 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Locality in Hierarchical Recursive Reasoning
May 20, 2026Spatial reasoning requires both location-bound computation and location-invariant structure: agents must make local moves while preserving route, object, or constraint-level plans. We propose interaction locality, a task-geometry-aware framework for measuring whether information flow stays within nearby cells or semantic segments, or crosses them. We instantiate the framework with sparse-autoencoder feature ablations and finite-noise activation patching, with structural Jacobian and attention checks reported in the appendix, and apply it to HRM and TRM, two compact hierarchical and recursive reasoning models, on Maze-Hard, Sudoku Extreme, and ARC-AGI. Across these models, activation patching gives the clearest architectural fingerprint: high-level recurrent states tend to write information within nearby cells or same-segment units, while repeated recursive updates accumulate these local writes into broader solution structure. This pattern holds across maze paths, Sudoku constraints, and ARC-AGI object neighborhoods, with the strongest concentration in TRM. To test whether interaction locality extends beyond toy-yet-challenging grid benchmarks, we also apply it to MTU3D, a large-scale embodied 3D scene-grounding model. In this MTU3D setting, causal spatial locality appears primarily at the transition where visual scene features are handed to the downstream grounding module, rather than uniformly throughout the visual encoder. This contrast suggests that the local-to-global handoff observed in HRM and TRM is tied to explicit recursive reasoning dynamics, while embodied 3D models may concentrate causal spatial structure at module boundaries. Interaction locality turns the intuitive local-execution/global-planning story into a reproducible measurement framework for recursive and embodied spatial reasoning.
MO-GRPO: Mitigating Reward Hacking of Group Relative Policy Optimization on Multi-Objective Problems
Sep 26, 2025Group Relative Policy Optimization (GRPO) has been shown to be an effective algorithm when an accurate reward model is available. However, such a highly reliable reward model is not available in many real-world tasks. In this paper, we particularly focus on multi-objective settings, in which we identify that GRPO is vulnerable to reward hacking, optimizing only one of the objectives at the cost of the others. To address this issue, we propose MO-GRPO, an extension of GRPO with a simple normalization method to reweight the reward functions automatically according to the variances of their values. We first show analytically that MO-GRPO ensures that all reward functions contribute evenly to the loss function while preserving the order of preferences, eliminating the need for manual tuning of the reward functions' scales. Then, we evaluate MO-GRPO experimentally in four domains: (i) the multi-armed bandits problem, (ii) simulated control task (Mo-Gymnasium), (iii) machine translation tasks on the WMT benchmark (En-Ja, En-Zh), and (iv) instruction following task. MO-GRPO achieves stable learning by evenly distributing correlations among the components of rewards, outperforming GRPO, showing MO-GRPO to be a promising algorithm for multi-objective reinforcement learning problems.
Theoretical Guarantees for Minimum Bayes Risk Decoding
Feb 18, 2025Minimum Bayes Risk (MBR) decoding optimizes output selection by maximizing the expected utility value of an underlying human distribution. While prior work has shown the effectiveness of MBR decoding through empirical evaluation, few studies have analytically investigated why the method is effective. As a result of our analysis, we show that, given the size $n$ of the reference hypothesis set used in computation, MBR decoding approaches the optimal solution with high probability at a rate of $O\left(n^{-\frac{1}{2}}\right)$, under certain assumptions, even though the language space $Y$ is significantly larger $Y\gg n$. This result helps to theoretically explain the strong performance observed in several prior empirical studies on MBR decoding. In addition, we provide the performance gap for maximum-a-posteriori (MAP) decoding and compare it to MBR decoding. The result of this paper indicates that MBR decoding tends to converge to the optimal solution faster than MAP decoding in several cases.
Evaluation of Best-of-N Sampling Strategies for Language Model Alignment
Feb 18, 2025



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) with human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Since the reward model is an imperfect proxy for the true objective, an excessive focus on optimizing its value can lead to a compromise of its performance on the true objective. Previous work proposes Regularized BoN sampling (RBoN), a BoN sampling with regularization to the objective, and shows that it outperforms BoN sampling so that it mitigates reward hacking and empirically (Jinnai et al., 2024). However, Jinnai et al. (2024) introduce RBoN based on a heuristic and they lack the analysis of why such regularization strategy improves the performance of BoN sampling. The aim of this study is to analyze the effect of BoN sampling on regularization strategies. Using the regularization strategies corresponds to robust optimization, which maximizes the worst case over a set of possible perturbations in the proxy reward. Although the theoretical guarantees are not directly applicable to RBoN, RBoN corresponds to a practical implementation. This paper proposes an extension of the RBoN framework, called Stochastic RBoN sampling (SRBoN), which is a theoretically guaranteed approach to worst-case RBoN in proxy reward. We then perform an empirical evaluation using the AlpacaFarm and Anthropic's hh-rlhf datasets to evaluate which factors of the regularization strategies contribute to the improvement of the true proxy reward. In addition, we also propose another simple RBoN method, the Sentence Length Regularized BoN, which has a better performance in the experiment as compared to the previous methods.
Reinforcement Learning for Edit-Based Non-Autoregressive Neural Machine Translation
May 02, 2024



Non-autoregressive (NAR) language models are known for their low latency in neural machine translation (NMT). However, a performance gap exists between NAR and autoregressive models due to the large decoding space and difficulty in capturing dependency between target words accurately. Compounding this, preparing appropriate training data for NAR models is a non-trivial task, often exacerbating exposure bias. To address these challenges, we apply reinforcement learning (RL) to Levenshtein Transformer, a representative edit-based NAR model, demonstrating that RL with self-generated data can enhance the performance of edit-based NAR models. We explore two RL approaches: stepwise reward maximization and episodic reward maximization. We discuss the respective pros and cons of these two approaches and empirically verify them. Moreover, we experimentally investigate the impact of temperature setting on performance, confirming the importance of proper temperature setting for NAR models' training.
Filtered Direct Preference Optimization
Apr 23, 2024



Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
Regularized Best-of-N Sampling to Mitigate Reward Hacking for Language Model Alignment
Apr 05, 2024



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) to human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Because the reward model is an imperfect proxy for the true objective, over-optimizing its value can compromise its performance on the true objective. A common solution to prevent reward hacking in preference learning techniques is to optimize a reward using proximity regularization (e.g., KL regularization), which ensures that the language model remains close to the reference model. In this research, we propose Regularized Best-of-N (RBoN), a variant of BoN that aims to mitigate reward hacking by incorporating a proximity term in response selection, similar to preference learning techniques. We evaluate two variants of RBoN on the AlpacaFarm dataset and find that they outperform BoN, especially when the proxy reward model has a low correlation with the true objective.
On the True Distribution Approximation of Minimum Bayes-Risk Decoding
Mar 31, 2024Minimum Bayes-risk (MBR) decoding has recently gained renewed attention in text generation. MBR decoding considers texts sampled from a model as pseudo-references and selects the text with the highest similarity to the others. Therefore, sampling is one of the key elements of MBR decoding, and previous studies reported that the performance varies by sampling methods. From a theoretical standpoint, this performance variation is likely tied to how closely the samples approximate the true distribution of references. However, this approximation has not been the subject of in-depth study. In this study, we propose using anomaly detection to measure the degree of approximation. We first closely examine the performance variation and then show that previous hypotheses about samples do not correlate well with the variation, but our introduced anomaly scores do. The results are the first to empirically support the link between the performance and the core assumption of MBR decoding.
Return-Aligned Decision Transformer
Feb 06, 2024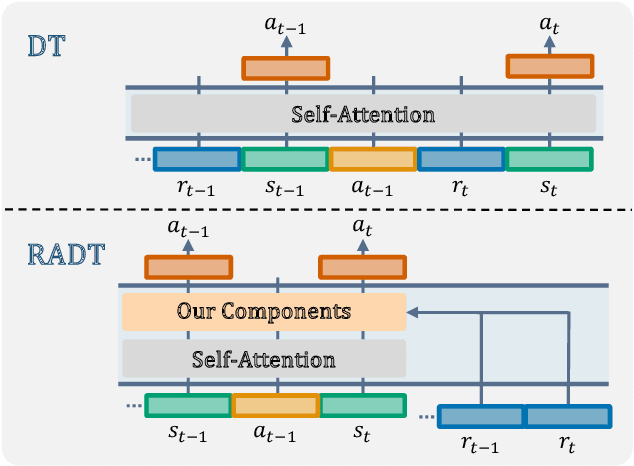
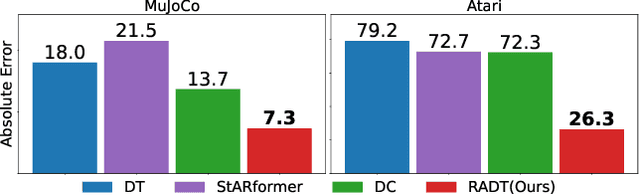
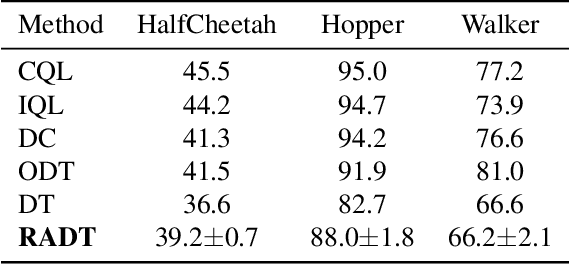
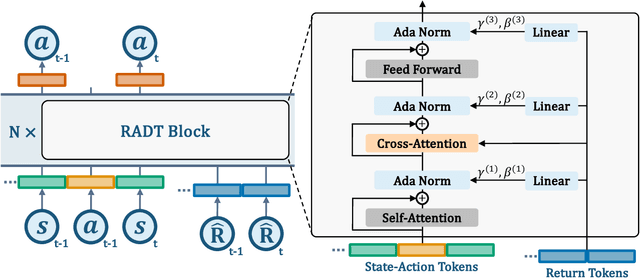
Traditional approaches in offline reinforcement learning aim to learn the optimal policy that maximizes the cumulative reward, also known as return. However, as applications broaden, it becomes increasingly crucial to train agents that not only maximize the returns, but align the actual return with a specified target return, giving control over the agent's performance. Decision Transformer (DT) optimizes a policy that generates actions conditioned on the target return through supervised learning and is equipped with a mechanism to control the agent using the target return. Despite being designed to align the actual return with the target return, we have empirically identified a discrepancy between the actual return and the target return in DT. In this paper, we propose Return-Aligned Decision Transformer (RADT), designed to effectively align the actual return with the target return. Our model decouples returns from the conventional input sequence, which typically consists of returns, states, and actions, to enhance the relationships between returns and states, as well as returns and actions. Extensive experiments show that RADT reduces the discrepancies between the actual return and the target return of DT-based methods.
Generating Diverse and High-Quality Texts by Minimum Bayes Risk Decoding
Jan 10, 2024



One of the most important challenges in text generation systems is to produce outputs that are not only correct but also diverse. Recently, Minimum Bayes-Risk (MBR) decoding has gained prominence for generating sentences of the highest quality among the decoding algorithms. However, existing algorithms proposed for generating diverse outputs are predominantly based on beam search or random sampling, thus their output quality is capped by these underlying methods. In this paper, we investigate an alternative approach -- we develop diversity-promoting decoding algorithms by enforcing diversity objectives to MBR decoding. We propose two variants of MBR, Diverse MBR (DMBR) and $k$-medoids MBR (KMBR), methods to generate a set of sentences with high quality and diversity. We evaluate DMBR and KMBR on a variety of directed text generation tasks using encoder-decoder models and a large language model with prompting. The experimental results show that the proposed method achieves a better trade-off than the diverse beam search and sampling algorithms.