 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReturn-Aligned Decision Transformer
Paper and Code
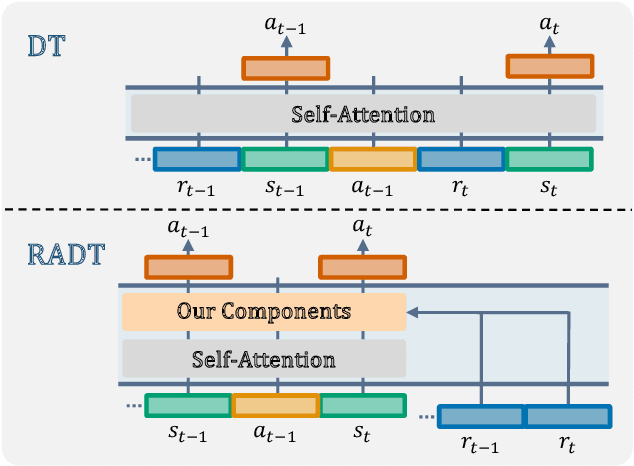
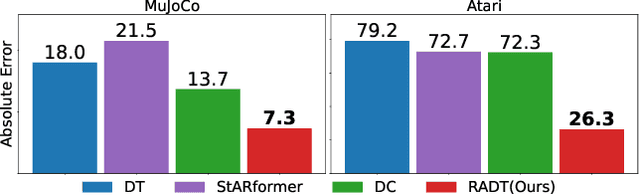
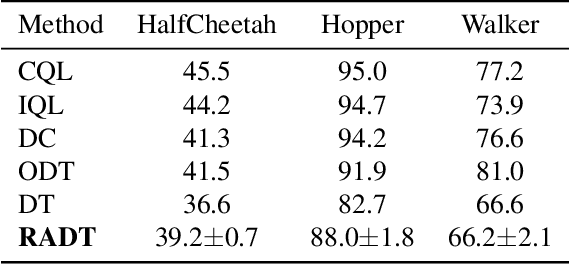
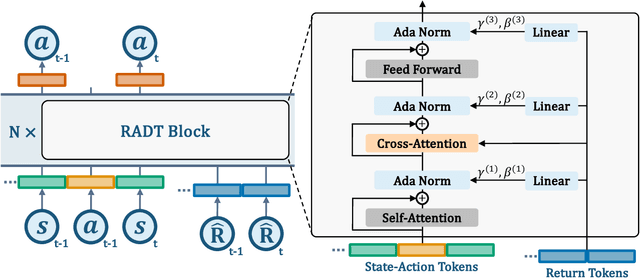
Traditional approaches in offline reinforcement learning aim to learn the optimal policy that maximizes the cumulative reward, also known as return. However, as applications broaden, it becomes increasingly crucial to train agents that not only maximize the returns, but align the actual return with a specified target return, giving control over the agent's performance. Decision Transformer (DT) optimizes a policy that generates actions conditioned on the target return through supervised learning and is equipped with a mechanism to control the agent using the target return. Despite being designed to align the actual return with the target return, we have empirically identified a discrepancy between the actual return and the target return in DT. In this paper, we propose Return-Aligned Decision Transformer (RADT), designed to effectively align the actual return with the target return. Our model decouples returns from the conventional input sequence, which typically consists of returns, states, and actions, to enhance the relationships between returns and states, as well as returns and actions. Extensive experiments show that RADT reduces the discrepancies between the actual return and the target return of DT-based methods.