 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammar and Gameplay-aligned RL for Game Description Generation with LLMs
Mar 20, 2025Game Description Generation (GDG) is the task of generating a game description written in a Game Description Language (GDL) from natural language text. Previous studies have explored generation methods leveraging the contextual understanding capabilities of Large Language Models (LLMs); however, accurately reproducing the game features of the game descriptions remains a challenge. In this paper, we propose reinforcement learning-based fine-tuning of LLMs for GDG (RLGDG). Our training method simultaneously improves grammatical correctness and fidelity to game concepts by introducing both grammar rewards and concept rewards. Furthermore, we adopt a two-stage training strategy where Reinforcement Learning (RL) is applied following Supervised Fine-Tuning (SFT). Experimental results demonstrate that our proposed method significantly outperforms baseline methods using SFT alone.
Fashionability-Enhancing Outfit Image Editing with Conditional Diffusion Models
Dec 24, 2024



Image generation in the fashion domain has predominantly focused on preserving body characteristics or following input prompts, but little attention has been paid to improving the inherent fashionability of the output images. This paper presents a novel diffusion model-based approach that generates fashion images with improved fashionability while maintaining control over key attributes. Key components of our method include: 1) fashionability enhancement, which ensures that the generated images are more fashionable than the input; 2) preservation of body characteristics, encouraging the generated images to maintain the original shape and proportions of the input; and 3) automatic fashion optimization, which does not rely on manual input or external prompts. We also employ two methods to collect training data for guidance while generating and evaluating the images. In particular, we rate outfit images using fashionability scores annotated by multiple fashion experts through OpenSkill-based and five critical aspect-based pairwise comparisons. These methods provide complementary perspectives for assessing and improving the fashionability of the generated images. The experimental results show that our approach outperforms the baseline Fashion++ in generating images with superior fashionability, demonstrating its effectiveness in producing more stylish and appealing fashion images.
Multimodal Markup Document Models for Graphic Design Completion
Sep 27, 2024



This paper presents multimodal markup document models (MarkupDM) that can generate both markup language and images within interleaved multimodal documents. Unlike existing vision-and-language multimodal models, our MarkupDM tackles unique challenges critical to graphic design tasks: generating partial images that contribute to the overall appearance, often involving transparency and varying sizes, and understanding the syntax and semantics of markup languages, which play a fundamental role as a representational format of graphic designs. To address these challenges, we design an image quantizer to tokenize images of diverse sizes with transparency and modify a code language model to process markup languages and incorporate image modalities. We provide in-depth evaluations of our approach on three graphic design completion tasks: generating missing attribute values, images, and texts in graphic design templates. Results corroborate the effectiveness of our MarkupDM for graphic design tasks. We also discuss the strengths and weaknesses in detail, providing insights for future research on multimodal document generation.
Grammar-based Game Description Generation using Large Language Models
Jul 24, 2024



To lower the barriers to game design development, automated game design, which generates game designs through computational processes, has been explored. In automated game design, machine learning-based techniques such as evolutionary algorithms have achieved success. Benefiting from the remarkable advancements in deep learning, applications in computer vision and natural language processing have progressed in level generation. However, due to the limited amount of data in game design, the application of deep learning has been insufficient for tasks such as game description generation. To pioneer a new approach for handling limited data in automated game design, we focus on the in-context learning of large language models (LLMs). LLMs can capture the features of a task from a few demonstration examples and apply the capabilities acquired during pre-training. We introduce the grammar of game descriptions, which effectively structures the game design space, into the LLMs' reasoning process. Grammar helps LLMs capture the characteristics of the complex task of game description generation. Furthermore, we propose a decoding method that iteratively improves the generated output by leveraging the grammar. Our experiments demonstrate that this approach performs well in generating game descriptions.
Return-Aligned Decision Transformer
Feb 06, 2024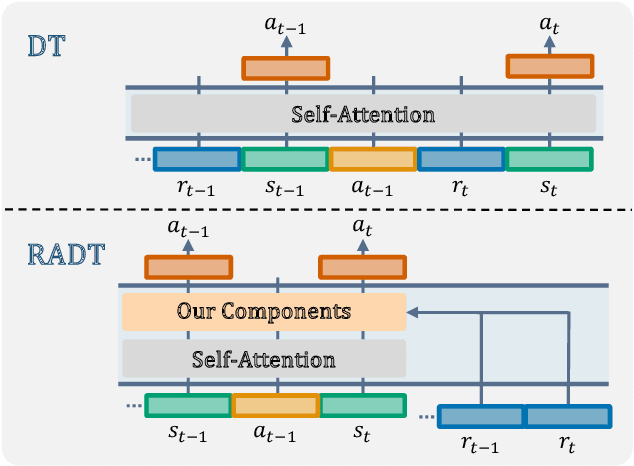
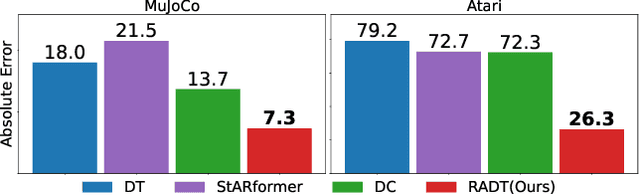
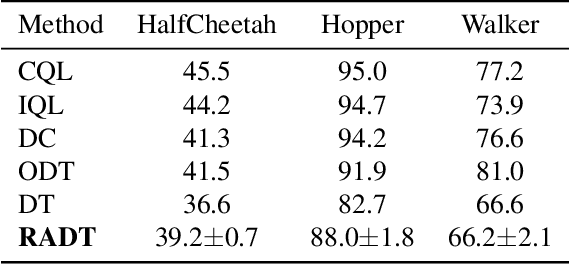
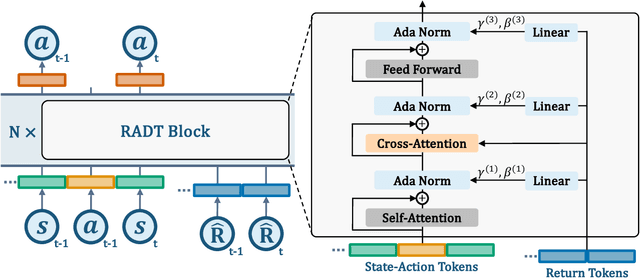
Traditional approaches in offline reinforcement learning aim to learn the optimal policy that maximizes the cumulative reward, also known as return. However, as applications broaden, it becomes increasingly crucial to train agents that not only maximize the returns, but align the actual return with a specified target return, giving control over the agent's performance. Decision Transformer (DT) optimizes a policy that generates actions conditioned on the target return through supervised learning and is equipped with a mechanism to control the agent using the target return. Despite being designed to align the actual return with the target return, we have empirically identified a discrepancy between the actual return and the target return in DT. In this paper, we propose Return-Aligned Decision Transformer (RADT), designed to effectively align the actual return with the target return. Our model decouples returns from the conventional input sequence, which typically consists of returns, states, and actions, to enhance the relationships between returns and states, as well as returns and actions. Extensive experiments show that RADT reduces the discrepancies between the actual return and the target return of DT-based methods.
Image Synthesis-based Late Stage Cancer Augmentation and Semi-Supervised Segmentation for MRI Rectal Cancer Staging
Dec 08, 2023Rectal cancer is one of the most common diseases and a major cause of mortality. For deciding rectal cancer treatment plans, T-staging is important. However, evaluating the index from preoperative MRI images requires high radiologists' skill and experience. Therefore, the aim of this study is to segment the mesorectum, rectum, and rectal cancer region so that the system can predict T-stage from segmentation results. Generally, shortage of large and diverse dataset and high quality annotation are known to be the bottlenecks in computer aided diagnostics development. Regarding rectal cancer, advanced cancer images are very rare, and per-pixel annotation requires high radiologists' skill and time. Therefore, it is not feasible to collect comprehensive disease patterns in a training dataset. To tackle this, we propose two kinds of approaches of image synthesis-based late stage cancer augmentation and semi-supervised learning which is designed for T-stage prediction. In the image synthesis data augmentation approach, we generated advanced cancer images from labels. The real cancer labels were deformed to resemble advanced cancer labels by artificial cancer progress simulation. Next, we introduce a T-staging loss which enables us to train segmentation models from per-image T-stage labels. The loss works to keep inclusion/invasion relationships between rectum and cancer region consistent to the ground truth T-stage. The verification tests show that the proposed method obtains the best sensitivity (0.76) and specificity (0.80) in distinguishing between over T3 stage and underT2. In the ablation studies, our semi-supervised learning approach with the T-staging loss improved specificity by 0.13. Adding the image synthesis-based data augmentation improved the DICE score of invasion cancer area by 0.08 from baseline.
Visual Grounding of Whole Radiology Reports for 3D CT Images
Dec 08, 2023Building a large-scale training dataset is an essential problem in the development of medical image recognition systems. Visual grounding techniques, which automatically associate objects in images with corresponding descriptions, can facilitate labeling of large number of images. However, visual grounding of radiology reports for CT images remains challenging, because so many kinds of anomalies are detectable via CT imaging, and resulting report descriptions are long and complex. In this paper, we present the first visual grounding framework designed for CT image and report pairs covering various body parts and diverse anomaly types. Our framework combines two components of 1) anatomical segmentation of images, and 2) report structuring. The anatomical segmentation provides multiple organ masks of given CT images, and helps the grounding model recognize detailed anatomies. The report structuring helps to accurately extract information regarding the presence, location, and type of each anomaly described in corresponding reports. Given the two additional image/report features, the grounding model can achieve better localization. In the verification process, we constructed a large-scale dataset with region-description correspondence annotations for 10,410 studies of 7,321 unique patients. We evaluated our framework using grounding accuracy, the percentage of correctly localized anomalies, as a metric and demonstrated that the combination of the anatomical segmentation and the report structuring improves the performance with a large margin over the baseline model (66.0% vs 77.8%). Comparison with the prior techniques also showed higher performance of our method.
* 14 pages, 7 figures. Accepted at MICCAI 2023
Diffusion-based Holistic Texture Rectification and Synthesis
Sep 26, 2023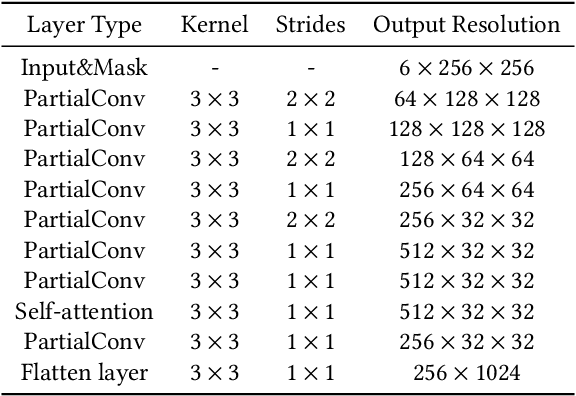
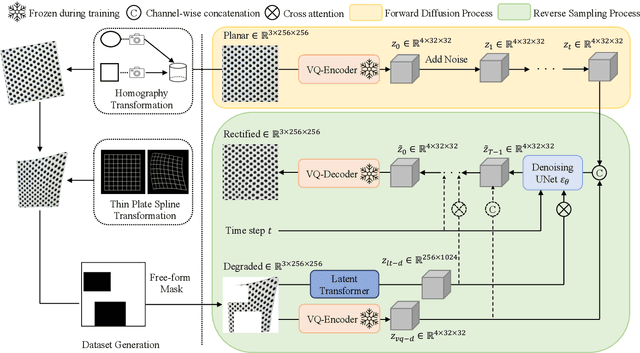
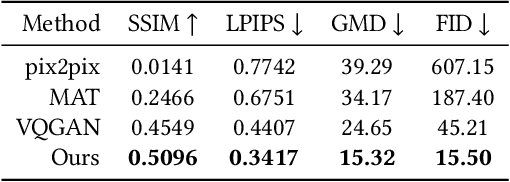

We present a novel framework for rectifying occlusions and distortions in degraded texture samples from natural images. Traditional texture synthesis approaches focus on generating textures from pristine samples, which necessitate meticulous preparation by humans and are often unattainable in most natural images. These challenges stem from the frequent occlusions and distortions of texture samples in natural images due to obstructions and variations in object surface geometry. To address these issues, we propose a framework that synthesizes holistic textures from degraded samples in natural images, extending the applicability of exemplar-based texture synthesis techniques. Our framework utilizes a conditional Latent Diffusion Model (LDM) with a novel occlusion-aware latent transformer. This latent transformer not only effectively encodes texture features from partially-observed samples necessary for the generation process of the LDM, but also explicitly captures long-range dependencies in samples with large occlusions. To train our model, we introduce a method for generating synthetic data by applying geometric transformations and free-form mask generation to clean textures. Experimental results demonstrate that our framework significantly outperforms existing methods both quantitatively and quantitatively. Furthermore, we conduct comprehensive ablation studies to validate the different components of our proposed framework. Results are corroborated by a perceptual user study which highlights the efficiency of our proposed approach.
Controllable Multi-domain Semantic Artwork Synthesis
Aug 19, 2023We present a novel framework for multi-domain synthesis of artwork from semantic layouts. One of the main limitations of this challenging task is the lack of publicly available segmentation datasets for art synthesis. To address this problem, we propose a dataset, which we call ArtSem, that contains 40,000 images of artwork from 4 different domains with their corresponding semantic label maps. We generate the dataset by first extracting semantic maps from landscape photography and then propose a conditional Generative Adversarial Network (GAN)-based approach to generate high-quality artwork from the semantic maps without necessitating paired training data. Furthermore, we propose an artwork synthesis model that uses domain-dependent variational encoders for high-quality multi-domain synthesis. The model is improved and complemented with a simple but effective normalization method, based on normalizing both the semantic and style jointly, which we call Spatially STyle-Adaptive Normalization (SSTAN). In contrast to previous methods that only take semantic layout as input, our model is able to learn a joint representation of both style and semantic information, which leads to better generation quality for synthesizing artistic images. Results indicate that our model learns to separate the domains in the latent space, and thus, by identifying the hyperplanes that separate the different domains, we can also perform fine-grained control of the synthesized artwork. By combining our proposed dataset and approach, we are able to generate user-controllable artwork that is of higher quality than existing
Towards Flexible Multi-modal Document Models
Mar 31, 2023Creative workflows for generating graphical documents involve complex inter-related tasks, such as aligning elements, choosing appropriate fonts, or employing aesthetically harmonious colors. In this work, we attempt at building a holistic model that can jointly solve many different design tasks. Our model, which we denote by FlexDM, treats vector graphic documents as a set of multi-modal elements, and learns to predict masked fields such as element type, position, styling attributes, image, or text, using a unified architecture. Through the use of explicit multi-task learning and in-domain pre-training, our model can better capture the multi-modal relationships among the different document fields. Experimental results corroborate that our single FlexDM is able to successfully solve a multitude of different design tasks, while achieving performance that is competitive with task-specific and costly baselines.