 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-GRPO: Mitigating Reward Hacking of Group Relative Policy Optimization on Multi-Objective Problems
Sep 26, 2025Group Relative Policy Optimization (GRPO) has been shown to be an effective algorithm when an accurate reward model is available. However, such a highly reliable reward model is not available in many real-world tasks. In this paper, we particularly focus on multi-objective settings, in which we identify that GRPO is vulnerable to reward hacking, optimizing only one of the objectives at the cost of the others. To address this issue, we propose MO-GRPO, an extension of GRPO with a simple normalization method to reweight the reward functions automatically according to the variances of their values. We first show analytically that MO-GRPO ensures that all reward functions contribute evenly to the loss function while preserving the order of preferences, eliminating the need for manual tuning of the reward functions' scales. Then, we evaluate MO-GRPO experimentally in four domains: (i) the multi-armed bandits problem, (ii) simulated control task (Mo-Gymnasium), (iii) machine translation tasks on the WMT benchmark (En-Ja, En-Zh), and (iv) instruction following task. MO-GRPO achieves stable learning by evenly distributing correlations among the components of rewards, outperforming GRPO, showing MO-GRPO to be a promising algorithm for multi-objective reinforcement learning problems.
Evaluation of Best-of-N Sampling Strategies for Language Model Alignment
Feb 18, 2025



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) with human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Since the reward model is an imperfect proxy for the true objective, an excessive focus on optimizing its value can lead to a compromise of its performance on the true objective. Previous work proposes Regularized BoN sampling (RBoN), a BoN sampling with regularization to the objective, and shows that it outperforms BoN sampling so that it mitigates reward hacking and empirically (Jinnai et al., 2024). However, Jinnai et al. (2024) introduce RBoN based on a heuristic and they lack the analysis of why such regularization strategy improves the performance of BoN sampling. The aim of this study is to analyze the effect of BoN sampling on regularization strategies. Using the regularization strategies corresponds to robust optimization, which maximizes the worst case over a set of possible perturbations in the proxy reward. Although the theoretical guarantees are not directly applicable to RBoN, RBoN corresponds to a practical implementation. This paper proposes an extension of the RBoN framework, called Stochastic RBoN sampling (SRBoN), which is a theoretically guaranteed approach to worst-case RBoN in proxy reward. We then perform an empirical evaluation using the AlpacaFarm and Anthropic's hh-rlhf datasets to evaluate which factors of the regularization strategies contribute to the improvement of the true proxy reward. In addition, we also propose another simple RBoN method, the Sentence Length Regularized BoN, which has a better performance in the experiment as compared to the previous methods.
The Power of Perturbation under Sampling in Solving Extensive-Form Games
Jan 28, 2025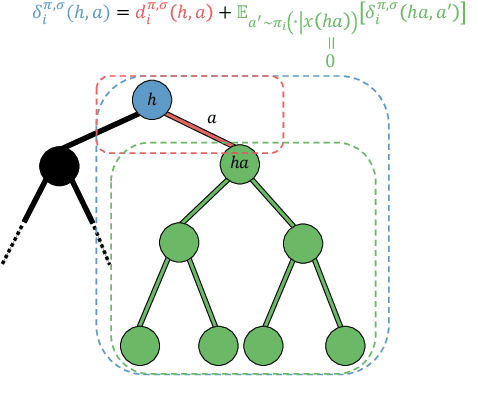
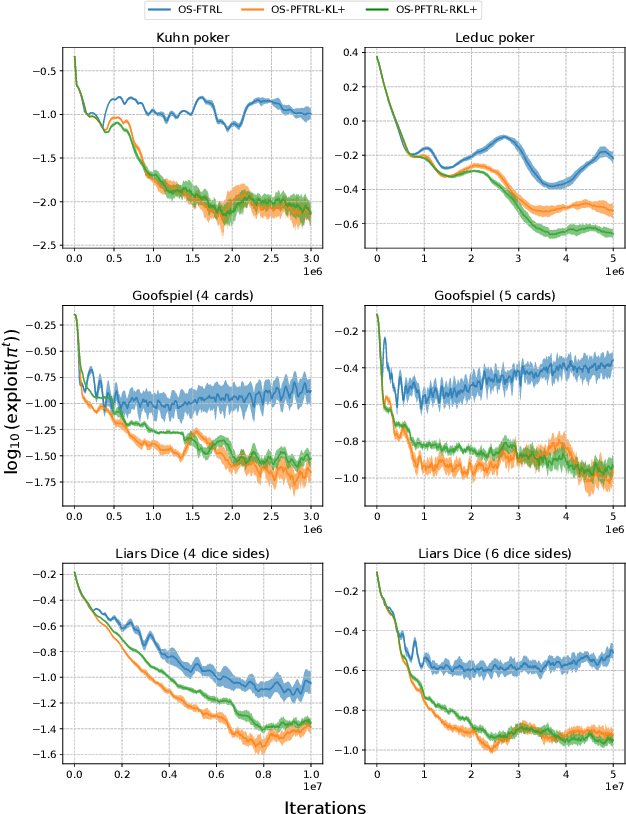
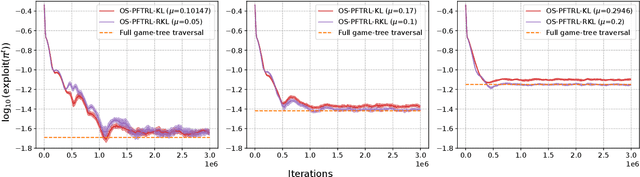
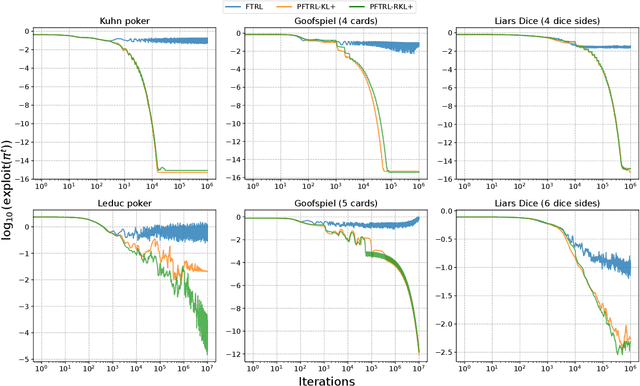
This paper investigates how perturbation does and does not improve the Follow-the-Regularized-Leader (FTRL) algorithm in imperfect-information extensive-form games. Perturbing the expected payoffs guarantees that the FTRL dynamics reach an approximate equilibrium, and proper adjustments of the magnitude of the perturbation lead to a Nash equilibrium (\textit{last-iterate convergence}). This approach is robust even when payoffs are estimated using sampling -- as is the case for large games -- while the optimistic approach often becomes unstable. Building upon those insights, we first develop a general framework for perturbed FTRL algorithms under \textit{sampling}. We then empirically show that in the last-iterate sense, the perturbed FTRL consistently outperforms the non-perturbed FTRL. We further identify a divergence function that reduces the variance of the estimates for perturbed payoffs, with which it significantly outperforms the prior algorithms on Leduc poker (whose structure is more asymmetric in a sense than that of the other benchmark games) and consistently performs smooth convergence behavior on all the benchmark games.
Filtered Direct Preference Optimization
Apr 23, 2024



Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
A Slingshot Approach to Learning in Monotone Games
May 26, 2023In this paper, we address the problem of computing equilibria in monotone games. The traditional Follow the Regularized Leader algorithms fail to converge to an equilibrium even in two-player zero-sum games. Although optimistic versions of these algorithms have been proposed with last-iterate convergence guarantees, they require noiseless gradient feedback. To overcome this limitation, we present a novel framework that achieves last-iterate convergence even in the presence of noise. Our key idea involves perturbing or regularizing the payoffs or utilities of the games. This perturbation serves to pull the current strategy to an anchored strategy, which we refer to as a {\it slingshot} strategy. First, we establish the convergence rates of our framework to a stationary point near an equilibrium, regardless of the presence or absence of noise. Next, we introduce an approach to periodically update the slingshot strategy with the current strategy. We interpret this approach as a proximal point method and demonstrate its last-iterate convergence. Our framework is comprehensive, incorporating existing payoff-regularized algorithms and enabling the development of new algorithms with last-iterate convergence properties. Finally, we show that our algorithms, based on this framework, empirically exhibit faster convergence.
Last-Iterate Convergence with Full- and Noisy-Information Feedback in Two-Player Zero-Sum Games
Aug 21, 2022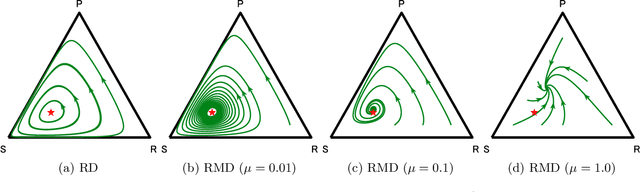
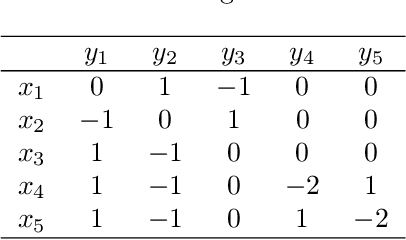
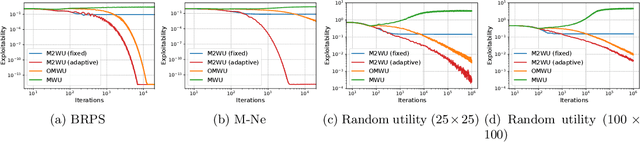

The theory of learning in games is prominent in the AI community, motivated by several rising applications such as multi-agent reinforcement learning and Generative Adversarial Networks. We propose Mutation-driven Multiplicative Weights Update (M2WU) for learning an equilibrium in two-player zero-sum normal-form games and prove that it exhibits the last-iterate convergence property in both full- and noisy-information feedback settings. In the full-information feedback setting, the players observe their exact gradient vectors of the utility functions. On the other hand, in the noisy-information feedback setting, they can only observe the noisy gradient vectors. Existing algorithms, including the well-known Multiplicative Weights Update (MWU) and Optimistic MWU (OMWU) algorithms, fail to converge to a Nash equilibrium with noisy-information feedback. In contrast, M2WU exhibits the last-iterate convergence to a stationary point near a Nash equilibrium in both of the feedback settings. We then prove that it converges to an exact Nash equilibrium by adapting the mutation term iteratively. We empirically confirm that M2WU outperforms MWU and OMWU in exploitability and convergence rates.
Mutation-Driven Follow the Regularized Leader for Last-Iterate Convergence in Zero-Sum Games
Jun 18, 2022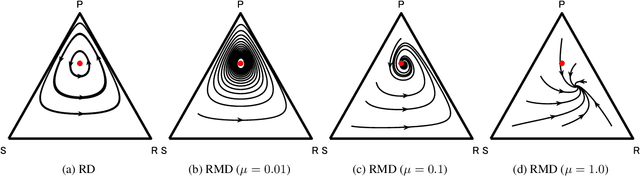


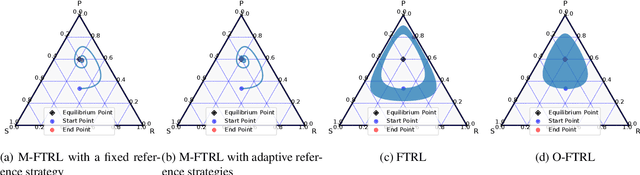
In this study, we consider a variant of the Follow the Regularized Leader (FTRL) dynamics in two-player zero-sum games. FTRL is guaranteed to converge to a Nash equilibrium when time-averaging the strategies, while a lot of variants suffer from the issue of limit cycling behavior, i.e., lack the last-iterate convergence guarantee. To this end, we propose mutant FTRL (M-FTRL), an algorithm that introduces mutation for the perturbation of action probabilities. We then investigate the continuous-time dynamics of M-FTRL and provide the strong convergence guarantees toward stationary points that approximate Nash equilibria under full-information feedback. Furthermore, our simulation demonstrates that M-FTRL can enjoy faster convergence rates than FTRL and optimistic FTRL under full-information feedback and surprisingly exhibits clear convergence under bandit feedback.
Automated Segmentation of Hip and Thigh Muscles in Metal Artifact-Contaminated CT using Convolutional Neural Network-Enhanced Normalized Metal Artifact Reduction
Jun 27, 2019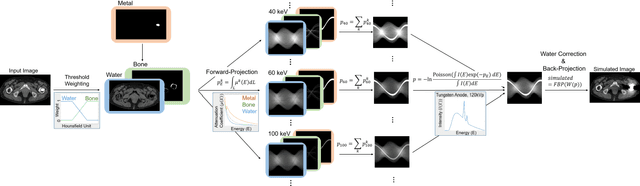
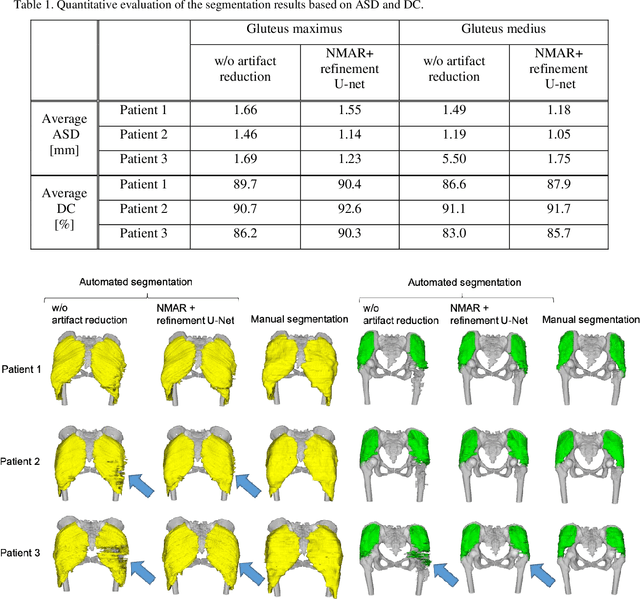
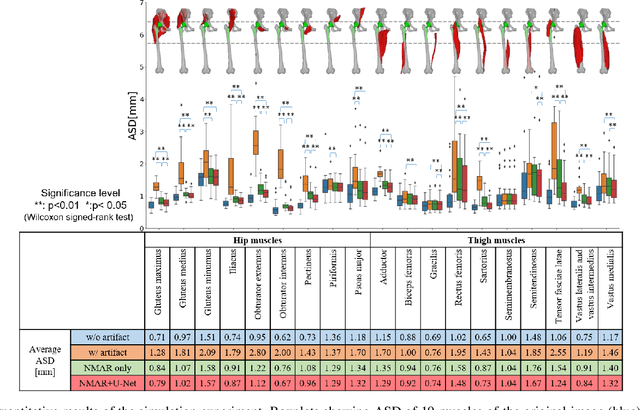
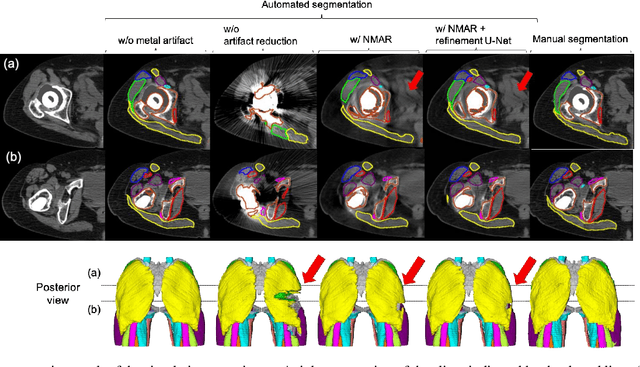
In total hip arthroplasty, analysis of postoperative medical images is important to evaluate surgical outcome. Since Computed Tomography (CT) is most prevalent modality in orthopedic surgery, we aimed at the analysis of CT image. In this work, we focus on the metal artifact in postoperative CT caused by the metallic implant, which reduces the accuracy of segmentation especially in the vicinity of the implant. Our goal was to develop an automated segmentation method of the bones and muscles in the postoperative CT images. We propose a method that combines Normalized Metal Artifact Reduction (NMAR), which is one of the state-of-the-art metal artifact reduction methods, and a Convolutional Neural Network-based segmentation using two U-net architectures. The first U-net refines the result of NMAR and the muscle segmentation is performed by the second U-net. We conducted experiments using simulated images of 20 patients and real images of three patients to evaluate the segmentation accuracy of 19 muscles. In simulation study, the proposed method showed statistically significant improvement (p<0.05) in the average symmetric surface distance (ASD) metric for 14 muscles out of 19 muscles and the average ASD of all muscles from 1.17 +/- 0.543 mm (mean +/- std over all patients) to 1.10 +/- 0.509 mm over our previous method. The real image study using the manual trace of gluteus maximus and medius muscles showed ASD of 1.32 +/- 0.25 mm. Our future work includes training of a network in an end-to-end manner for both the metal artifact reduction and muscle segmentation.