 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Convergence in Games with Delayed Feedback via Extra Prediction
Feb 19, 2026Feedback delays are inevitable in real-world multi-agent learning. They are known to severely degrade performance, and the convergence rate under delayed feedback is still unclear, even for bilinear games. This paper derives the rate of linear convergence of Weighted Optimistic Gradient Descent-Ascent (WOGDA), which predicts future rewards with extra optimism, in unconstrained bilinear games. To analyze the algorithm, we interpret it as an approximation of the Extra Proximal Point (EPP), which is updated based on farther future rewards than the classical Proximal Point (PP). Our theorems show that standard optimism (predicting the next-step reward) achieves linear convergence to the equilibrium at a rate $\exp(-Θ(t/m^{5}))$ after $t$ iterations for delay $m$. Moreover, employing extra optimism (predicting farther future reward) tolerates a larger step size and significantly accelerates the rate to $\exp(-Θ(t/(m^{2}\log m)))$. Our experiments also show accelerated convergence driven by the extra optimism and are qualitatively consistent with our theorems. In summary, this paper validates that extra optimism is a promising countermeasure against performance degradation caused by feedback delays.
Learning from Delayed Feedback in Games via Extra Prediction
Sep 26, 2025This study raises and addresses the problem of time-delayed feedback in learning in games. Because learning in games assumes that multiple agents independently learn their strategies, a discrepancy in optimization often emerges among the agents. To overcome this discrepancy, the prediction of the future reward is incorporated into algorithms, typically known as Optimistic Follow-the-Regularized-Leader (OFTRL). However, the time delay in observing the past rewards hinders the prediction. Indeed, this study firstly proves that even a single-step delay worsens the performance of OFTRL from the aspects of regret and convergence. This study proposes the weighted OFTRL (WOFTRL), where the prediction vector of the next reward in OFTRL is weighted $n$ times. We further capture an intuition that the optimistic weight cancels out this time delay. We prove that when the optimistic weight exceeds the time delay, our WOFTRL recovers the good performances that the regret is constant ($O(1)$-regret) in general-sum normal-form games, and the strategies converge to the Nash equilibrium as a subsequence (best-iterate convergence) in poly-matrix zero-sum games. The theoretical results are supported and strengthened by our experiments.
Policy Testing in Markov Decision Processes
May 21, 2025We study the policy testing problem in discounted Markov decision processes (MDPs) under the fixed-confidence setting. The goal is to determine whether the value of a given policy exceeds a specified threshold while minimizing the number of observations. We begin by deriving an instance-specific lower bound that any algorithm must satisfy. This lower bound is characterized as the solution to an optimization problem with non-convex constraints. We propose a policy testing algorithm inspired by this optimization problem--a common approach in pure exploration problems such as best-arm identification, where asymptotically optimal algorithms often stem from such optimization-based characterizations. As for other pure exploration tasks in MDPs, however, the non-convex constraints in the lower-bound problem present significant challenges, raising doubts about whether statistically optimal and computationally tractable algorithms can be designed. To address this, we reformulate the lower-bound problem by interchanging the roles of the objective and the constraints, yielding an alternative problem with a non-convex objective but convex constraints. Strikingly, this reformulated problem admits an interpretation as a policy optimization task in a newly constructed reversed MDP. Leveraging recent advances in policy gradient methods, we efficiently solve this problem and use it to design a policy testing algorithm that is statistically optimal--matching the instance-specific lower bound on sample complexity--while remaining computationally tractable. We validate our approach with numerical experiments.
Evaluation of Best-of-N Sampling Strategies for Language Model Alignment
Feb 18, 2025



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) with human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Since the reward model is an imperfect proxy for the true objective, an excessive focus on optimizing its value can lead to a compromise of its performance on the true objective. Previous work proposes Regularized BoN sampling (RBoN), a BoN sampling with regularization to the objective, and shows that it outperforms BoN sampling so that it mitigates reward hacking and empirically (Jinnai et al., 2024). However, Jinnai et al. (2024) introduce RBoN based on a heuristic and they lack the analysis of why such regularization strategy improves the performance of BoN sampling. The aim of this study is to analyze the effect of BoN sampling on regularization strategies. Using the regularization strategies corresponds to robust optimization, which maximizes the worst case over a set of possible perturbations in the proxy reward. Although the theoretical guarantees are not directly applicable to RBoN, RBoN corresponds to a practical implementation. This paper proposes an extension of the RBoN framework, called Stochastic RBoN sampling (SRBoN), which is a theoretically guaranteed approach to worst-case RBoN in proxy reward. We then perform an empirical evaluation using the AlpacaFarm and Anthropic's hh-rlhf datasets to evaluate which factors of the regularization strategies contribute to the improvement of the true proxy reward. In addition, we also propose another simple RBoN method, the Sentence Length Regularized BoN, which has a better performance in the experiment as compared to the previous methods.
The Power of Perturbation under Sampling in Solving Extensive-Form Games
Jan 28, 2025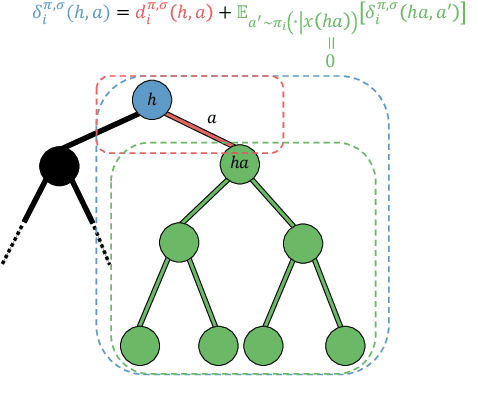
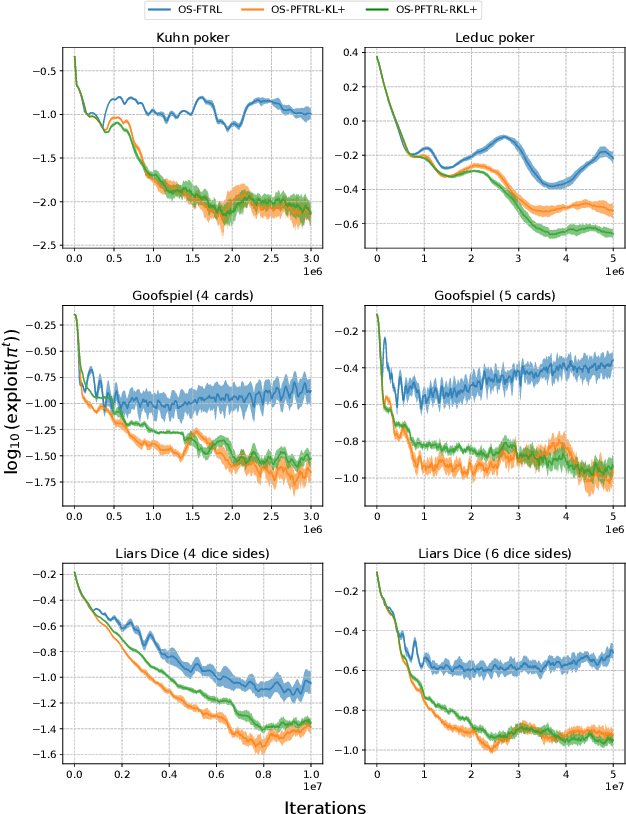
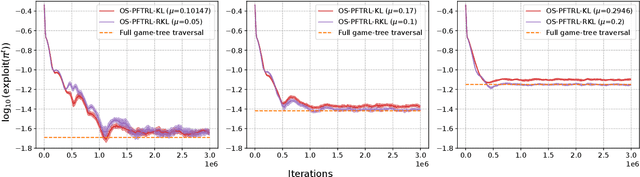
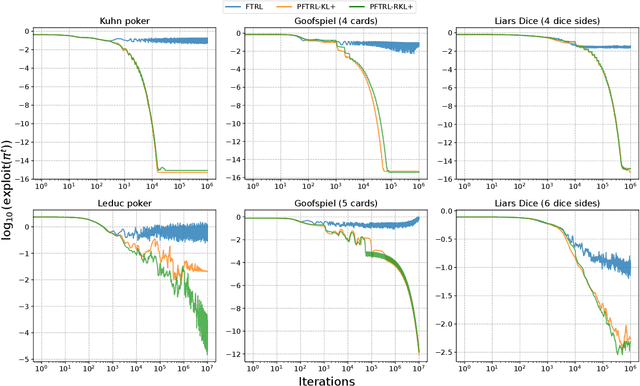
This paper investigates how perturbation does and does not improve the Follow-the-Regularized-Leader (FTRL) algorithm in imperfect-information extensive-form games. Perturbing the expected payoffs guarantees that the FTRL dynamics reach an approximate equilibrium, and proper adjustments of the magnitude of the perturbation lead to a Nash equilibrium (\textit{last-iterate convergence}). This approach is robust even when payoffs are estimated using sampling -- as is the case for large games -- while the optimistic approach often becomes unstable. Building upon those insights, we first develop a general framework for perturbed FTRL algorithms under \textit{sampling}. We then empirically show that in the last-iterate sense, the perturbed FTRL consistently outperforms the non-perturbed FTRL. We further identify a divergence function that reduces the variance of the estimates for perturbed payoffs, with which it significantly outperforms the prior algorithms on Leduc poker (whose structure is more asymmetric in a sense than that of the other benchmark games) and consistently performs smooth convergence behavior on all the benchmark games.
Approximate State Abstraction for Markov Games
Dec 20, 2024This paper introduces state abstraction for two-player zero-sum Markov games (TZMGs), where the payoffs for the two players are determined by the state representing the environment and their respective actions, with state transitions following Markov decision processes. For example, in games like soccer, the value of actions changes according to the state of play, and thus such games should be described as Markov games. In TZMGs, as the number of states increases, computing equilibria becomes more difficult. Therefore, we consider state abstraction, which reduces the number of states by treating multiple different states as a single state. There is a substantial body of research on finding optimal policies for Markov decision processes using state abstraction. However, in the multi-player setting, the game with state abstraction may yield different equilibrium solutions from those of the ground game. To evaluate the equilibrium solutions of the game with state abstraction, we derived bounds on the duality gap, which represents the distance from the equilibrium solutions of the ground game. Finally, we demonstrate our state abstraction with Markov Soccer, compute equilibrium policies, and examine the results.
Last Iterate Convergence in Monotone Mean Field Games
Oct 07, 2024

Mean Field Game (MFG) is a framework utilized to model and approximate the behavior of a large number of agents, and the computation of equilibria in MFG has been a subject of interest. Despite the proposal of methods to approximate the equilibria, algorithms where the sequence of updated policy converges to equilibrium, specifically those exhibiting last-iterate convergence, have been limited. We propose the use of a simple, proximal-point-type algorithm to compute equilibria for MFGs. Subsequently, we provide the first last-iterate convergence guarantee under the Lasry--Lions-type monotonicity condition. We further employ the Mirror Descent algorithm for the regularized MFG to efficiently approximate the update rules of the proximal point method for MFGs. We demonstrate that the algorithm can approximate with an accuracy of $\varepsilon$ after $\mathcal{O}({\log(1/\varepsilon)})$ iterations. This research offers a tractable approach for large-scale and large-population games.
Filtered Direct Preference Optimization
Apr 23, 2024



Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
Regularized Best-of-N Sampling to Mitigate Reward Hacking for Language Model Alignment
Apr 05, 2024



Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) to human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Because the reward model is an imperfect proxy for the true objective, over-optimizing its value can compromise its performance on the true objective. A common solution to prevent reward hacking in preference learning techniques is to optimize a reward using proximity regularization (e.g., KL regularization), which ensures that the language model remains close to the reference model. In this research, we propose Regularized Best-of-N (RBoN), a variant of BoN that aims to mitigate reward hacking by incorporating a proximity term in response selection, similar to preference learning techniques. We evaluate two variants of RBoN on the AlpacaFarm dataset and find that they outperform BoN, especially when the proxy reward model has a low correlation with the true objective.
Scalable and Provably Fair Exposure Control for Large-Scale Recommender Systems
Feb 22, 2024



Typical recommendation and ranking methods aim to optimize the satisfaction of users, but they are often oblivious to their impact on the items (e.g., products, jobs, news, video) and their providers. However, there has been a growing understanding that the latter is crucial to consider for a wide range of applications, since it determines the utility of those being recommended. Prior approaches to fairness-aware recommendation optimize a regularized objective to balance user satisfaction and item fairness based on some notion such as exposure fairness. These existing methods have been shown to be effective in controlling fairness, however, most of them are computationally inefficient, limiting their applications to only unrealistically small-scale situations. This indeed implies that the literature does not yet provide a solution to enable a flexible control of exposure in the industry-scale recommender systems where millions of users and items exist. To enable a computationally efficient exposure control even for such large-scale systems, this work develops a scalable, fast, and fair method called \emph{\textbf{ex}posure-aware \textbf{ADMM} (\textbf{exADMM})}. exADMM is based on implicit alternating least squares (iALS), a conventional scalable algorithm for collaborative filtering, but optimizes a regularized objective to achieve a flexible control of accuracy-fairness tradeoff. A particular technical challenge in developing exADMM is the fact that the fairness regularizer destroys the separability of optimization subproblems for users and items, which is an essential property to ensure the scalability of iALS. Therefore, we develop a set of optimization tools to enable yet scalable fairness control with provable convergence guarantees as a basis of our algorithm.