Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-Based Methods for Model Checking in Partially Observable Markov Decision Processes
Paper and Code
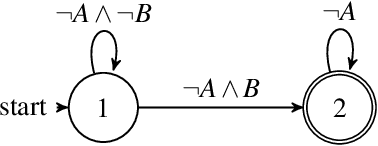
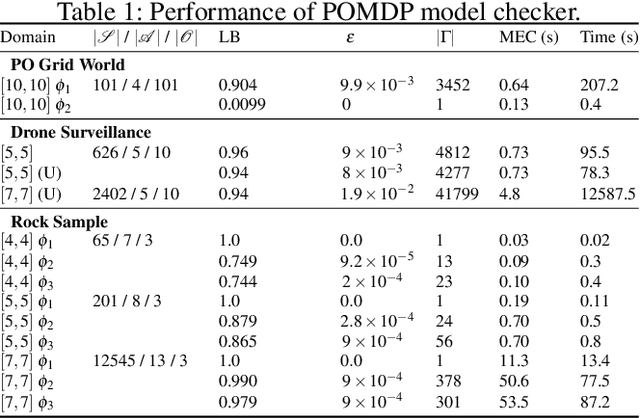

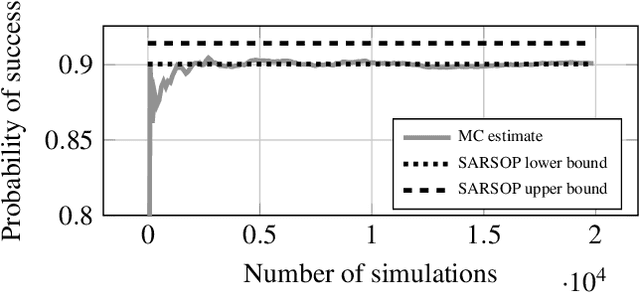
Autonomous systems are often required to operate in partially observable environments. They must reliably execute a specified objective even with incomplete information about the state of the environment. We propose a methodology to synthesize policies that satisfy a linear temporal logic formula in a partially observable Markov decision process (POMDP). By formulating a planning problem, we show how to use point-based value iteration methods to efficiently approximate the maximum probability of satisfying a desired logical formula and compute the associated belief state policy. We demonstrate that our method scales to large POMDP domains and provides strong bounds on the performance of the resulting policy.
* AAAI 2020 * 8 pages, 3 figures, AAAI 2020
View paper on