 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Electrical Tilt Optimization via Safe Reinforcement Learning
Paper and Code
Oct 12, 2020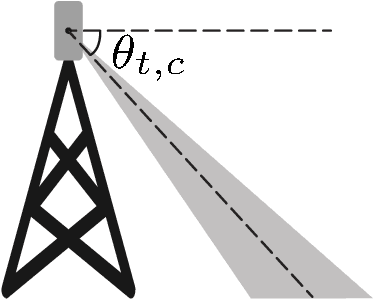
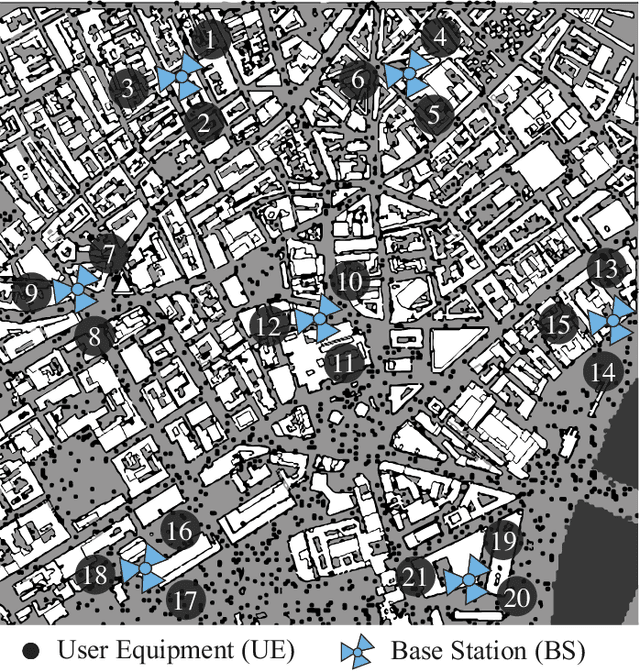
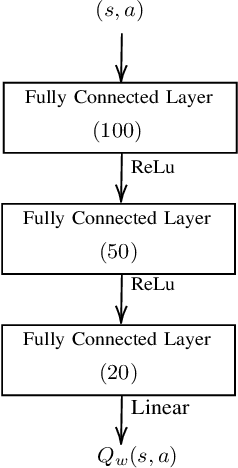
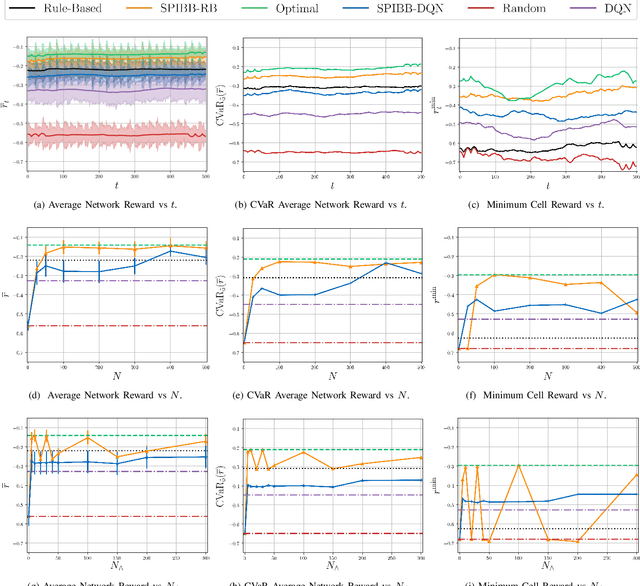
Remote Electrical Tilt (RET) optimization is an efficient method for adjusting the vertical tilt angle of Base Stations (BSs) antennas in order to optimize Key Performance Indicators (KPIs) of the network. Reinforcement Learning (RL) provides a powerful framework for RET optimization because of its self-learning capabilities and adaptivity to environmental changes. However, an RL agent may execute unsafe actions during the course of its interaction, i.e., actions resulting in undesired network performance degradation. Since the reliability of services is critical for Mobile Network Operators (MNOs), the prospect of performance degradation has prohibited the real-world deployment of RL methods for RET optimization. In this work, we model the RET optimization problem in the Safe Reinforcement Learning (SRL) framework with the goal of learning a tilt control strategy providing performance improvement guarantees with respect to a safe baseline. We leverage a recent SRL method, namely Safe Policy Improvement through Baseline Bootstrapping (SPIBB), to learn an improved policy from an offline dataset of interactions collected by the safe baseline. Our experiments show that the proposed approach is able to learn a safe and improved tilt update policy, providing a higher degree of reliability and potential for real-world network deployment.