 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLast-Iterate Convergence with Full- and Noisy-Information Feedback in Two-Player Zero-Sum Games
Paper and Code
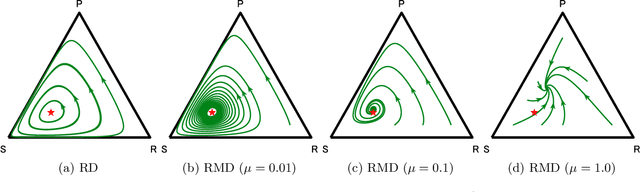
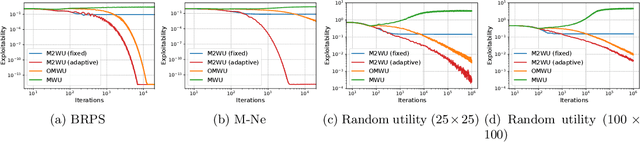

The theory of learning in games is prominent in the AI community, motivated by several rising applications such as multi-agent reinforcement learning and Generative Adversarial Networks. We propose Mutation-driven Multiplicative Weights Update (M2WU) for learning an equilibrium in two-player zero-sum normal-form games and prove that it exhibits the last-iterate convergence property in both full- and noisy-information feedback settings. In the full-information feedback setting, the players observe their exact gradient vectors of the utility functions. On the other hand, in the noisy-information feedback setting, they can only observe the noisy gradient vectors. Existing algorithms, including the well-known Multiplicative Weights Update (MWU) and Optimistic MWU (OMWU) algorithms, fail to converge to a Nash equilibrium with noisy-information feedback. In contrast, M2WU exhibits the last-iterate convergence to a stationary point near a Nash equilibrium in both of the feedback settings. We then prove that it converges to an exact Nash equilibrium by adapting the mutation term iteratively. We empirically confirm that M2WU outperforms MWU and OMWU in exploitability and convergence rates.