 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiEmo-Bench: Multi-label Visual Emotion Analysis for Multi-modal Large Language Models
May 14, 2026This paper introduces a multi-label visual emotion analysis benchmark dataset for comprehensively evaluating the ability of multimodal large language models (MLLMs) to predict the emotions evoked by images. Recent user studies report an unintuitive finding: humans may prefer the predictions of MLLMs over the labels in existing datasets. We argue that this phenomenon stems from the suboptimal annotation scheme used in existing datasets, where each annotator is shown a single candidate emotion for each image and judges whether it is evoked or not. This approach is clearly limited because a single image can evoke multiple emotions with varying intensities. As a result, evaluations based on these datasets may underestimate the capabilities of MLLMs, yet an appropriate benchmark for evaluating such models remains lacking. To address this issue, we introduce a new multi-label benchmark dataset for visual emotion analysis toward MLLMs evaluation. We hire $20$ annotators per image and ask them to select all emotions they feel from an image. Then, we aggregate the votes across all annotators, providing a more reliable and representative dataset labeled with a distribution of emotions. The resulting dataset contains $10,344$ images with $236,998$ valid votes across eight emotions. Based on this benchmark dataset, we evaluate several recent models, including Qwen3-VL, OpenAI's GPT, Gemini, and Claude. We assess model performance on both dominant emotion prediction and emotion distribution prediction. Our results demonstrate the progress achieved by recent MLLMs while also indicating that substantial room for improvement remains. Furthermore, our experiments with LLM-as-a-judge show that the method does not consistently improve MLLMs' performance, indicating its limitations for the subjective task of visual emotion analysis.
Reference-Free Image Quality Assessment for Virtual Try-On via Human Feedback
Mar 13, 2026Given a person image and a garment image, image-based Virtual Try-ON (VTON) synthesizes a try-on image of the person wearing the target garment. As VTON systems become increasingly important in practical applications such as fashion e-commerce, reliable evaluation of their outputs has emerged as a critical challenge. In real-world scenarios, ground-truth images of the same person wearing the target garment are typically unavailable, making reference-based evaluation impractical. Moreover, widely used distribution-level metrics such as Fréchet Inception Distance and Kernel Inception Distance measure dataset-level similarity and fail to reflect the perceptual quality of individual generated images. To address these limitations, we propose Image Quality Assessment for Virtual Try-On (VTON-IQA), a reference-free framework for human-aligned, image-level quality assessment without requiring ground-truth images. To model human perceptual judgments, we construct VTON-QBench, a large-scale human-annotated benchmark comprising 62,688 try-on images generated by 14 representative VTON models and 431,800 quality annotations collected from 13,838 qualified annotators. To the best of our knowledge, this is the largest dataset to date for human subjective evaluation in virtual try-on. Evaluating virtual try-on quality requires verifying both garment fidelity and the preservation of person-specific details. To explicitly model such interactions, we introduce an Interleaved Cross-Attention module that extends standard transformer blocks by inserting a cross-attention layer between self-attention and MLP in the latter blocks. Extensive experiments show that VTON-IQA achieves reliable human-aligned image-level quality prediction. Moreover, we conduct a comprehensive benchmark evaluation of 14 representative VTON models using VTON-IQA.
Static Word Embeddings for Sentence Semantic Representation
Jun 05, 2025

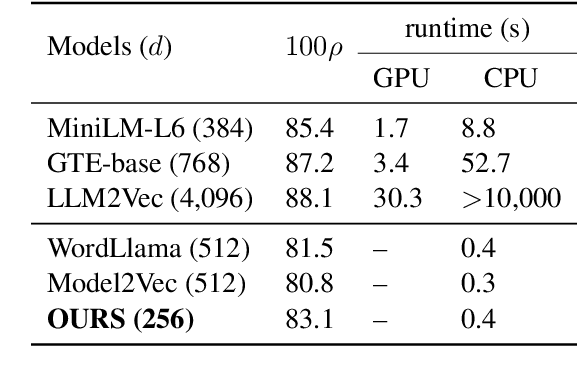

We propose new static word embeddings optimised for sentence semantic representation. We first extract word embeddings from a pre-trained Sentence Transformer, and improve them with sentence-level principal component analysis, followed by either knowledge distillation or contrastive learning. During inference, we represent sentences by simply averaging word embeddings, which requires little computational cost. We evaluate models on both monolingual and cross-lingual tasks and show that our model substantially outperforms existing static models on sentence semantic tasks, and even rivals a basic Sentence Transformer model (SimCSE) on some data sets. Lastly, we perform a variety of analyses and show that our method successfully removes word embedding components that are irrelevant to sentence semantics, and adjusts the vector norms based on the influence of words on sentence semantics.
Masked Language Prompting for Generative Data Augmentation in Few-shot Fashion Style Recognition
Apr 28, 2025Constructing dataset for fashion style recognition is challenging due to the inherent subjectivity and ambiguity of style concepts. Recent advances in text-to-image models have facilitated generative data augmentation by synthesizing images from labeled data, yet existing methods based solely on class names or reference captions often fail to balance visual diversity and style consistency. In this work, we propose \textbf{Masked Language Prompting (MLP)}, a novel prompting strategy that masks selected words in a reference caption and leverages large language models to generate diverse yet semantically coherent completions. This approach preserves the structural semantics of the original caption while introducing attribute-level variations aligned with the intended style, enabling style-consistent and diverse image generation without fine-tuning. Experimental results on the FashionStyle14 dataset demonstrate that our MLP-based augmentation consistently outperforms class-name and caption-based baselines, validating its effectiveness for fashion style recognition under limited supervision.
Fashionability-Enhancing Outfit Image Editing with Conditional Diffusion Models
Dec 24, 2024



Image generation in the fashion domain has predominantly focused on preserving body characteristics or following input prompts, but little attention has been paid to improving the inherent fashionability of the output images. This paper presents a novel diffusion model-based approach that generates fashion images with improved fashionability while maintaining control over key attributes. Key components of our method include: 1) fashionability enhancement, which ensures that the generated images are more fashionable than the input; 2) preservation of body characteristics, encouraging the generated images to maintain the original shape and proportions of the input; and 3) automatic fashion optimization, which does not rely on manual input or external prompts. We also employ two methods to collect training data for guidance while generating and evaluating the images. In particular, we rate outfit images using fashionability scores annotated by multiple fashion experts through OpenSkill-based and five critical aspect-based pairwise comparisons. These methods provide complementary perspectives for assessing and improving the fashionability of the generated images. The experimental results show that our approach outperforms the baseline Fashion++ in generating images with superior fashionability, demonstrating its effectiveness in producing more stylish and appealing fashion images.
An Empirical Analysis of GPT-4V's Performance on Fashion Aesthetic Evaluation
Oct 31, 2024



Fashion aesthetic evaluation is the task of estimating how well the outfits worn by individuals in images suit them. In this work, we examine the zero-shot performance of GPT-4V on this task for the first time. We show that its predictions align fairly well with human judgments on our datasets, and also find that it struggles with ranking outfits in similar colors. The code is available at https://github.com/st-tech/gpt4v-fashion-aesthetic-evaluation.
A Fashion Item Recommendation Model in Hyperbolic Space
Sep 04, 2024In this work, we propose a fashion item recommendation model that incorporates hyperbolic geometry into user and item representations. Using hyperbolic space, our model aims to capture implicit hierarchies among items based on their visual data and users' purchase history. During training, we apply a multi-task learning framework that considers both hyperbolic and Euclidean distances in the loss function. Our experiments on three data sets show that our model performs better than previous models trained in Euclidean space only, confirming the effectiveness of our model. Our ablation studies show that multi-task learning plays a key role, and removing the Euclidean loss substantially deteriorates the model performance.
On permutation-invariant neural networks
Mar 28, 2024



Conventional machine learning algorithms have traditionally been designed under the assumption that input data follows a vector-based format, with an emphasis on vector-centric paradigms. However, as the demand for tasks involving set-based inputs has grown, there has been a paradigm shift in the research community towards addressing these challenges. In recent years, the emergence of neural network architectures such as Deep Sets and Transformers has presented a significant advancement in the treatment of set-based data. These architectures are specifically engineered to naturally accommodate sets as input, enabling more effective representation and processing of set structures. Consequently, there has been a surge of research endeavors dedicated to exploring and harnessing the capabilities of these architectures for various tasks involving the approximation of set functions. This comprehensive survey aims to provide an overview of the diverse problem settings and ongoing research efforts pertaining to neural networks that approximate set functions. By delving into the intricacies of these approaches and elucidating the associated challenges, the survey aims to equip readers with a comprehensive understanding of the field. Through this comprehensive perspective, we hope that researchers can gain valuable insights into the potential applications, inherent limitations, and future directions of set-based neural networks. Indeed, from this survey we gain two insights: i) Deep Sets and its variants can be generalized by differences in the aggregation function, and ii) the behavior of Deep Sets is sensitive to the choice of the aggregation function. From these observations, we show that Deep Sets, one of the well-known permutation-invariant neural networks, can be generalized in the sense of a quasi-arithmetic mean.