 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Best Arm Identification with Fixed Confidence
Aug 30, 2024



In this work, we present a novel framework for Best Arm Identification (BAI) under fairness constraints, a setting that we refer to as \textit{F-BAI} (fair BAI). Unlike traditional BAI, which solely focuses on identifying the optimal arm with minimal sample complexity, F-BAI also includes a set of fairness constraints. These constraints impose a lower limit on the selection rate of each arm and can be either model-agnostic or model-dependent. For this setting, we establish an instance-specific sample complexity lower bound and analyze the \textit{price of fairness}, quantifying how fairness impacts sample complexity. Based on the sample complexity lower bound, we propose F-TaS, an algorithm provably matching the sample complexity lower bound, while ensuring that the fairness constraints are satisfied. Numerical results, conducted using both a synthetic model and a practical wireless scheduling application, show the efficiency of F-TaS in minimizing the sample complexity while achieving low fairness violations.
Learning Optimal Antenna Tilt Control Policies: A Contextual Linear Bandit Approach
Jan 06, 2022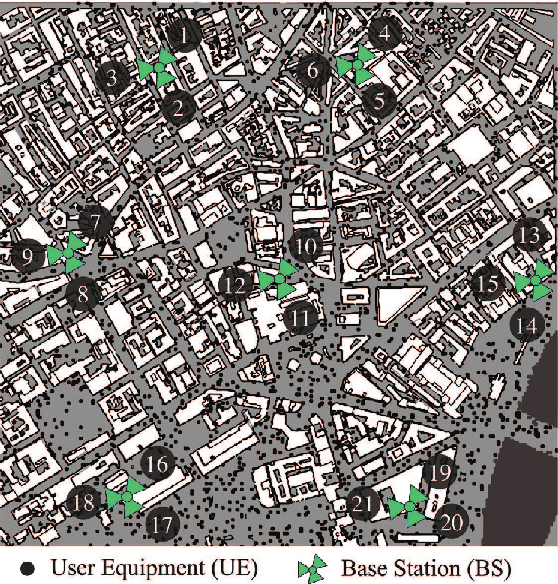
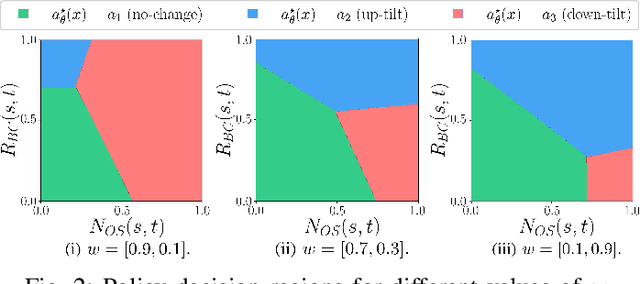
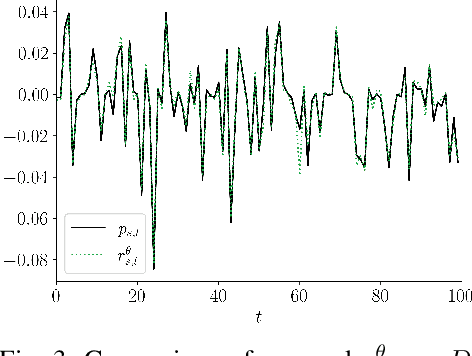
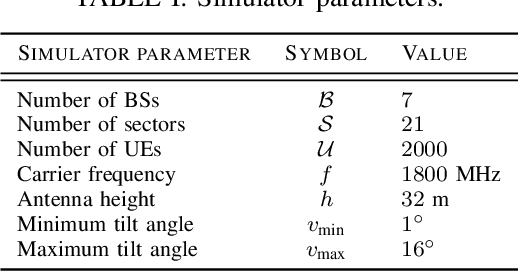
Controlling antenna tilts in cellular networks is imperative to reach an efficient trade-off between network coverage and capacity. In this paper, we devise algorithms learning optimal tilt control policies from existing data (in the so-called passive learning setting) or from data actively generated by the algorithms (the active learning setting). We formalize the design of such algorithms as a Best Policy Identification (BPI) problem in Contextual Linear Multi-Arm Bandits (CL-MAB). An arm represents an antenna tilt update; the context captures current network conditions; the reward corresponds to an improvement of performance, mixing coverage and capacity; and the objective is to identify, with a given level of confidence, an approximately optimal policy (a function mapping the context to an arm with maximal reward). For CL-MAB in both active and passive learning settings, we derive information-theoretical lower bounds on the number of samples required by any algorithm returning an approximately optimal policy with a given level of certainty, and devise algorithms achieving these fundamental limits. We apply our algorithms to the Remote Electrical Tilt (RET) optimization problem in cellular networks, and show that they can produce optimal tilt update policy using much fewer data samples than naive or existing rule-based learning algorithms.
A Graph Attention Learning Approach to Antenna Tilt Optimization
Dec 27, 2021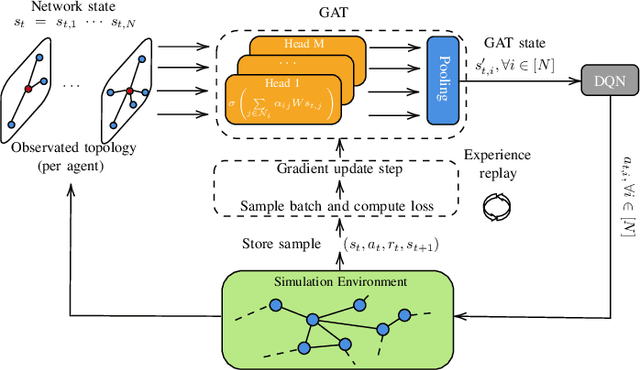
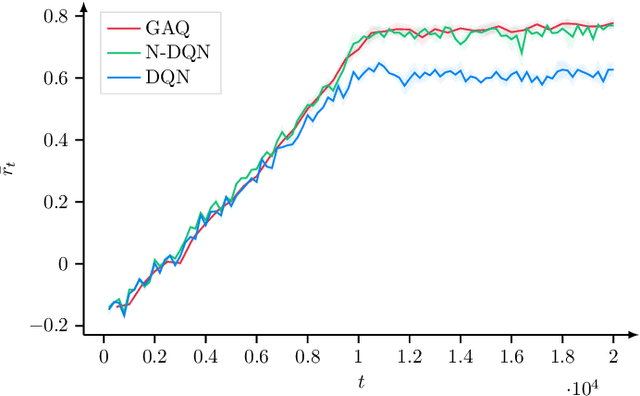

6G will move mobile networks towards increasing levels of complexity. To deal with this complexity, optimization of network parameters is key to ensure high performance and timely adaptivity to dynamic network environments. The optimization of the antenna tilt provides a practical and cost-efficient method to improve coverage and capacity in the network. Previous methods based on Reinforcement Learning (RL) have shown great promise for tilt optimization by learning adaptive policies outperforming traditional tilt optimization methods. However, most existing RL methods are based on single-cell features representation, which fails to fully characterize the agent state, resulting in suboptimal performance. Also, most of such methods lack scalability, due to state-action explosion, and generalization ability. In this paper, we propose a Graph Attention Q-learning (GAQ) algorithm for tilt optimization. GAQ relies on a graph attention mechanism to select relevant neighbors information, improve the agent state representation, and update the tilt control policy based on a history of observations using a Deep Q-Network (DQN). We show that GAQ efficiently captures important network information and outperforms standard DQN with local information by a large margin. In addition, we demonstrate its ability to generalize to network deployments of different sizes and densities.
Safe Reinforcement Learning for Antenna Tilt Optimisation using Shielding and Multiple Baselines
Dec 02, 2020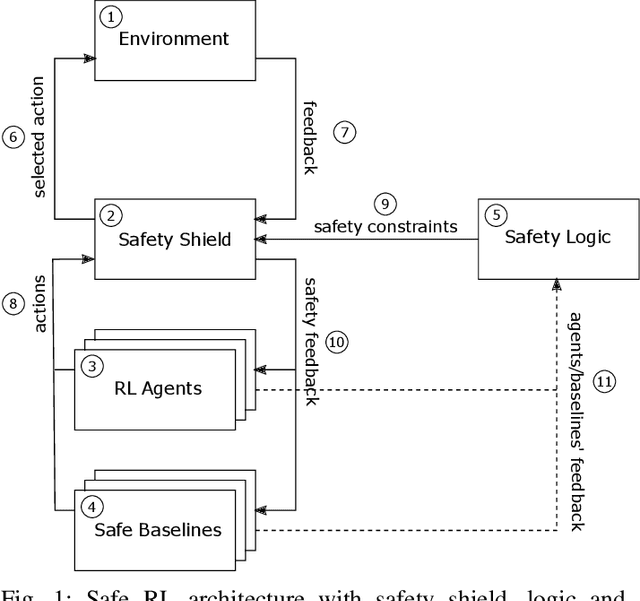
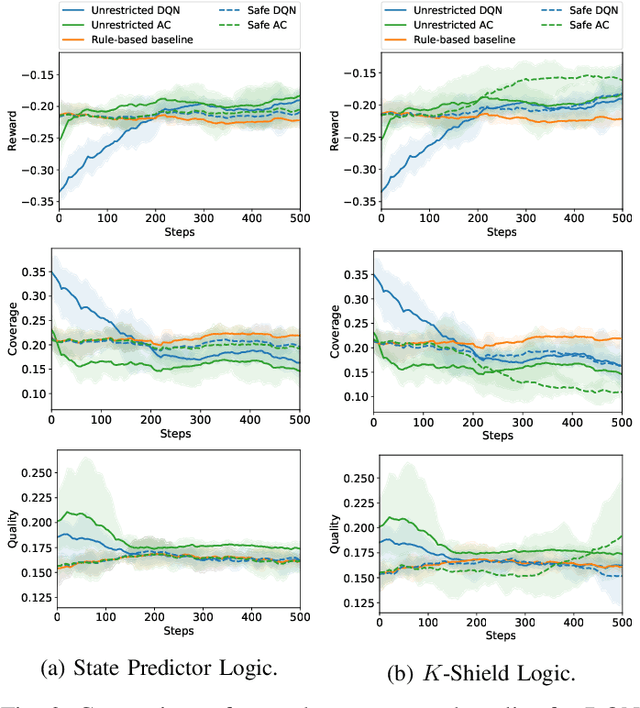
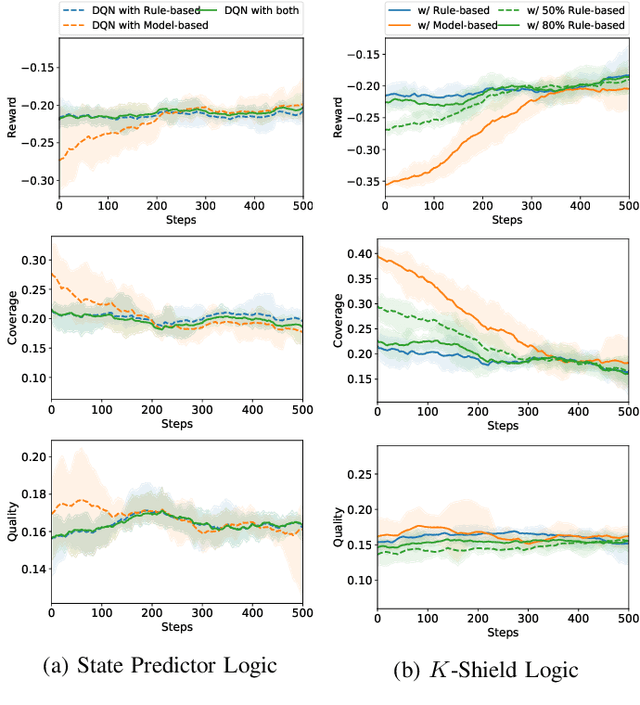

Safe interaction with the environment is one of the most challenging aspects of Reinforcement Learning (RL) when applied to real-world problems. This is particularly important when unsafe actions have a high or irreversible negative impact on the environment. In the context of network management operations, Remote Electrical Tilt (RET) optimisation is a safety-critical application in which exploratory modifications of antenna tilt angles of Base Stations (BSs) can cause significant performance degradation in the network. In this paper, we propose a modular Safe Reinforcement Learning (SRL) architecture which is then used to address the RET optimisation in cellular networks. In this approach, a safety shield continuously benchmarks the performance of RL agents against safe baselines, and determines safe antenna tilt updates to be performed on the network. Our results demonstrate improved performance of the SRL agent over the baseline while ensuring the safety of the performed actions.
Remote Electrical Tilt Optimization via Safe Reinforcement Learning
Oct 12, 2020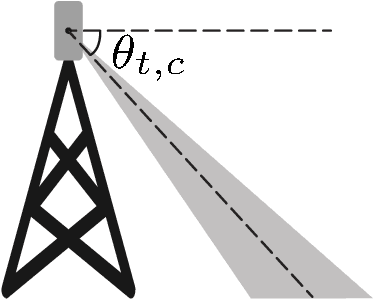
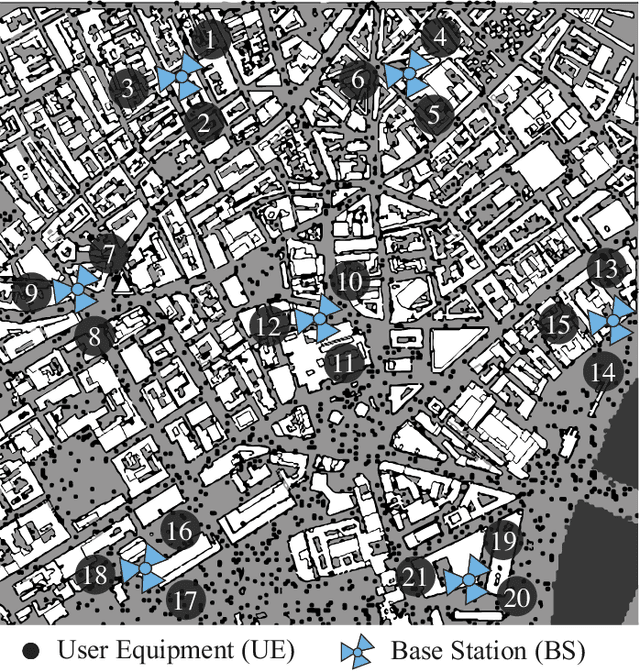
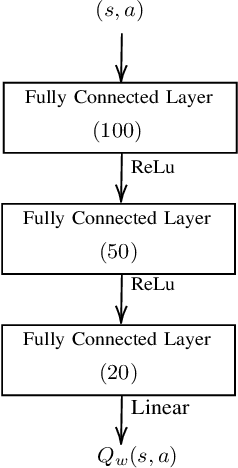
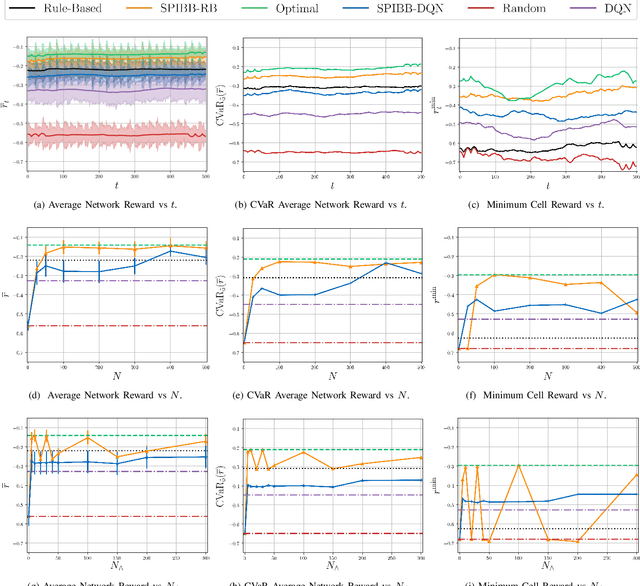
Remote Electrical Tilt (RET) optimization is an efficient method for adjusting the vertical tilt angle of Base Stations (BSs) antennas in order to optimize Key Performance Indicators (KPIs) of the network. Reinforcement Learning (RL) provides a powerful framework for RET optimization because of its self-learning capabilities and adaptivity to environmental changes. However, an RL agent may execute unsafe actions during the course of its interaction, i.e., actions resulting in undesired network performance degradation. Since the reliability of services is critical for Mobile Network Operators (MNOs), the prospect of performance degradation has prohibited the real-world deployment of RL methods for RET optimization. In this work, we model the RET optimization problem in the Safe Reinforcement Learning (SRL) framework with the goal of learning a tilt control strategy providing performance improvement guarantees with respect to a safe baseline. We leverage a recent SRL method, namely Safe Policy Improvement through Baseline Bootstrapping (SPIBB), to learn an improved policy from an offline dataset of interactions collected by the safe baseline. Our experiments show that the proposed approach is able to learn a safe and improved tilt update policy, providing a higher degree of reliability and potential for real-world network deployment.
Off-policy Learning for Remote Electrical Tilt Optimization
May 21, 2020
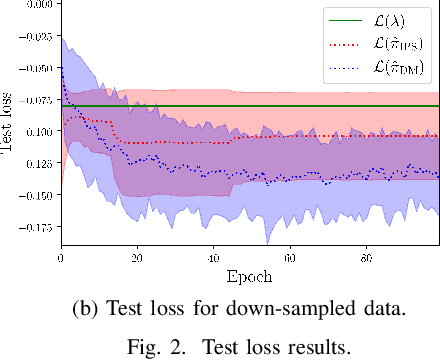
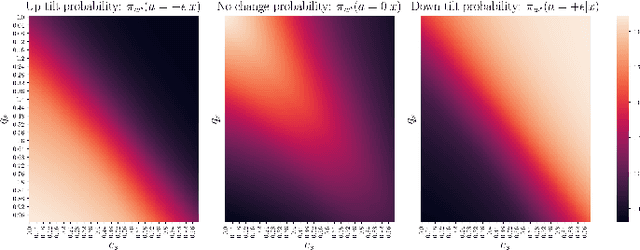

We address the problem of Remote Electrical Tilt (RET) optimization using off-policy Contextual Multi-Armed-Bandit (CMAB) techniques. The goal in RET optimization is to control the orientation of the vertical tilt angle of the antenna to optimize Key Performance Indicators (KPIs) representing the Quality of Service (QoS) perceived by the users in cellular networks. Learning an improved tilt update policy is hard. On the one hand, coming up with a new policy in an online manner in a real network requires exploring tilt updates that have never been used before, and is operationally too risky. On the other hand, devising this policy via simulations suffers from the simulation-to-reality gap. In this paper, we circumvent these issues by learning an improved policy in an offline manner using existing data collected on real networks. We formulate the problem of devising such a policy using the off-policy CMAB framework. We propose CMAB learning algorithms to extract optimal tilt update policies from the data. We train and evaluate these policies on real-world 4G Long Term Evolution (LTE) cellular network data. Our policies show consistent improvements over the rule-based logging policy used to collect the data.