 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Perturbation under Sampling in Solving Extensive-Form Games
Paper and Code
Jan 28, 2025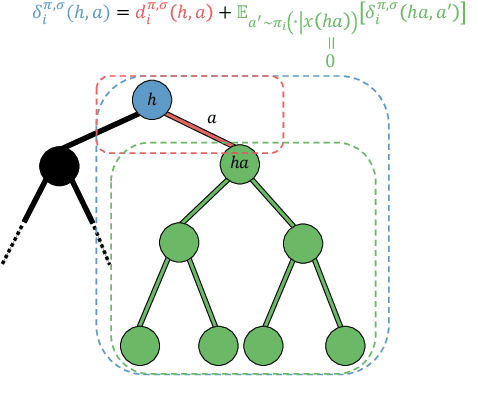
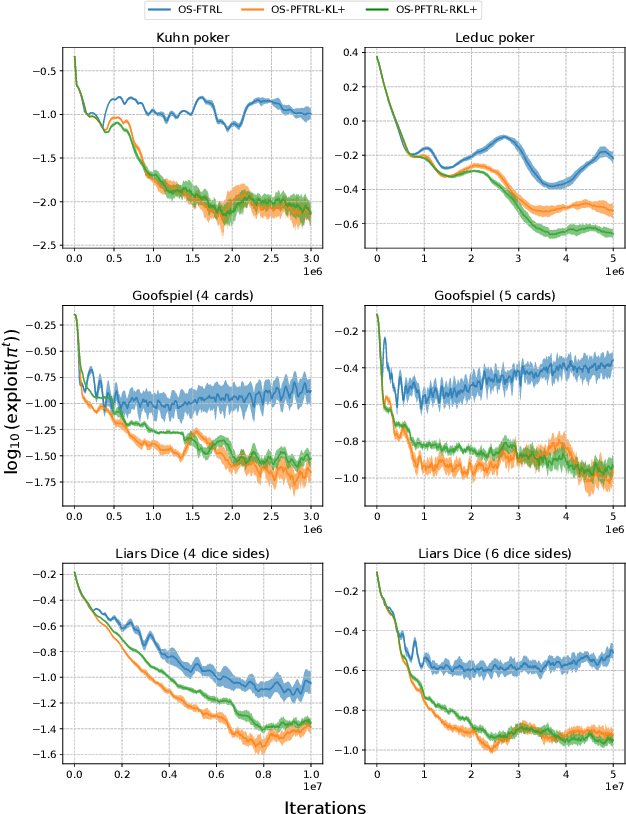
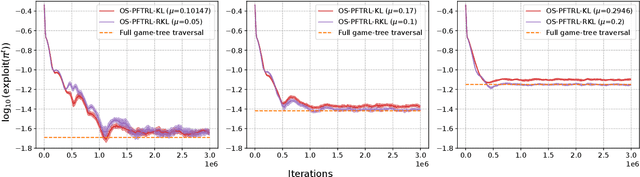
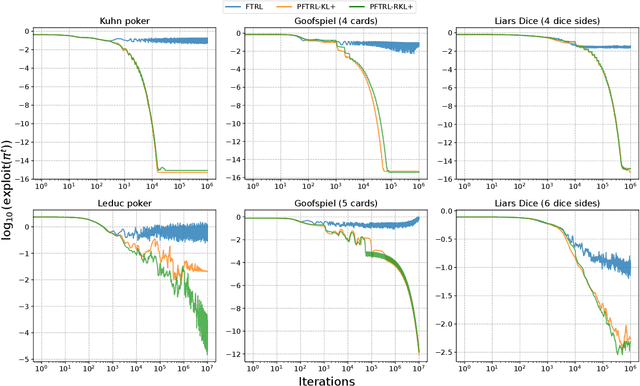
This paper investigates how perturbation does and does not improve the Follow-the-Regularized-Leader (FTRL) algorithm in imperfect-information extensive-form games. Perturbing the expected payoffs guarantees that the FTRL dynamics reach an approximate equilibrium, and proper adjustments of the magnitude of the perturbation lead to a Nash equilibrium (\textit{last-iterate convergence}). This approach is robust even when payoffs are estimated using sampling -- as is the case for large games -- while the optimistic approach often becomes unstable. Building upon those insights, we first develop a general framework for perturbed FTRL algorithms under \textit{sampling}. We then empirically show that in the last-iterate sense, the perturbed FTRL consistently outperforms the non-perturbed FTRL. We further identify a divergence function that reduces the variance of the estimates for perturbed payoffs, with which it significantly outperforms the prior algorithms on Leduc poker (whose structure is more asymmetric in a sense than that of the other benchmark games) and consistently performs smooth convergence behavior on all the benchmark games.