward signal. We develop the RL agent with two canonical deep RL (DRL) algorithms, namely deep Q-network (DQN) and deep deterministic policy gradient (DDPG). To demonstrate the optimality of the proposed DRL-based precoding framework, we explicitly consider a simple MIMO environment for which the optimal solution can be obtained analytically and show that DQN- and DDPG-based agents can learn the near-optimal policy to map the environment state of MIMO system to a precoder that maximizes the reward function, respectively, in the codebook-based and non-codebook based MIMO precoding systems. Furthermore, to investigate the robustness of DRL-based precoding framework, we examine the performance of the two DRL algorithms in a complex MIMO environment, for which the optimal solution is not known. The numerical results confirm the effectiveness of the DRL-based precoding framework and show that the proposed DRL-based framework can outperform the conventional approximation algorithm in the complex MIMO environment.
Off-policy Learning for Remote Electrical Tilt Optimization
May 21, 2020
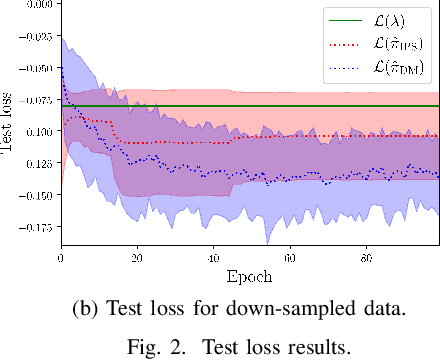
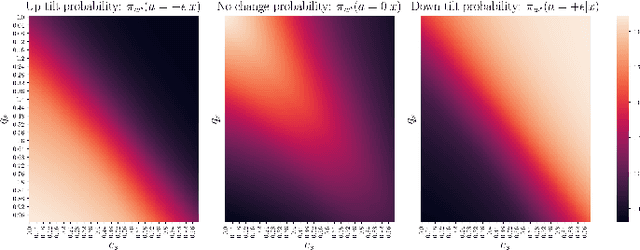

We address the problem of Remote Electrical Tilt (RET) optimization using off-policy Contextual Multi-Armed-Bandit (CMAB) techniques. The goal in RET optimization is to control the orientation of the vertical tilt angle of the antenna to optimize Key Performance Indicators (KPIs) representing the Quality of Service (QoS) perceived by the users in cellular networks. Learning an improved tilt update policy is hard. On the one hand, coming up with a new policy in an online manner in a real network requires exploring tilt updates that have never been used before, and is operationally too risky. On the other hand, devising this policy via simulations suffers from the simulation-to-reality gap. In this paper, we circumvent these issues by learning an improved policy in an offline manner using existing data collected on real networks. We formulate the problem of devising such a policy using the off-policy CMAB framework. We propose CMAB learning algorithms to extract optimal tilt update policies from the data. We train and evaluate these policies on real-world 4G Long Term Evolution (LTE) cellular network data. Our policies show consistent improvements over the rule-based logging policy used to collect the data.
Cluster-Aided Mobility Predictions
Jan 21, 2016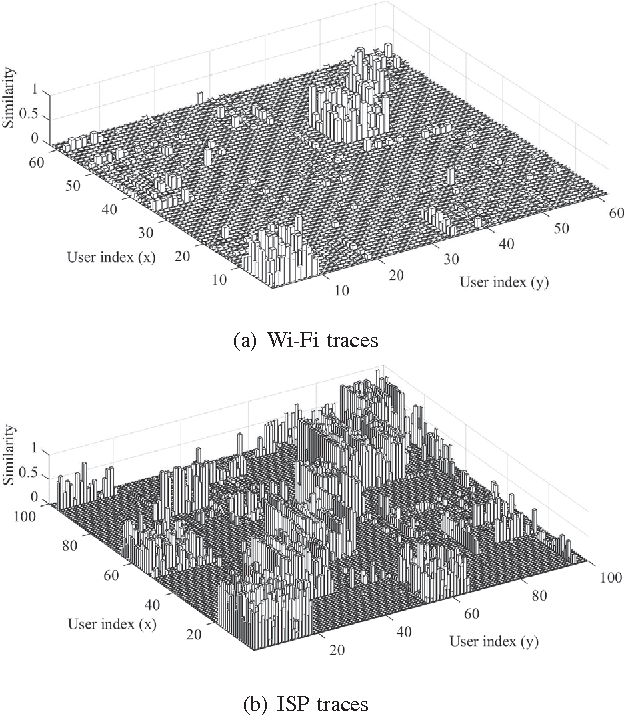
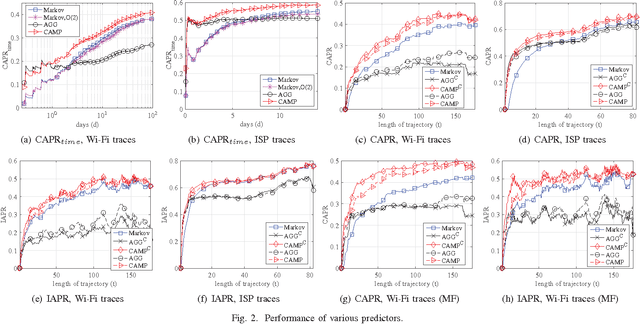
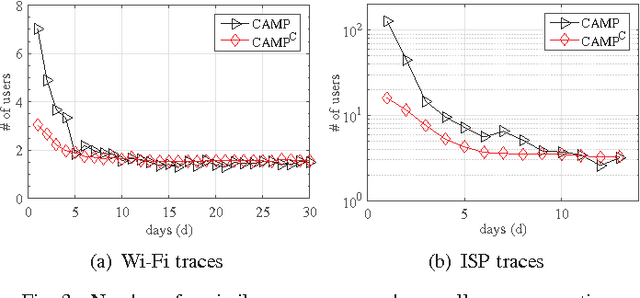
Predicting the future location of users in wireless net- works has numerous applications, and can help service providers to improve the quality of service perceived by their clients. The location predictors proposed so far estimate the next location of a specific user by inspecting the past individual trajectories of this user. As a consequence, when the training data collected for a given user is limited, the resulting prediction is inaccurate. In this paper, we develop cluster-aided predictors that exploit past trajectories collected from all users to predict the next location of a given user. These predictors rely on clustering techniques and extract from the training data similarities among the mobility patterns of the various users to improve the prediction accuracy. Specifically, we present CAMP (Cluster-Aided Mobility Predictor), a cluster-aided predictor whose design is based on recent non-parametric bayesian statistical tools. CAMP is robust and adaptive in the sense that it exploits similarities in users' mobility only if such similarities are really present in the training data. We analytically prove the consistency of the predictions provided by CAMP, and investigate its performance using two large-scale datasets. CAMP significantly outperforms existing predictors, and in particular those that only exploit individual past trajectories.