 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiEmo-Bench: Multi-label Visual Emotion Analysis for Multi-modal Large Language Models
May 14, 2026This paper introduces a multi-label visual emotion analysis benchmark dataset for comprehensively evaluating the ability of multimodal large language models (MLLMs) to predict the emotions evoked by images. Recent user studies report an unintuitive finding: humans may prefer the predictions of MLLMs over the labels in existing datasets. We argue that this phenomenon stems from the suboptimal annotation scheme used in existing datasets, where each annotator is shown a single candidate emotion for each image and judges whether it is evoked or not. This approach is clearly limited because a single image can evoke multiple emotions with varying intensities. As a result, evaluations based on these datasets may underestimate the capabilities of MLLMs, yet an appropriate benchmark for evaluating such models remains lacking. To address this issue, we introduce a new multi-label benchmark dataset for visual emotion analysis toward MLLMs evaluation. We hire $20$ annotators per image and ask them to select all emotions they feel from an image. Then, we aggregate the votes across all annotators, providing a more reliable and representative dataset labeled with a distribution of emotions. The resulting dataset contains $10,344$ images with $236,998$ valid votes across eight emotions. Based on this benchmark dataset, we evaluate several recent models, including Qwen3-VL, OpenAI's GPT, Gemini, and Claude. We assess model performance on both dominant emotion prediction and emotion distribution prediction. Our results demonstrate the progress achieved by recent MLLMs while also indicating that substantial room for improvement remains. Furthermore, our experiments with LLM-as-a-judge show that the method does not consistently improve MLLMs' performance, indicating its limitations for the subjective task of visual emotion analysis.
Reference-Free Image Quality Assessment for Virtual Try-On via Human Feedback
Mar 13, 2026Given a person image and a garment image, image-based Virtual Try-ON (VTON) synthesizes a try-on image of the person wearing the target garment. As VTON systems become increasingly important in practical applications such as fashion e-commerce, reliable evaluation of their outputs has emerged as a critical challenge. In real-world scenarios, ground-truth images of the same person wearing the target garment are typically unavailable, making reference-based evaluation impractical. Moreover, widely used distribution-level metrics such as Fréchet Inception Distance and Kernel Inception Distance measure dataset-level similarity and fail to reflect the perceptual quality of individual generated images. To address these limitations, we propose Image Quality Assessment for Virtual Try-On (VTON-IQA), a reference-free framework for human-aligned, image-level quality assessment without requiring ground-truth images. To model human perceptual judgments, we construct VTON-QBench, a large-scale human-annotated benchmark comprising 62,688 try-on images generated by 14 representative VTON models and 431,800 quality annotations collected from 13,838 qualified annotators. To the best of our knowledge, this is the largest dataset to date for human subjective evaluation in virtual try-on. Evaluating virtual try-on quality requires verifying both garment fidelity and the preservation of person-specific details. To explicitly model such interactions, we introduce an Interleaved Cross-Attention module that extends standard transformer blocks by inserting a cross-attention layer between self-attention and MLP in the latter blocks. Extensive experiments show that VTON-IQA achieves reliable human-aligned image-level quality prediction. Moreover, we conduct a comprehensive benchmark evaluation of 14 representative VTON models using VTON-IQA.
Static Word Embeddings for Sentence Semantic Representation
Jun 05, 2025

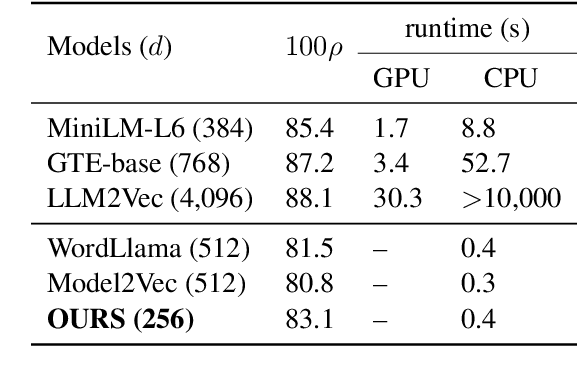

We propose new static word embeddings optimised for sentence semantic representation. We first extract word embeddings from a pre-trained Sentence Transformer, and improve them with sentence-level principal component analysis, followed by either knowledge distillation or contrastive learning. During inference, we represent sentences by simply averaging word embeddings, which requires little computational cost. We evaluate models on both monolingual and cross-lingual tasks and show that our model substantially outperforms existing static models on sentence semantic tasks, and even rivals a basic Sentence Transformer model (SimCSE) on some data sets. Lastly, we perform a variety of analyses and show that our method successfully removes word embedding components that are irrelevant to sentence semantics, and adjusts the vector norms based on the influence of words on sentence semantics.
On Fairness of Task Arithmetic: The Role of Task Vectors
May 30, 2025Model editing techniques, particularly task arithmetic using task vectors, have shown promise in efficiently modifying pre-trained models through arithmetic operations like task addition and negation. Despite computational advantages, these methods may inadvertently affect model fairness, creating risks in sensitive applications like hate speech detection. However, the fairness implications of task arithmetic remain largely unexplored, presenting a critical gap in the existing literature. We systematically examine how manipulating task vectors affects fairness metrics, including Demographic Parity and Equalized Odds. To rigorously assess these effects, we benchmark task arithmetic against full fine-tuning, a costly but widely used baseline, and Low-Rank Adaptation (LoRA), a prevalent parameter-efficient fine-tuning method. Additionally, we explore merging task vectors from models fine-tuned on demographic subgroups vulnerable to hate speech, investigating whether fairness outcomes can be controlled by adjusting task vector coefficients, potentially enabling tailored model behavior. Our results offer novel insights into the fairness implications of model editing and establish a foundation for fairness-aware and responsible model editing practices.
Masked Language Prompting for Generative Data Augmentation in Few-shot Fashion Style Recognition
Apr 28, 2025Constructing dataset for fashion style recognition is challenging due to the inherent subjectivity and ambiguity of style concepts. Recent advances in text-to-image models have facilitated generative data augmentation by synthesizing images from labeled data, yet existing methods based solely on class names or reference captions often fail to balance visual diversity and style consistency. In this work, we propose \textbf{Masked Language Prompting (MLP)}, a novel prompting strategy that masks selected words in a reference caption and leverages large language models to generate diverse yet semantically coherent completions. This approach preserves the structural semantics of the original caption while introducing attribute-level variations aligned with the intended style, enabling style-consistent and diverse image generation without fine-tuning. Experimental results on the FashionStyle14 dataset demonstrate that our MLP-based augmentation consistently outperforms class-name and caption-based baselines, validating its effectiveness for fashion style recognition under limited supervision.
Attributed Synthetic Data Generation for Zero-shot Domain-specific Image Classification
Apr 06, 2025Zero-shot domain-specific image classification is challenging in classifying real images without ground-truth in-domain training examples. Recent research involved knowledge from texts with a text-to-image model to generate in-domain training images in zero-shot scenarios. However, existing methods heavily rely on simple prompt strategies, limiting the diversity of synthetic training images, thus leading to inferior performance compared to real images. In this paper, we propose AttrSyn, which leverages large language models to generate attributed prompts. These prompts allow for the generation of more diverse attributed synthetic images. Experiments for zero-shot domain-specific image classification on two fine-grained datasets show that training with synthetic images generated by AttrSyn significantly outperforms CLIP's zero-shot classification under most situations and consistently surpasses simple prompt strategies.
Discovering Knowledge Deficiencies of Language Models on Massive Knowledge Base
Mar 30, 2025Large language models (LLMs) possess impressive linguistic capabilities but often fail to faithfully retain factual knowledge, leading to hallucinations and unreliable outputs. Understanding LLMs' knowledge deficiencies by exhaustively evaluating against full-scale knowledge bases is computationally prohibitive, especially for closed-weight models. We propose stochastic error ascent (SEA), a scalable and efficient framework for discovering knowledge deficiencies (errors) in closed-weight LLMs under a strict query budget. Rather than naively probing all knowledge candidates, SEA formulates error discovery as a stochastic optimization process: it iteratively retrieves new high-error candidates by leveraging the semantic similarity to previously observed failures. To further enhance search efficiency and coverage, SEA employs hierarchical retrieval across document and paragraph levels, and constructs a relation directed acyclic graph to model error propagation and identify systematic failure modes. Empirically, SEA uncovers 40.7x more knowledge errors than Automated Capability Discovery and 26.7% more than AutoBencher, while reducing the cost-per-error by 599x and 9x, respectively. Human evaluation confirms the high quality of generated questions, while ablation and convergence analyses validate the contribution of each component in SEA. Further analysis on the discovered errors reveals correlated failure patterns across LLM families and recurring deficits, highlighting the need for better data coverage and targeted fine-tuning in future LLM development.
Vision and Language Reference Prompt into SAM for Few-shot Segmentation
Feb 02, 2025Segment Anything Model (SAM) represents a large-scale segmentation model that enables powerful zero-shot capabilities with flexible prompts. While SAM can segment any object in zero-shot, it requires user-provided prompts for each target image and does not attach any label information to masks. Few-shot segmentation models addressed these issues by inputting annotated reference images as prompts to SAM and can segment specific objects in target images without user-provided prompts. Previous SAM-based few-shot segmentation models only use annotated reference images as prompts, resulting in limited accuracy due to a lack of reference information. In this paper, we propose a novel few-shot segmentation model, Vision and Language reference Prompt into SAM (VLP-SAM), that utilizes the visual information of the reference images and the semantic information of the text labels by inputting not only images but also language as reference information. In particular, VLP-SAM is a simple and scalable structure with minimal learnable parameters, which inputs prompt embeddings with vision-language information into SAM using a multimodal vision-language model. To demonstrate the effectiveness of VLP-SAM, we conducted experiments on the PASCAL-5i and COCO-20i datasets, and achieved high performance in the few-shot segmentation task, outperforming the previous state-of-the-art model by a large margin (6.3% and 9.5% in mIoU, respectively). Furthermore, VLP-SAM demonstrates its generality in unseen objects that are not included in the training data. Our code is available at https://github.com/kosukesakurai1/VLP-SAM.
Fashionability-Enhancing Outfit Image Editing with Conditional Diffusion Models
Dec 24, 2024



Image generation in the fashion domain has predominantly focused on preserving body characteristics or following input prompts, but little attention has been paid to improving the inherent fashionability of the output images. This paper presents a novel diffusion model-based approach that generates fashion images with improved fashionability while maintaining control over key attributes. Key components of our method include: 1) fashionability enhancement, which ensures that the generated images are more fashionable than the input; 2) preservation of body characteristics, encouraging the generated images to maintain the original shape and proportions of the input; and 3) automatic fashion optimization, which does not rely on manual input or external prompts. We also employ two methods to collect training data for guidance while generating and evaluating the images. In particular, we rate outfit images using fashionability scores annotated by multiple fashion experts through OpenSkill-based and five critical aspect-based pairwise comparisons. These methods provide complementary perspectives for assessing and improving the fashionability of the generated images. The experimental results show that our approach outperforms the baseline Fashion++ in generating images with superior fashionability, demonstrating its effectiveness in producing more stylish and appealing fashion images.
Template Matters: Understanding the Role of Instruction Templates in Multimodal Language Model Evaluation and Training
Dec 11, 2024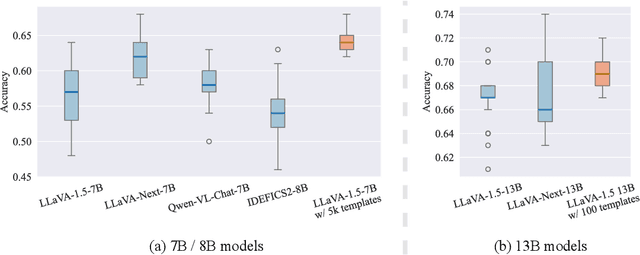
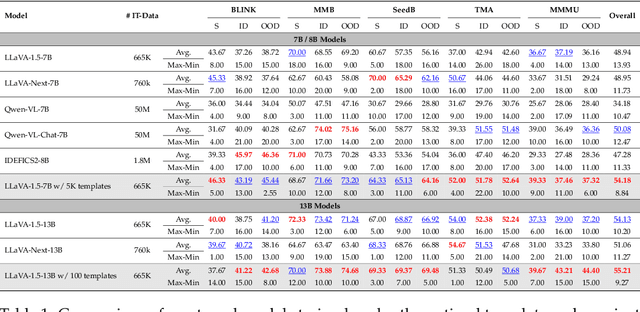

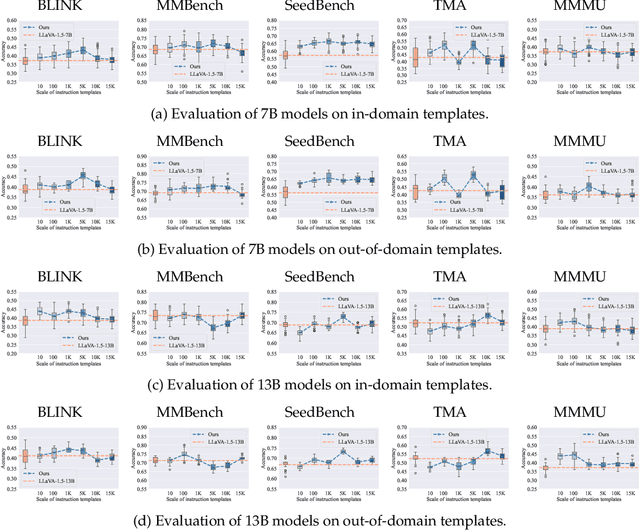
Current multimodal language models (MLMs) evaluation and training approaches overlook the influence of instruction format, presenting an elephant-in-the-room problem. Previous research deals with this problem by manually crafting instructions, failing to yield significant insights due to limitations in diversity and scalability. In this work, we propose a programmatic instruction template generator capable of producing over 39B unique template combinations by filling randomly sampled positional synonyms into weighted sampled meta templates, enabling us to comprehensively examine the MLM's performance across diverse instruction templates. Our experiments across eight common MLMs on five benchmark datasets reveal that MLMs have high template sensitivities with at most 29% performance gaps between different templates. We further augment the instruction tuning dataset of LLaVA-1.5 with our template generator and perform instruction tuning on LLaVA-1.5-7B and LLaVA-1.5-13B. Models tuned on our augmented dataset achieve the best overall performance when compared with the same scale MLMs tuned on at most 75 times the scale of our augmented dataset, highlighting the importance of instruction templates in MLM training. The code is available at https://github.com/shijian2001/TemplateMatters .