 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvantage-Guided Diffusion for Model-Based Reinforcement Learning
Apr 10, 2026Model-based reinforcement learning (MBRL) with autoregressive world models suffers from compounding errors, whereas diffusion world models mitigate this by generating trajectory segments jointly. However, existing diffusion guides are either policy-only, discarding value information, or reward-based, which becomes myopic when the diffusion horizon is short. We introduce Advantage-Guided Diffusion for MBRL (AGD-MBRL), which steers the reverse diffusion process using the agent's advantage estimates so that sampling concentrates on trajectories expected to yield higher long-term return beyond the generated window. We develop two guides: (i) Sigmoid Advantage Guidance (SAG) and (ii) Exponential Advantage Guidance (EAG). We prove that a diffusion model guided through SAG or EAG allows us to perform reweighted sampling of trajectories with weights increasing in state-action advantage-implying policy improvement under standard assumptions. Additionally, we show that the trajectories generated from AGD-MBRL follow an improved policy (that is, with higher value) compared to an unguided diffusion model. AGD integrates seamlessly with PolyGRAD-style architectures by guiding the state components while leaving action generation policy-conditioned, and requires no change to the diffusion training objective. On MuJoCo control tasks (HalfCheetah, Hopper, Walker2D and Reacher), AGD-MBRL improves sample efficiency and final return over PolyGRAD, an online Diffuser-style reward guide, and model-free baselines (PPO/TRPO), in some cases by a margin of 2x. These results show that advantage-aware guidance is a simple, effective remedy for short-horizon myopia in diffusion-model MBRL.
Optimal Centered Active Excitation in Linear System Identification
Apr 07, 2026We propose an active learning algorithm for linear system identification with optimal centered noise excitation. Notably, our algorithm, based on ordinary least squares and semidefinite programming, attains the minimal sample complexity while allowing for efficient computation of an estimate of a system matrix. More specifically, we first establish lower bounds of the sample complexity for any active learning algorithm to attain the prescribed accuracy and confidence levels. Next, we derive a sample complexity upper bound of the proposed algorithm, which matches the lower bound for any algorithm up to universal factors. Our tight bounds are easy to interpret and explicitly show their dependence on the system parameters such as the state dimension.
Receding-Horizon Control via Drifting Models
Apr 06, 2026We study the problem of trajectory optimization in settings where the system dynamics are unknown and it is not possible to simulate trajectories through a surrogate model. When an offline dataset of trajectories is available, an agent could directly learn a trajectory generator by distribution matching. However, this approach only recovers the behavior distribution in the dataset, and does not in general produce a model that minimizes a desired cost criterion. In this work, we propose Drifting MPC, an offline trajectory optimization framework that combines drifting generative models with receding-horizon planning under unknown dynamics. The goal of Drifting MPC is to learn, from an offline dataset of trajectories, a conditional distribution over trajectories that is both supported by the data and biased toward optimal plans. We show that the resulting distribution learned by Drifting MPC is the unique solution of an objective that trades off optimality with closeness to the offline prior. Empirically, we show that Drifting MPC can generate near-optimal trajectories while retaining the one-step inference efficiency of drifting models and substantially reducing generation time relative to diffusion-based baselines.
Adaptive Reinforcement Learning for Unobservable Random Delays
Jun 17, 2025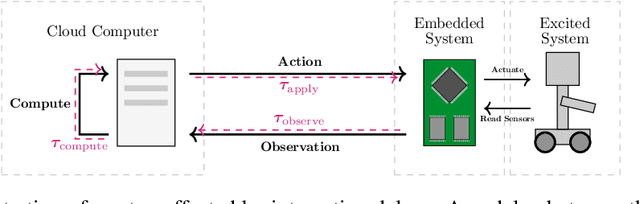
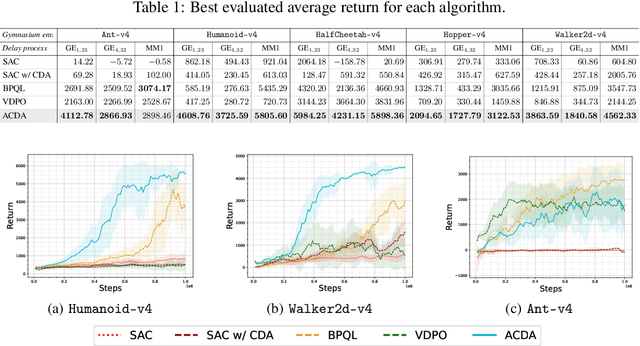
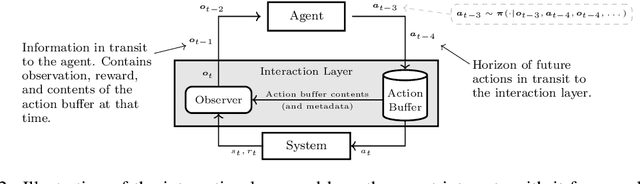
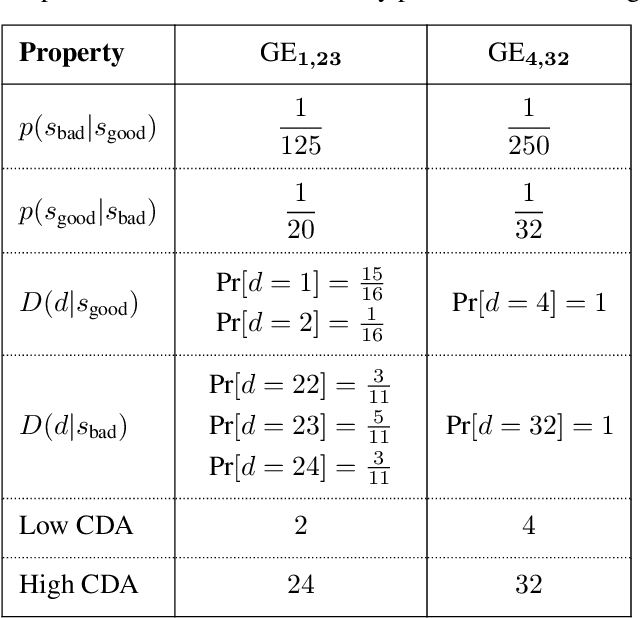
In standard Reinforcement Learning (RL) settings, the interaction between the agent and the environment is typically modeled as a Markov Decision Process (MDP), which assumes that the agent observes the system state instantaneously, selects an action without delay, and executes it immediately. In real-world dynamic environments, such as cyber-physical systems, this assumption often breaks down due to delays in the interaction between the agent and the system. These delays can vary stochastically over time and are typically unobservable, meaning they are unknown when deciding on an action. Existing methods deal with this uncertainty conservatively by assuming a known fixed upper bound on the delay, even if the delay is often much lower. In this work, we introduce the interaction layer, a general framework that enables agents to adaptively and seamlessly handle unobservable and time-varying delays. Specifically, the agent generates a matrix of possible future actions to handle both unpredictable delays and lost action packets sent over networks. Building on this framework, we develop a model-based algorithm, Actor-Critic with Delay Adaptation (ACDA), which dynamically adjusts to delay patterns. Our method significantly outperforms state-of-the-art approaches across a wide range of locomotion benchmark environments.
Policy Testing in Markov Decision Processes
May 21, 2025We study the policy testing problem in discounted Markov decision processes (MDPs) under the fixed-confidence setting. The goal is to determine whether the value of a given policy exceeds a specified threshold while minimizing the number of observations. We begin by deriving an instance-specific lower bound that any algorithm must satisfy. This lower bound is characterized as the solution to an optimization problem with non-convex constraints. We propose a policy testing algorithm inspired by this optimization problem--a common approach in pure exploration problems such as best-arm identification, where asymptotically optimal algorithms often stem from such optimization-based characterizations. As for other pure exploration tasks in MDPs, however, the non-convex constraints in the lower-bound problem present significant challenges, raising doubts about whether statistically optimal and computationally tractable algorithms can be designed. To address this, we reformulate the lower-bound problem by interchanging the roles of the objective and the constraints, yielding an alternative problem with a non-convex objective but convex constraints. Strikingly, this reformulated problem admits an interpretation as a policy optimization task in a newly constructed reversed MDP. Leveraging recent advances in policy gradient methods, we efficiently solve this problem and use it to design a policy testing algorithm that is statistically optimal--matching the instance-specific lower bound on sample complexity--while remaining computationally tractable. We validate our approach with numerical experiments.
Model-free Low-Rank Reinforcement Learning via Leveraged Entry-wise Matrix Estimation
Oct 30, 2024We consider the problem of learning an $\varepsilon$-optimal policy in controlled dynamical systems with low-rank latent structure. For this problem, we present LoRa-PI (Low-Rank Policy Iteration), a model-free learning algorithm alternating between policy improvement and policy evaluation steps. In the latter, the algorithm estimates the low-rank matrix corresponding to the (state, action) value function of the current policy using the following two-phase procedure. The entries of the matrix are first sampled uniformly at random to estimate, via a spectral method, the leverage scores of its rows and columns. These scores are then used to extract a few important rows and columns whose entries are further sampled. The algorithm exploits these new samples to complete the matrix estimation using a CUR-like method. For this leveraged matrix estimation procedure, we establish entry-wise guarantees that remarkably, do not depend on the coherence of the matrix but only on its spikiness. These guarantees imply that LoRa-PI learns an $\varepsilon$-optimal policy using $\widetilde{O}({S+A\over \mathrm{poly}(1-\gamma)\varepsilon^2})$ samples where $S$ (resp. $A$) denotes the number of states (resp. actions) and $\gamma$ the discount factor. Our algorithm achieves this order-optimal (in $S$, $A$ and $\varepsilon$) sample complexity under milder conditions than those assumed in previously proposed approaches.
Conformal Predictions under Markovian Data
Jul 21, 2024We study the split Conformal Prediction method when applied to Markovian data. We quantify the gap in terms of coverage induced by the correlations in the data (compared to exchangeable data). This gap strongly depends on the mixing properties of the underlying Markov chain, and we prove that it typically scales as $\sqrt{t_\mathrm{mix}\ln(n)/n}$ (where $t_\mathrm{mix}$ is the mixing time of the chain). We also derive upper bounds on the impact of the correlations on the size of the prediction set. Finally we present $K$-split CP, a method that consists in thinning the calibration dataset and that adapts to the mixing properties of the chain. Its coverage gap is reduced to $t_\mathrm{mix}/(n\ln(n))$ without really affecting the size of the prediction set. We finally test our algorithms on synthetic and real-world datasets.
Model-Free Active Exploration in Reinforcement Learning
Jun 30, 2024We study the problem of exploration in Reinforcement Learning and present a novel model-free solution. We adopt an information-theoretical viewpoint and start from the instance-specific lower bound of the number of samples that have to be collected to identify a nearly-optimal policy. Deriving this lower bound along with the optimal exploration strategy entails solving an intricate optimization problem and requires a model of the system. In turn, most existing sample optimal exploration algorithms rely on estimating the model. We derive an approximation of the instance-specific lower bound that only involves quantities that can be inferred using model-free approaches. Leveraging this approximation, we devise an ensemble-based model-free exploration strategy applicable to both tabular and continuous Markov decision processes. Numerical results demonstrate that our strategy is able to identify efficient policies faster than state-of-the-art exploration approaches
Low-Rank Bandits via Tight Two-to-Infinity Singular Subspace Recovery
Feb 24, 2024We study contextual bandits with low-rank structure where, in each round, if the (context, arm) pair $(i,j)\in [m]\times [n]$ is selected, the learner observes a noisy sample of the $(i,j)$-th entry of an unknown low-rank reward matrix. Successive contexts are generated randomly in an i.i.d. manner and are revealed to the learner. For such bandits, we present efficient algorithms for policy evaluation, best policy identification and regret minimization. For policy evaluation and best policy identification, we show that our algorithms are nearly minimax optimal. For instance, the number of samples required to return an $\varepsilon$-optimal policy with probability at least $1-\delta$ typically scales as ${m+n\over \varepsilon^2}\log(1/\delta)$. Our regret minimization algorithm enjoys minimax guarantees scaling as $r^{7/4}(m+n)^{3/4}\sqrt{T}$, which improves over existing algorithms. All the proposed algorithms consist of two phases: they first leverage spectral methods to estimate the left and right singular subspaces of the low-rank reward matrix. We show that these estimates enjoy tight error guarantees in the two-to-infinity norm. This in turn allows us to reformulate our problems as a misspecified linear bandit problem with dimension roughly $r(m+n)$ and misspecification controlled by the subspace recovery error, as well as to design the second phase of our algorithms efficiently.
Best Arm Identification with Fixed Budget: A Large Deviation Perspective
Dec 19, 2023We consider the problem of identifying the best arm in stochastic Multi-Armed Bandits (MABs) using a fixed sampling budget. Characterizing the minimal instance-specific error probability for this problem constitutes one of the important remaining open problems in MABs. When arms are selected using a static sampling strategy, the error probability decays exponentially with the number of samples at a rate that can be explicitly derived via Large Deviation techniques. Analyzing the performance of algorithms with adaptive sampling strategies is however much more challenging. In this paper, we establish a connection between the Large Deviation Principle (LDP) satisfied by the empirical proportions of arm draws and that satisfied by the empirical arm rewards. This connection holds for any adaptive algorithm, and is leveraged (i) to improve error probability upper bounds of some existing algorithms, such as the celebrated \sr (Successive Rejects) algorithm \citep{audibert2010best}, and (ii) to devise and analyze new algorithms. In particular, we present \sred (Continuous Rejects), a truly adaptive algorithm that can reject arms in {\it any} round based on the observed empirical gaps between the rewards of various arms. Applying our Large Deviation results, we prove that \sred enjoys better performance guarantees than existing algorithms, including \sr. Extensive numerical experiments confirm this observation.