 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Based Residual Policy Learning with Applications to Antenna Control
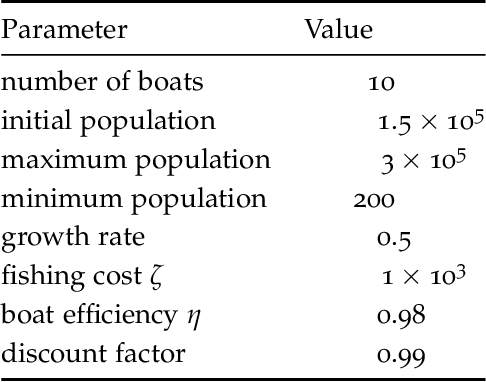
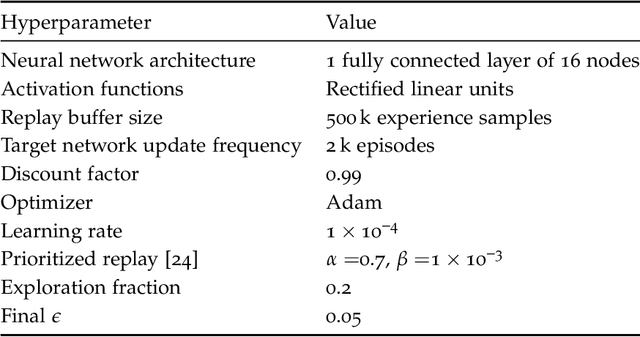
Nov 21, 2022Non-differentiable controllers and rule-based policies are widely used for controlling real systems such as robots and telecommunication networks. In this paper, we present a practical reinforcement learning method which improves upon such existing policies with a model-based approach for better sample efficiency. Our method significantly outperforms state-of-the-art model-based methods, in terms of sample efficiency, on several widely used robotic benchmark tasks. We also demonstrate the effectiveness of our approach on a control problem in the telecommunications domain, where model-based methods have not previously been explored. Experimental results indicate that a strong initial performance can be achieved and combined with improved sample efficiency. We further motivate the design of our algorithm with a theoretical lower bound on the performance.
A Graph Attention Learning Approach to Antenna Tilt Optimization
Dec 27, 2021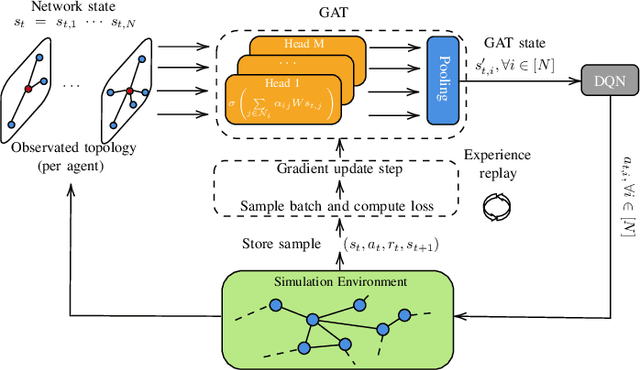
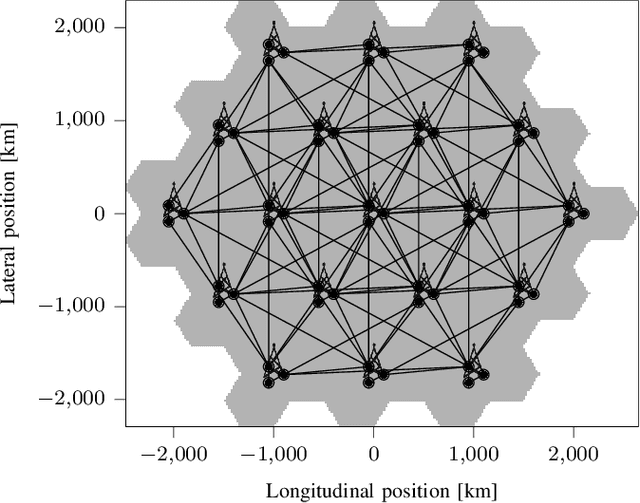
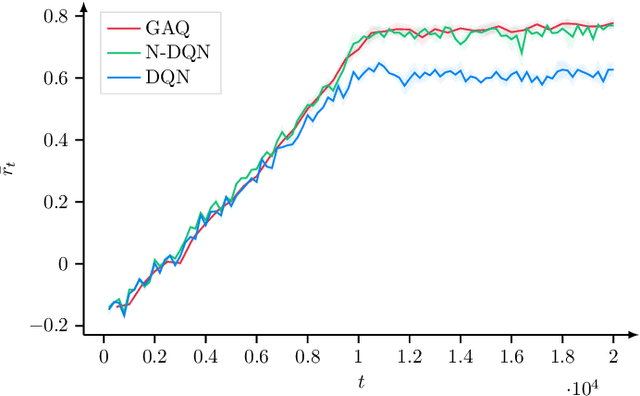

6G will move mobile networks towards increasing levels of complexity. To deal with this complexity, optimization of network parameters is key to ensure high performance and timely adaptivity to dynamic network environments. The optimization of the antenna tilt provides a practical and cost-efficient method to improve coverage and capacity in the network. Previous methods based on Reinforcement Learning (RL) have shown great promise for tilt optimization by learning adaptive policies outperforming traditional tilt optimization methods. However, most existing RL methods are based on single-cell features representation, which fails to fully characterize the agent state, resulting in suboptimal performance. Also, most of such methods lack scalability, due to state-action explosion, and generalization ability. In this paper, we propose a Graph Attention Q-learning (GAQ) algorithm for tilt optimization. GAQ relies on a graph attention mechanism to select relevant neighbors information, improve the agent state representation, and update the tilt control policy based on a history of observations using a Deep Q-Network (DQN). We show that GAQ efficiently captures important network information and outperforms standard DQN with local information by a large margin. In addition, we demonstrate its ability to generalize to network deployments of different sizes and densities.
Coordinated Reinforcement Learning for Optimizing Mobile Networks
Sep 30, 2021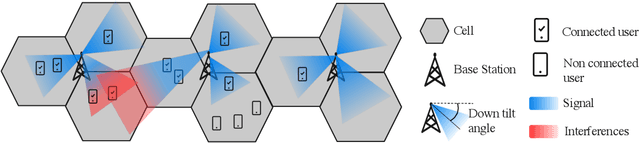


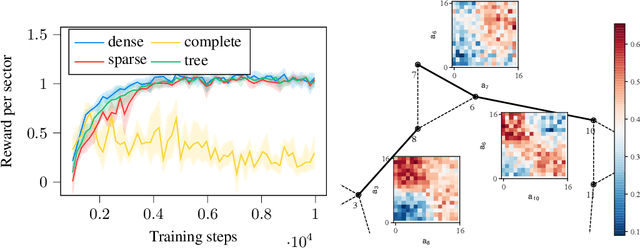
Mobile networks are composed of many base stations and for each of them many parameters must be optimized to provide good services. Automatically and dynamically optimizing all these entities is challenging as they are sensitive to variations in the environment and can affect each other through interferences. Reinforcement learning (RL) algorithms are good candidates to automatically learn base station configuration strategies from incoming data but they are often hard to scale to many agents. In this work, we demonstrate how to use coordination graphs and reinforcement learning in a complex application involving hundreds of cooperating agents. We show how mobile networks can be modeled using coordination graphs and how network optimization problems can be solved efficiently using multi- agent reinforcement learning. The graph structure occurs naturally from expert knowledge about the network and allows to explicitly learn coordinating behaviors between the antennas through edge value functions represented by neural networks. We show empirically that coordinated reinforcement learning outperforms other methods. The use of local RL updates and parameter sharing can handle a large number of agents without sacrificing coordination which makes it well suited to optimize the ever denser networks brought by 5G and beyond.
Reinforcement Learning with Iterative Reasoning for Merging in Dense Traffic
May 25, 2020

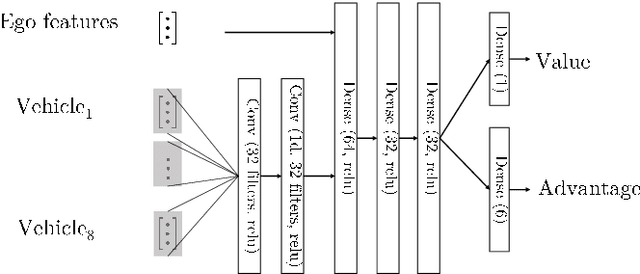

Maneuvering in dense traffic is a challenging task for autonomous vehicles because it requires reasoning about the stochastic behaviors of many other participants. In addition, the agent must achieve the maneuver within a limited time and distance. In this work, we propose a combination of reinforcement learning and game theory to learn merging behaviors. We design a training curriculum for a reinforcement learning agent using the concept of level-$k$ behavior. This approach exposes the agent to a broad variety of behaviors during training, which promotes learning policies that are robust to model discrepancies. We show that our approach learns more efficient policies than traditional training methods.
* 6pages, 5 figures
Point-Based Methods for Model Checking in Partially Observable Markov Decision Processes
Jan 11, 2020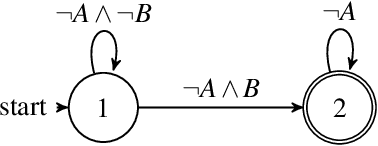
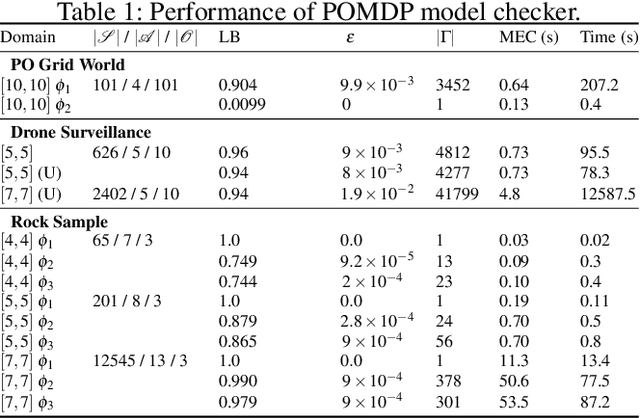

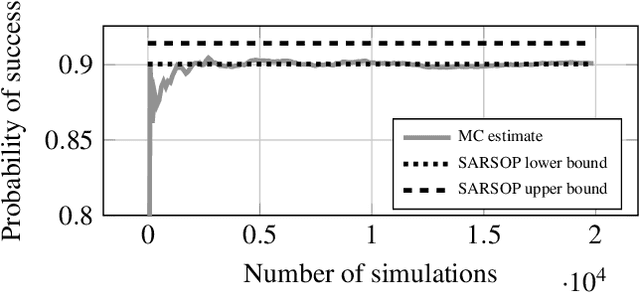
Autonomous systems are often required to operate in partially observable environments. They must reliably execute a specified objective even with incomplete information about the state of the environment. We propose a methodology to synthesize policies that satisfy a linear temporal logic formula in a partially observable Markov decision process (POMDP). By formulating a planning problem, we show how to use point-based value iteration methods to efficiently approximate the maximum probability of satisfying a desired logical formula and compute the associated belief state policy. We demonstrate that our method scales to large POMDP domains and provides strong bounds on the performance of the resulting policy.
* 8 pages, 3 figures, AAAI 2020
Cooperation-Aware Reinforcement Learning for Merging in Dense Traffic
Jun 26, 2019
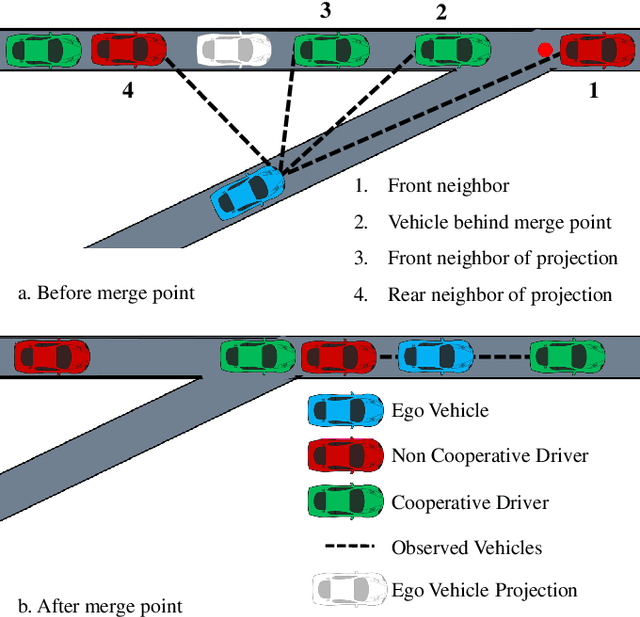


Decision making in dense traffic can be challenging for autonomous vehicles. An autonomous system only relying on predefined road priorities and considering other drivers as moving objects will cause the vehicle to freeze and fail the maneuver. Human drivers leverage the cooperation of other drivers to avoid such deadlock situations and convince others to change their behavior. Decision making algorithms must reason about the interaction with other drivers and anticipate a broad range of driver behaviors. In this work, we present a reinforcement learning approach to learn how to interact with drivers with different cooperation levels. We enhanced the performance of traditional reinforcement learning algorithms by maintaining a belief over the level of cooperation of other drivers. We show that our agent successfully learns how to navigate a dense merging scenario with less deadlocks than with online planning methods.
* 7 pages, 5 figures
Reinforcement Learning with Probabilistic Guarantees for Autonomous Driving
May 29, 2019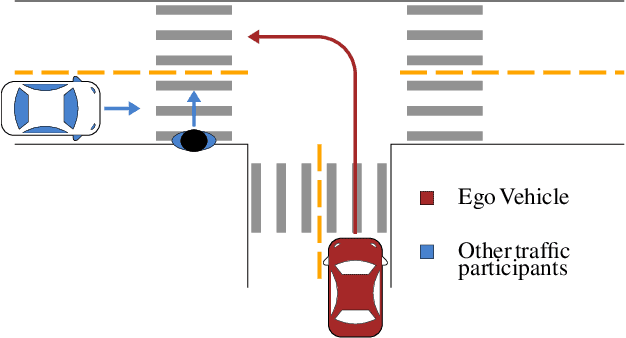
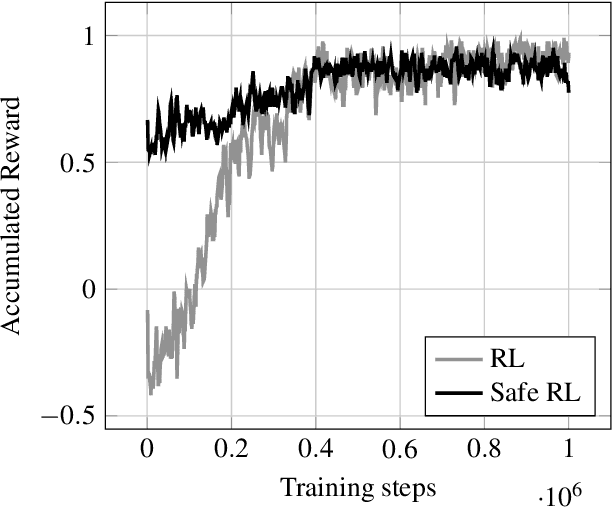
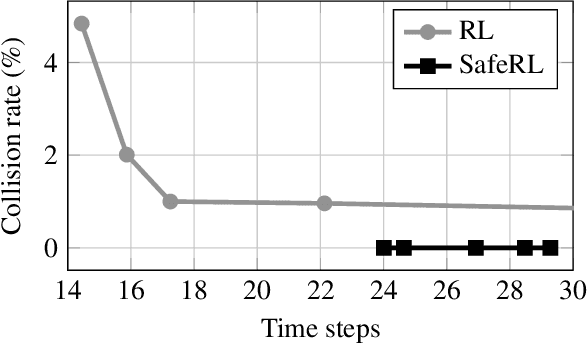
Designing reliable decision strategies for autonomous urban driving is challenging. Reinforcement learning (RL) has been used to automatically derive suitable behavior in uncertain environments, but it does not provide any guarantee on the performance of the resulting policy. We propose a generic approach to enforce probabilistic guarantees on an RL agent. An exploration strategy is derived prior to training that constrains the agent to choose among actions that satisfy a desired probabilistic specification expressed with linear temporal logic (LTL). Reducing the search space to policies satisfying the LTL formula helps training and simplifies reward design. This paper outlines a case study of an intersection scenario involving multiple traffic participants. The resulting policy outperforms a rule-based heuristic approach in terms of efficiency while exhibiting strong guarantees on safety.
Pedestrian Collision Avoidance System for Scenarios with Occlusions
Apr 25, 2019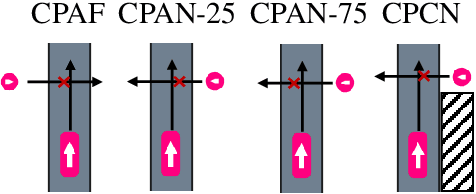
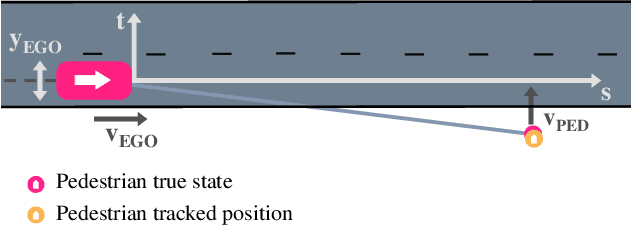
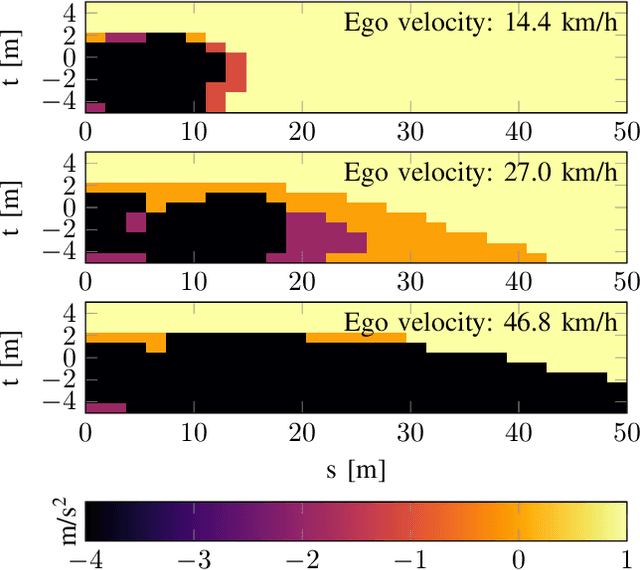
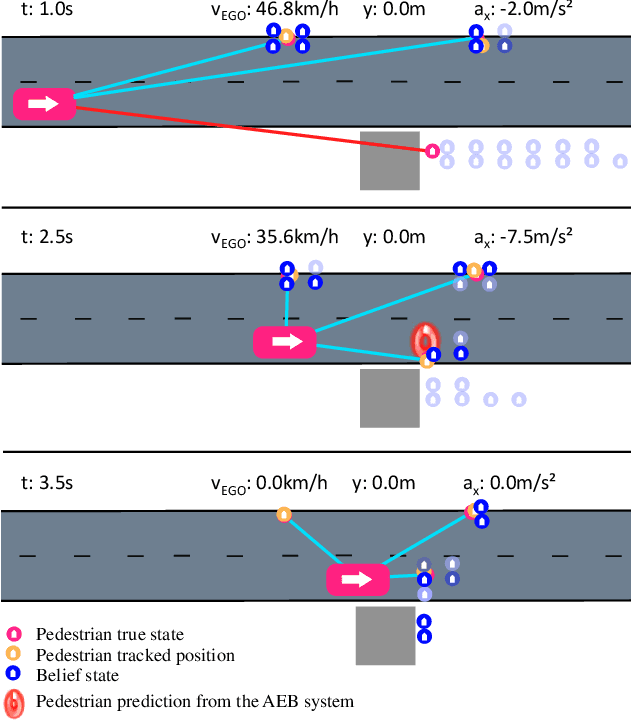
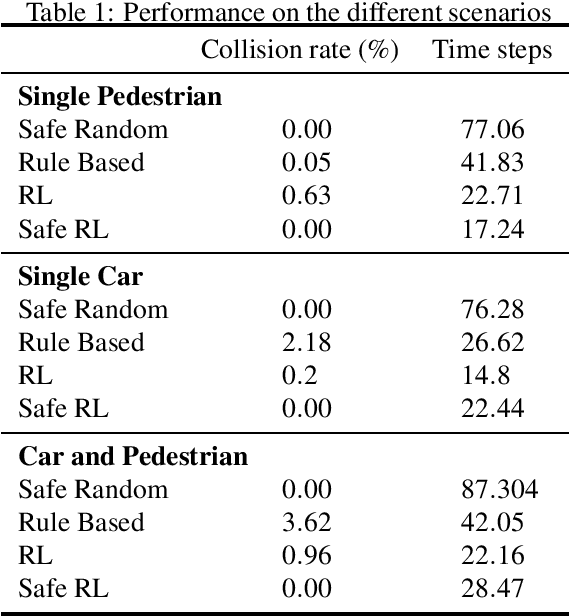
Safe autonomous driving in urban areas requires robust algorithms to avoid collisions with other traffic participants with limited perception ability. Current deployed approaches relying on Autonomous Emergency Braking (AEB) systems are often overly conservative. In this work, we formulate the problem as a partially observable Markov decision process (POMDP), to derive a policy robust to uncertainty in the pedestrian location. We investigate how to integrate such a policy with an AEB system that operates only when a collision is unavoidable. In addition, we propose a rigorous evaluation methodology on a set of well defined scenarios. We show that combining the two approaches provides a robust autonomous braking system that reduces unnecessary braking caused by using the AEB system on its own.
* 7 pages; 8 figures
Safe Reinforcement Learning with Scene Decomposition for Navigating Complex Urban Environments
Apr 25, 2019
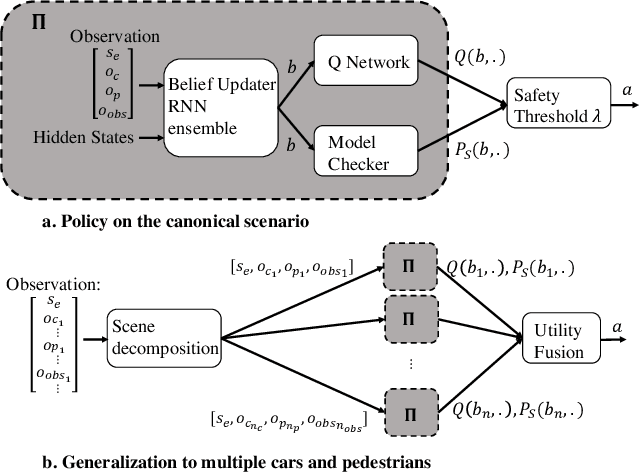


Navigating urban environments represents a complex task for automated vehicles. They must reach their goal safely and efficiently while considering a multitude of traffic participants. We propose a modular decision making algorithm to autonomously navigate intersections, addressing challenges of existing rule-based and reinforcement learning (RL) approaches. We first present a safe RL algorithm relying on a model-checker to ensure safety guarantees. To make the decision strategy robust to perception errors and occlusions, we introduce a belief update technique using a learning based approach. Finally, we use a scene decomposition approach to scale our algorithm to environments with multiple traffic participants. We empirically demonstrate that our algorithm outperforms rule-based methods and reinforcement learning techniques on a complex intersection scenario.
* 8 pages; 7 figures
Utility Decomposition with Deep Corrections for Scalable Planning under Uncertainty
Feb 06, 2018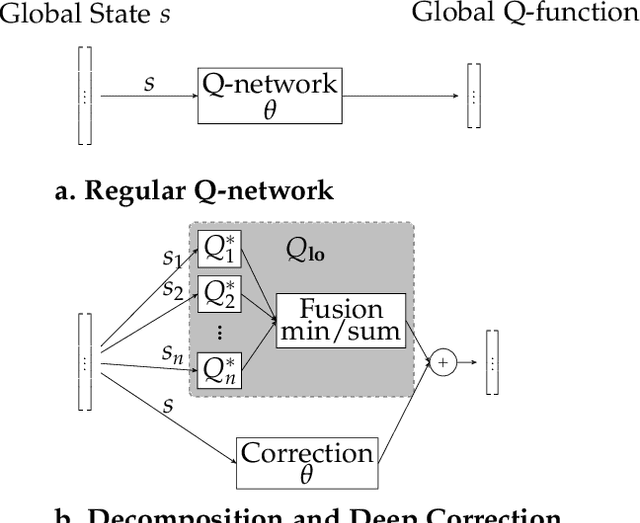
Decomposition methods have been proposed in the past to approximate solutions to large sequential decision making problems. In contexts where an agent interacts with multiple entities, utility decomposition can be used where each individual entity is considered independently. The individual utility functions are then combined in real time to solve the global problem. Although these techniques can perform well empirically, they sacrifice optimality. This paper proposes an approach inspired from multi-fidelity optimization to learn a correction term with a neural network representation. Learning this correction can significantly improve performance. We demonstrate this approach on a pedestrian avoidance problem for autonomous driving. By leveraging strategies to avoid a single pedestrian, the decomposition method can scale to avoid multiple pedestrians. We verify empirically that the proposed correction method leads to a significant improvement over the decomposition method alone and outperforms a policy trained on the full scale problem without utility decomposition.