 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Convergence in Games with Delayed Feedback via Extra Prediction
Feb 19, 2026Feedback delays are inevitable in real-world multi-agent learning. They are known to severely degrade performance, and the convergence rate under delayed feedback is still unclear, even for bilinear games. This paper derives the rate of linear convergence of Weighted Optimistic Gradient Descent-Ascent (WOGDA), which predicts future rewards with extra optimism, in unconstrained bilinear games. To analyze the algorithm, we interpret it as an approximation of the Extra Proximal Point (EPP), which is updated based on farther future rewards than the classical Proximal Point (PP). Our theorems show that standard optimism (predicting the next-step reward) achieves linear convergence to the equilibrium at a rate $\exp(-Θ(t/m^{5}))$ after $t$ iterations for delay $m$. Moreover, employing extra optimism (predicting farther future reward) tolerates a larger step size and significantly accelerates the rate to $\exp(-Θ(t/(m^{2}\log m)))$. Our experiments also show accelerated convergence driven by the extra optimism and are qualitatively consistent with our theorems. In summary, this paper validates that extra optimism is a promising countermeasure against performance degradation caused by feedback delays.
Consensus Group Relative Policy Optimization for Text Generation
Feb 03, 2026Many strong decoding methods for text generation follow a sample-and-rerank paradigm: they draw multiple candidates, score each under a utility (reward) function using consensus across samples, and return the best one. Although effective, these methods incur high computational costs during inference due to repeated sampling and scoring. Prior attempts to amortize inference-time computation typically rely on gold references, teacher labels, or curated preference data, increasing dataset construction effort and the demand for high-fidelity reward models. We propose Consensus Group Relative Policy Optimization (C-GRPO), which distills Minimum Bayes Risk (MBR) decoding into training by formulating the consensus utility as a group-relative objective within GRPO. C-GRPO requires only a utility function and policy samples, without gold references or explicit preference labels. Under ideal conditions, we show that the objective function of C-GRPO is directionally aligned with the gradient of the expected-utility objective underlying MBR decoding, leading to a convergence guarantee. Experiments on machine translation (WMT 2024) and text summarization (XSum) demonstrate that C-GRPO successfully achieves performance comparable to MBR decoding without the associated inference-time overhead, while outperforming reference-free baseline methods.
What you reward is what you learn: Comparing rewards for online speech policy optimization in public HRI
Jan 05, 2026Designing policies that are both efficient and acceptable for conversational service robots in open and diverse environments is non-trivial. Unlike fixed, hand-tuned parameters, online learning can adapt to non-stationary conditions. In this paper, we study how to adapt a social robot's speech policy in the wild. During a 12-day in-situ deployment with over 1,400 public encounters, we cast online policy optimization as a multi-armed bandit problem and use Thompson sampling to select among six actions defined by speech rate (slow/normal/fast) and verbosity (concise/detailed). We compare three complementary binary rewards--Ru (user rating), Rc (conversation closure), and Rt (>=2 turns)--and show that each induces distinct arm distributions and interaction behaviors. We complement the online results with offline evaluations that analyze contextual factors (e.g., crowd level, group size) using video-annotated data. Taken together, we distill ready-to-use design lessons for deploying online optimization of speech policies in real public HRI settings.
Learning from Delayed Feedback in Games via Extra Prediction
Sep 26, 2025This study raises and addresses the problem of time-delayed feedback in learning in games. Because learning in games assumes that multiple agents independently learn their strategies, a discrepancy in optimization often emerges among the agents. To overcome this discrepancy, the prediction of the future reward is incorporated into algorithms, typically known as Optimistic Follow-the-Regularized-Leader (OFTRL). However, the time delay in observing the past rewards hinders the prediction. Indeed, this study firstly proves that even a single-step delay worsens the performance of OFTRL from the aspects of regret and convergence. This study proposes the weighted OFTRL (WOFTRL), where the prediction vector of the next reward in OFTRL is weighted $n$ times. We further capture an intuition that the optimistic weight cancels out this time delay. We prove that when the optimistic weight exceeds the time delay, our WOFTRL recovers the good performances that the regret is constant ($O(1)$-regret) in general-sum normal-form games, and the strategies converge to the Nash equilibrium as a subsequence (best-iterate convergence) in poly-matrix zero-sum games. The theoretical results are supported and strengthened by our experiments.
Policy Testing in Markov Decision Processes
May 21, 2025We study the policy testing problem in discounted Markov decision processes (MDPs) under the fixed-confidence setting. The goal is to determine whether the value of a given policy exceeds a specified threshold while minimizing the number of observations. We begin by deriving an instance-specific lower bound that any algorithm must satisfy. This lower bound is characterized as the solution to an optimization problem with non-convex constraints. We propose a policy testing algorithm inspired by this optimization problem--a common approach in pure exploration problems such as best-arm identification, where asymptotically optimal algorithms often stem from such optimization-based characterizations. As for other pure exploration tasks in MDPs, however, the non-convex constraints in the lower-bound problem present significant challenges, raising doubts about whether statistically optimal and computationally tractable algorithms can be designed. To address this, we reformulate the lower-bound problem by interchanging the roles of the objective and the constraints, yielding an alternative problem with a non-convex objective but convex constraints. Strikingly, this reformulated problem admits an interpretation as a policy optimization task in a newly constructed reversed MDP. Leveraging recent advances in policy gradient methods, we efficiently solve this problem and use it to design a policy testing algorithm that is statistically optimal--matching the instance-specific lower bound on sample complexity--while remaining computationally tractable. We validate our approach with numerical experiments.
Theoretical Guarantees for Minimum Bayes Risk Decoding
Feb 18, 2025Minimum Bayes Risk (MBR) decoding optimizes output selection by maximizing the expected utility value of an underlying human distribution. While prior work has shown the effectiveness of MBR decoding through empirical evaluation, few studies have analytically investigated why the method is effective. As a result of our analysis, we show that, given the size $n$ of the reference hypothesis set used in computation, MBR decoding approaches the optimal solution with high probability at a rate of $O\left(n^{-\frac{1}{2}}\right)$, under certain assumptions, even though the language space $Y$ is significantly larger $Y\gg n$. This result helps to theoretically explain the strong performance observed in several prior empirical studies on MBR decoding. In addition, we provide the performance gap for maximum-a-posteriori (MAP) decoding and compare it to MBR decoding. The result of this paper indicates that MBR decoding tends to converge to the optimal solution faster than MAP decoding in several cases.
Evaluation of Best-of-N Sampling Strategies for Language Model Alignment
Feb 18, 2025



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) with human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Since the reward model is an imperfect proxy for the true objective, an excessive focus on optimizing its value can lead to a compromise of its performance on the true objective. Previous work proposes Regularized BoN sampling (RBoN), a BoN sampling with regularization to the objective, and shows that it outperforms BoN sampling so that it mitigates reward hacking and empirically (Jinnai et al., 2024). However, Jinnai et al. (2024) introduce RBoN based on a heuristic and they lack the analysis of why such regularization strategy improves the performance of BoN sampling. The aim of this study is to analyze the effect of BoN sampling on regularization strategies. Using the regularization strategies corresponds to robust optimization, which maximizes the worst case over a set of possible perturbations in the proxy reward. Although the theoretical guarantees are not directly applicable to RBoN, RBoN corresponds to a practical implementation. This paper proposes an extension of the RBoN framework, called Stochastic RBoN sampling (SRBoN), which is a theoretically guaranteed approach to worst-case RBoN in proxy reward. We then perform an empirical evaluation using the AlpacaFarm and Anthropic's hh-rlhf datasets to evaluate which factors of the regularization strategies contribute to the improvement of the true proxy reward. In addition, we also propose another simple RBoN method, the Sentence Length Regularized BoN, which has a better performance in the experiment as compared to the previous methods.
The Power of Perturbation under Sampling in Solving Extensive-Form Games
Jan 28, 2025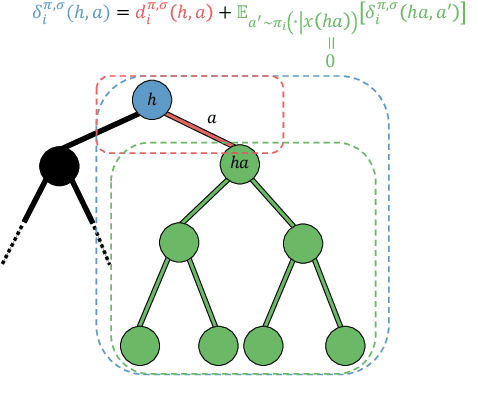
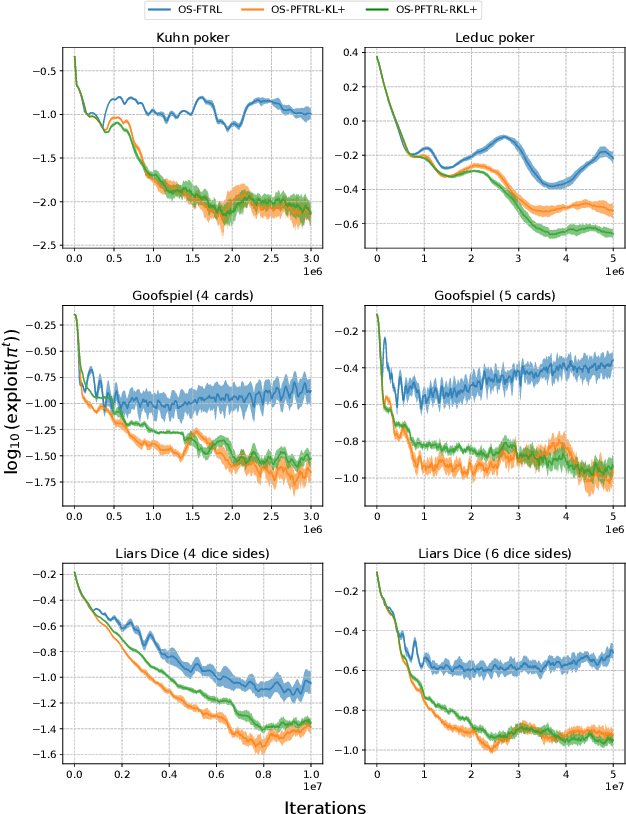
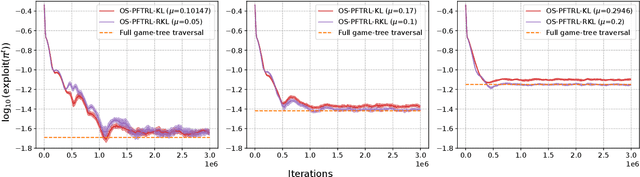
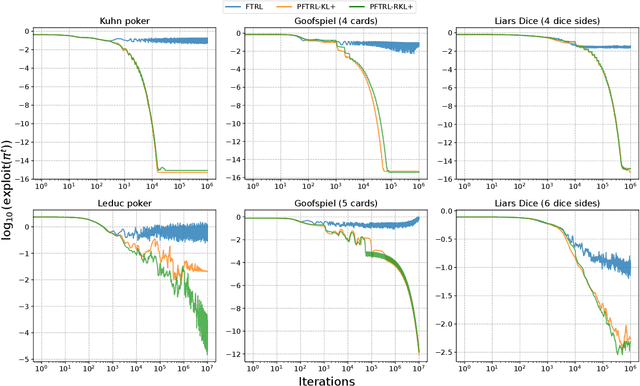
This paper investigates how perturbation does and does not improve the Follow-the-Regularized-Leader (FTRL) algorithm in imperfect-information extensive-form games. Perturbing the expected payoffs guarantees that the FTRL dynamics reach an approximate equilibrium, and proper adjustments of the magnitude of the perturbation lead to a Nash equilibrium (\textit{last-iterate convergence}). This approach is robust even when payoffs are estimated using sampling -- as is the case for large games -- while the optimistic approach often becomes unstable. Building upon those insights, we first develop a general framework for perturbed FTRL algorithms under \textit{sampling}. We then empirically show that in the last-iterate sense, the perturbed FTRL consistently outperforms the non-perturbed FTRL. We further identify a divergence function that reduces the variance of the estimates for perturbed payoffs, with which it significantly outperforms the prior algorithms on Leduc poker (whose structure is more asymmetric in a sense than that of the other benchmark games) and consistently performs smooth convergence behavior on all the benchmark games.
Last Iterate Convergence in Monotone Mean Field Games
Oct 07, 2024

Mean Field Game (MFG) is a framework utilized to model and approximate the behavior of a large number of agents, and the computation of equilibria in MFG has been a subject of interest. Despite the proposal of methods to approximate the equilibria, algorithms where the sequence of updated policy converges to equilibrium, specifically those exhibiting last-iterate convergence, have been limited. We propose the use of a simple, proximal-point-type algorithm to compute equilibria for MFGs. Subsequently, we provide the first last-iterate convergence guarantee under the Lasry--Lions-type monotonicity condition. We further employ the Mirror Descent algorithm for the regularized MFG to efficiently approximate the update rules of the proximal point method for MFGs. We demonstrate that the algorithm can approximate with an accuracy of $\varepsilon$ after $\mathcal{O}({\log(1/\varepsilon)})$ iterations. This research offers a tractable approach for large-scale and large-population games.
Matroid Semi-Bandits in Sublinear Time
May 28, 2024We study the matroid semi-bandits problem, where at each round the learner plays a subset of $K$ arms from a feasible set, and the goal is to maximize the expected cumulative linear rewards. Existing algorithms have per-round time complexity at least $\Omega(K)$, which becomes expensive when $K$ is large. To address this computational issue, we propose FasterCUCB whose sampling rule takes time sublinear in $K$ for common classes of matroids: $O(D\text{ polylog}(K)\text{ polylog}(T))$ for uniform matroids, partition matroids, and graphical matroids, and $O(D\sqrt{K}\text{ polylog}(T))$ for transversal matroids. Here, $D$ is the maximum number of elements in any feasible subset of arms, and $T$ is the horizon. Our technique is based on dynamic maintenance of an approximate maximum-weight basis over inner-product weights. Although the introduction of an approximate maximum-weight basis presents a challenge in regret analysis, we can still guarantee an upper bound on regret as tight as CUCB in the sense that it matches the gap-dependent lower bound by Kveton et al. (2014a) asymptotically.