 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReceding-Horizon Control via Drifting Models
Apr 06, 2026We study the problem of trajectory optimization in settings where the system dynamics are unknown and it is not possible to simulate trajectories through a surrogate model. When an offline dataset of trajectories is available, an agent could directly learn a trajectory generator by distribution matching. However, this approach only recovers the behavior distribution in the dataset, and does not in general produce a model that minimizes a desired cost criterion. In this work, we propose Drifting MPC, an offline trajectory optimization framework that combines drifting generative models with receding-horizon planning under unknown dynamics. The goal of Drifting MPC is to learn, from an offline dataset of trajectories, a conditional distribution over trajectories that is both supported by the data and biased toward optimal plans. We show that the resulting distribution learned by Drifting MPC is the unique solution of an objective that trades off optimality with closeness to the offline prior. Empirically, we show that Drifting MPC can generate near-optimal trajectories while retaining the one-step inference efficiency of drifting models and substantially reducing generation time relative to diffusion-based baselines.
Pure Exploration with Feedback Graphs
Mar 10, 2025



We study the sample complexity of pure exploration in an online learning problem with a feedback graph. This graph dictates the feedback available to the learner, covering scenarios between full-information, pure bandit feedback, and settings with no feedback on the chosen action. While variants of this problem have been investigated for regret minimization, no prior work has addressed the pure exploration setting, which is the focus of our study. We derive an instance-specific lower bound on the sample complexity of learning the best action with fixed confidence, even when the feedback graph is unknown and stochastic, and present unidentifiability results for Bernoulli rewards. Additionally, our findings reveal how the sample complexity scales with key graph-dependent quantities. Lastly, we introduce TaS-FG (Track and Stop for Feedback Graphs), an asymptotically optimal algorithm, and demonstrate its efficiency across different graph configurations.
Adaptive Exploration for Multi-Reward Multi-Policy Evaluation
Feb 04, 2025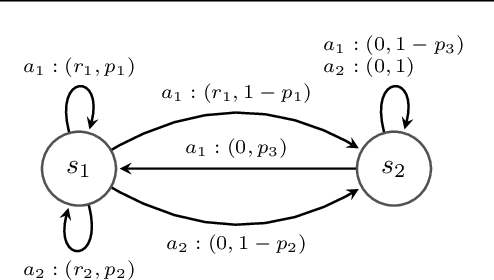
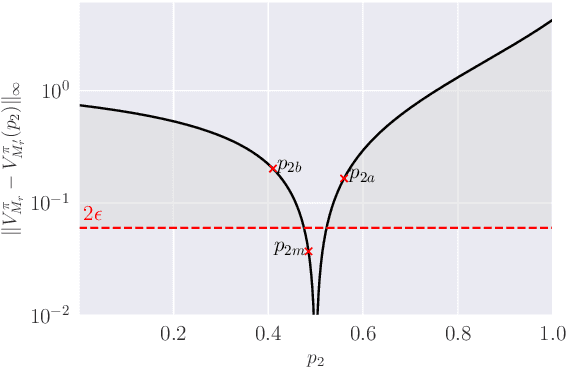
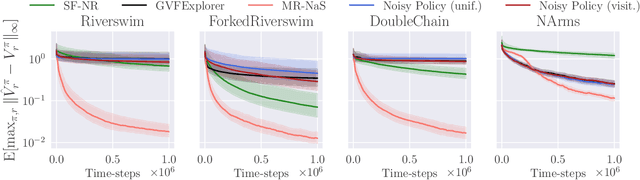
We study the policy evaluation problem in an online multi-reward multi-policy discounted setting, where multiple reward functions must be evaluated simultaneously for different policies. We adopt an $(\epsilon,\delta)$-PAC perspective to achieve $\epsilon$-accurate estimates with high confidence across finite or convex sets of rewards, a setting that has not been investigated in the literature. Building on prior work on Multi-Reward Best Policy Identification, we adapt the MR-NaS exploration scheme to jointly minimize sample complexity for evaluating different policies across different reward sets. Our approach leverages an instance-specific lower bound revealing how the sample complexity scales with a measure of value deviation, guiding the design of an efficient exploration policy. Although computing this bound entails a hard non-convex optimization, we propose an efficient convex approximation that holds for both finite and convex reward sets. Experiments in tabular domains demonstrate the effectiveness of this adaptive exploration scheme.
Achieving $\widetilde{\mathcal{O}}(\sqrt{T})$ Regret in Average-Reward POMDPs with Known Observation Models
Jan 30, 2025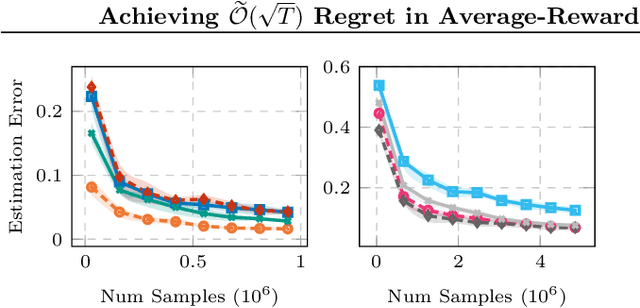
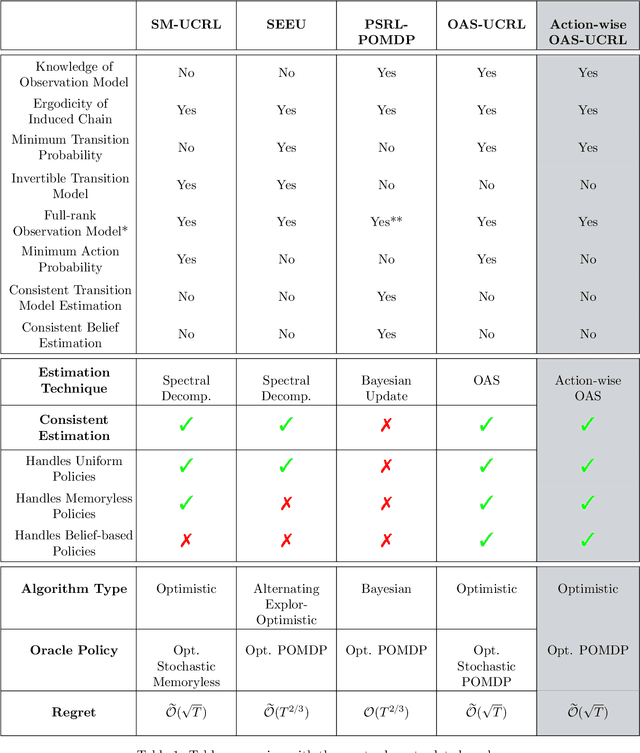
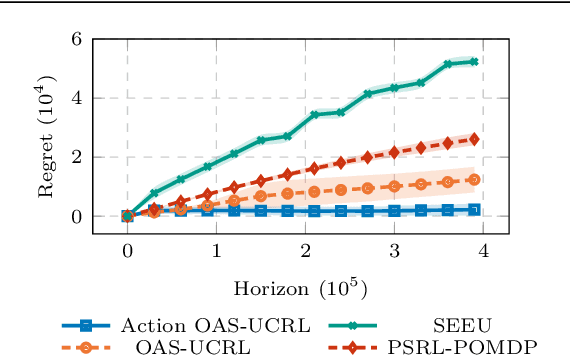
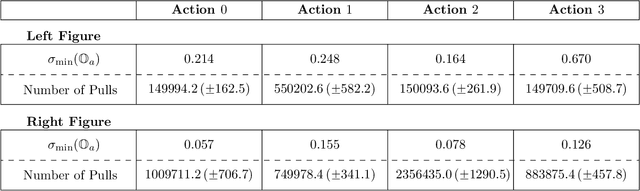
We tackle average-reward infinite-horizon POMDPs with an unknown transition model but a known observation model, a setting that has been previously addressed in two limiting ways: (i) frequentist methods relying on suboptimal stochastic policies having a minimum probability of choosing each action, and (ii) Bayesian approaches employing the optimal policy class but requiring strong assumptions about the consistency of employed estimators. Our work removes these limitations by proving convenient estimation guarantees for the transition model and introducing an optimistic algorithm that leverages the optimal class of deterministic belief-based policies. We introduce modifications to existing estimation techniques providing theoretical guarantees separately for each estimated action transition matrix. Unlike existing estimation methods that are unable to use samples from different policies, we present a novel and simple estimator that overcomes this barrier. This new data-efficient technique, combined with the proposed \emph{Action-wise OAS-UCRL} algorithm and a tighter theoretical analysis, leads to the first approach enjoying a regret guarantee of order $\mathcal{O}(\sqrt{T \,\log T})$ when compared against the optimal policy, thus improving over state of the art techniques. Finally, theoretical results are validated through numerical simulations showing the efficacy of our method against baseline methods.
Explainable Reinforcement Learning via Temporal Policy Decomposition
Jan 07, 2025



We investigate the explainability of Reinforcement Learning (RL) policies from a temporal perspective, focusing on the sequence of future outcomes associated with individual actions. In RL, value functions compress information about rewards collected across multiple trajectories and over an infinite horizon, allowing a compact form of knowledge representation. However, this compression obscures the temporal details inherent in sequential decision-making, presenting a key challenge for interpretability. We present Temporal Policy Decomposition (TPD), a novel explainability approach that explains individual RL actions in terms of their Expected Future Outcome (EFO). These explanations decompose generalized value functions into a sequence of EFOs, one for each time step up to a prediction horizon of interest, revealing insights into when specific outcomes are expected to occur. We leverage fixed-horizon temporal difference learning to devise an off-policy method for learning EFOs for both optimal and suboptimal actions, enabling contrastive explanations consisting of EFOs for different state-action pairs. Our experiments demonstrate that TPD generates accurate explanations that (i) clarify the policy's future strategy and anticipated trajectory for a given action and (ii) improve understanding of the reward composition, facilitating fine-tuning of the reward function to align with human expectations.
Offline Reinforcement Learning and Sequence Modeling for Downlink Link Adaptation
Oct 30, 2024



Contemporary radio access networks employ link adaption (LA) algorithms to optimize the modulation and coding schemes to adapt to the prevailing propagation conditions and are near-optimal in terms of the achieved spectral efficiency. LA is a challenging task in the presence of mobility, fast fading, and imperfect channel quality information and limited knowledge of the receiver characteristics at the transmitter, which render model-based LA algorithms complex and suboptimal. Model-based LA is especially difficult as connected user equipment devices become increasingly heterogeneous in terms of receiver capabilities, antenna configurations and hardware characteristics. Recognizing these difficulties, previous works have proposed reinforcement learning (RL) for LA, which faces deployment difficulties due to their potential negative impacts on live performance. To address this challenge, this paper considers offline RL to learn LA policies from data acquired in live networks with minimal or no intrusive effects on the network operation. We propose three LA designs based on batch-constrained deep Q-learning, conservative Q-learning, and decision transformers, showing that offline RL algorithms can achieve performance of state-of-the-art online RL methods when data is collected with a proper behavioral policy.
Efficient Learning of POMDPs with Known Observation Model in Average-Reward Setting
Oct 02, 2024Dealing with Partially Observable Markov Decision Processes is notably a challenging task. We face an average-reward infinite-horizon POMDP setting with an unknown transition model, where we assume the knowledge of the observation model. Under this assumption, we propose the Observation-Aware Spectral (OAS) estimation technique, which enables the POMDP parameters to be learned from samples collected using a belief-based policy. Then, we propose the OAS-UCRL algorithm that implicitly balances the exploration-exploitation trade-off following the $\textit{optimism in the face of uncertainty}$ principle. The algorithm runs through episodes of increasing length. For each episode, the optimal belief-based policy of the estimated POMDP interacts with the environment and collects samples that will be used in the next episode by the OAS estimation procedure to compute a new estimate of the POMDP parameters. Given the estimated model, an optimization oracle computes the new optimal policy. We show the consistency of the OAS procedure, and we prove a regret guarantee of order $\mathcal{O}(\sqrt{T \log(T)})$ for the proposed OAS-UCRL algorithm. We compare against the oracle playing the optimal stochastic belief-based policy and show the efficient scaling of our approach with respect to the dimensionality of the state, action, and observation space. We finally conduct numerical simulations to validate and compare the proposed technique with other baseline approaches.
Fair Best Arm Identification with Fixed Confidence
Aug 30, 2024



In this work, we present a novel framework for Best Arm Identification (BAI) under fairness constraints, a setting that we refer to as \textit{F-BAI} (fair BAI). Unlike traditional BAI, which solely focuses on identifying the optimal arm with minimal sample complexity, F-BAI also includes a set of fairness constraints. These constraints impose a lower limit on the selection rate of each arm and can be either model-agnostic or model-dependent. For this setting, we establish an instance-specific sample complexity lower bound and analyze the \textit{price of fairness}, quantifying how fairness impacts sample complexity. Based on the sample complexity lower bound, we propose F-TaS, an algorithm provably matching the sample complexity lower bound, while ensuring that the fairness constraints are satisfied. Numerical results, conducted using both a synthetic model and a practical wireless scheduling application, show the efficiency of F-TaS in minimizing the sample complexity while achieving low fairness violations.
Model-Free Active Exploration in Reinforcement Learning
Jun 30, 2024We study the problem of exploration in Reinforcement Learning and present a novel model-free solution. We adopt an information-theoretical viewpoint and start from the instance-specific lower bound of the number of samples that have to be collected to identify a nearly-optimal policy. Deriving this lower bound along with the optimal exploration strategy entails solving an intricate optimization problem and requires a model of the system. In turn, most existing sample optimal exploration algorithms rely on estimating the model. We derive an approximation of the instance-specific lower bound that only involves quantities that can be inferred using model-free approaches. Leveraging this approximation, we devise an ensemble-based model-free exploration strategy applicable to both tabular and continuous Markov decision processes. Numerical results demonstrate that our strategy is able to identify efficient policies faster than state-of-the-art exploration approaches
Conformal Off-Policy Evaluation in Markov Decision Processes
Apr 05, 2023Reinforcement Learning aims at identifying and evaluating efficient control policies from data. In many real-world applications, the learner is not allowed to experiment and cannot gather data in an online manner (this is the case when experimenting is expensive, risky or unethical). For such applications, the reward of a given policy (the target policy) must be estimated using historical data gathered under a different policy (the behavior policy). Most methods for this learning task, referred to as Off-Policy Evaluation (OPE), do not come with accuracy and certainty guarantees. We present a novel OPE method based on Conformal Prediction that outputs an interval containing the true reward of the target policy with a prescribed level of certainty. The main challenge in OPE stems from the distribution shift due to the discrepancies between the target and the behavior policies. We propose and empirically evaluate different ways to deal with this shift. Some of these methods yield conformalized intervals with reduced length compared to existing approaches, while maintaining the same certainty level.