 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Synthetic Data Generation for Zero-shot Domain-specific Image Classification
Apr 06, 2025Zero-shot domain-specific image classification is challenging in classifying real images without ground-truth in-domain training examples. Recent research involved knowledge from texts with a text-to-image model to generate in-domain training images in zero-shot scenarios. However, existing methods heavily rely on simple prompt strategies, limiting the diversity of synthetic training images, thus leading to inferior performance compared to real images. In this paper, we propose AttrSyn, which leverages large language models to generate attributed prompts. These prompts allow for the generation of more diverse attributed synthetic images. Experiments for zero-shot domain-specific image classification on two fine-grained datasets show that training with synthetic images generated by AttrSyn significantly outperforms CLIP's zero-shot classification under most situations and consistently surpasses simple prompt strategies.
Vision and Language Reference Prompt into SAM for Few-shot Segmentation
Feb 02, 2025Segment Anything Model (SAM) represents a large-scale segmentation model that enables powerful zero-shot capabilities with flexible prompts. While SAM can segment any object in zero-shot, it requires user-provided prompts for each target image and does not attach any label information to masks. Few-shot segmentation models addressed these issues by inputting annotated reference images as prompts to SAM and can segment specific objects in target images without user-provided prompts. Previous SAM-based few-shot segmentation models only use annotated reference images as prompts, resulting in limited accuracy due to a lack of reference information. In this paper, we propose a novel few-shot segmentation model, Vision and Language reference Prompt into SAM (VLP-SAM), that utilizes the visual information of the reference images and the semantic information of the text labels by inputting not only images but also language as reference information. In particular, VLP-SAM is a simple and scalable structure with minimal learnable parameters, which inputs prompt embeddings with vision-language information into SAM using a multimodal vision-language model. To demonstrate the effectiveness of VLP-SAM, we conducted experiments on the PASCAL-5i and COCO-20i datasets, and achieved high performance in the few-shot segmentation task, outperforming the previous state-of-the-art model by a large margin (6.3% and 9.5% in mIoU, respectively). Furthermore, VLP-SAM demonstrates its generality in unseen objects that are not included in the training data. Our code is available at https://github.com/kosukesakurai1/VLP-SAM.
Disentangling Likes and Dislikes in Personalized Generative Explainable Recommendation
Oct 17, 2024



Recent research on explainable recommendation generally frames the task as a standard text generation problem, and evaluates models simply based on the textual similarity between the predicted and ground-truth explanations. However, this approach fails to consider one crucial aspect of the systems: whether their outputs accurately reflect the users' (post-purchase) sentiments, i.e., whether and why they would like and/or dislike the recommended items. To shed light on this issue, we introduce new datasets and evaluation methods that focus on the users' sentiments. Specifically, we construct the datasets by explicitly extracting users' positive and negative opinions from their post-purchase reviews using an LLM, and propose to evaluate systems based on whether the generated explanations 1) align well with the users' sentiments, and 2) accurately identify both positive and negative opinions of users on the target items. We benchmark several recent models on our datasets and demonstrate that achieving strong performance on existing metrics does not ensure that the generated explanations align well with the users' sentiments. Lastly, we find that existing models can provide more sentiment-aware explanations when the users' (predicted) ratings for the target items are directly fed into the models as input. We will release our code and datasets upon acceptance.
SCP: Spherical-Coordinate-based Learned Point Cloud Compression
Aug 24, 2023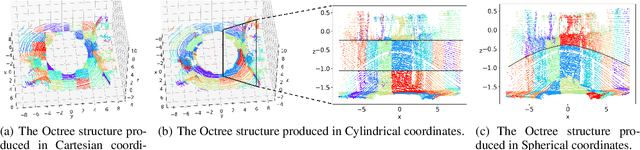
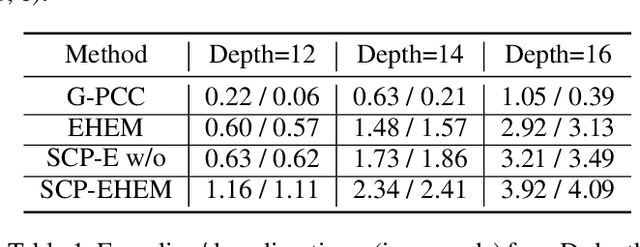
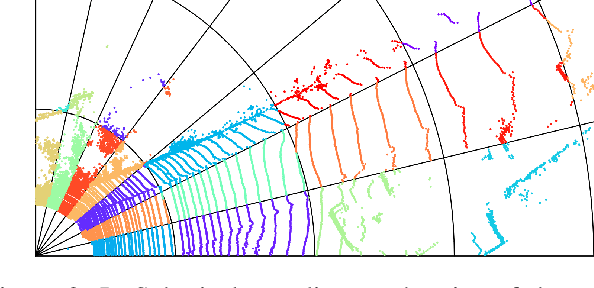
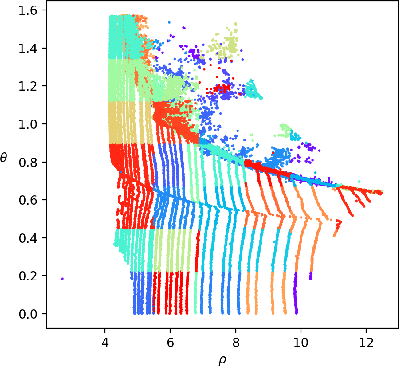
In recent years, the task of learned point cloud compression has gained prominence. An important type of point cloud, the spinning LiDAR point cloud, is generated by spinning LiDAR on vehicles. This process results in numerous circular shapes and azimuthal angle invariance features within the point clouds. However, these two features have been largely overlooked by previous methodologies. In this paper, we introduce a model-agnostic method called Spherical-Coordinate-based learned Point cloud compression (SCP), designed to leverage the aforementioned features fully. Additionally, we propose a multi-level Octree for SCP to mitigate the reconstruction error for distant areas within the Spherical-coordinate-based Octree. SCP exhibits excellent universality, making it applicable to various learned point cloud compression techniques. Experimental results demonstrate that SCP surpasses previous state-of-the-art methods by up to 29.14% in point-to-point PSNR BD-Rate.
Partial Visual-Semantic Embedding: Fashion Intelligence System with Sensitive Part-by-Part Learning
Nov 12, 2022



In this study, we propose a technology called the Fashion Intelligence System based on the visual-semantic embedding (VSE) model to quantify abstract and complex expressions unique to fashion, such as ''casual,'' ''adult-casual,'' and ''office-casual,'' and to support users' understanding of fashion. However, the existing VSE model does not support the situations in which the image is composed of multiple parts such as hair, tops, pants, skirts, and shoes. We propose partial VSE, which enables sensitive learning for each part of the fashion coordinates. The proposed model partially learns embedded representations. This helps retain the various existing practical functionalities and enables image-retrieval tasks in which changes are made only to the specified parts and image reordering tasks that focus on the specified parts. This was not possible with conventional models. Based on both the qualitative and quantitative evaluation experiments, we show that the proposed model is superior to conventional models without increasing the computational complexity.
Fashion-Specific Attributes Interpretation via Dual Gaussian Visual-Semantic Embedding
Nov 07, 2022Several techniques to map various types of components, such as words, attributes, and images, into the embedded space have been studied. Most of them estimate the embedded representation of target entity as a point in the projective space. Some models, such as Word2Gauss, assume a probability distribution behind the embedded representation, which enables the spread or variance of the meaning of embedded target components to be captured and considered in more detail. We examine the method of estimating embedded representations as probability distributions for the interpretation of fashion-specific abstract and difficult-to-understand terms. Terms, such as "casual," "adult-casual,'' "beauty-casual," and "formal," are extremely subjective and abstract and are difficult for both experts and non-experts to understand, which discourages users from trying new fashion. We propose an end-to-end model called dual Gaussian visual-semantic embedding, which maps images and attributes in the same projective space and enables the interpretation of the meaning of these terms by its broad applications. We demonstrate the effectiveness of the proposed method through multifaceted experiments involving image and attribute mapping, image retrieval and re-ordering techniques, and a detailed theoretical/analytical discussion of the distance measure included in the loss function.
Adaptive Ranking-based Sample Selection for Weakly Supervised Class-imbalanced Text Classification
Oct 07, 2022
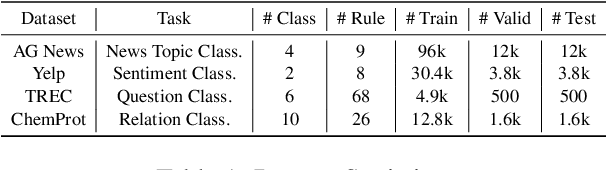
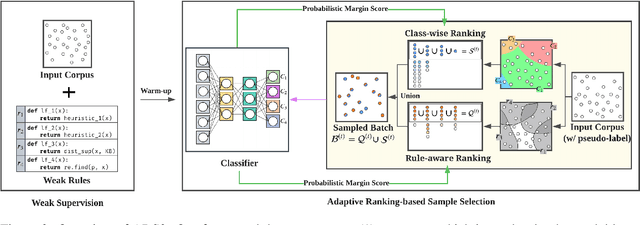
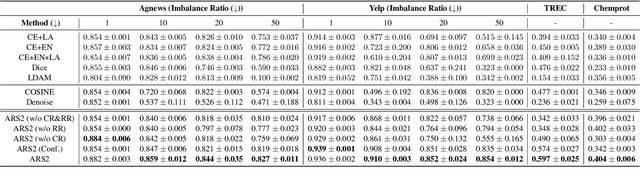
To obtain a large amount of training labels inexpensively, researchers have recently adopted the weak supervision (WS) paradigm, which leverages labeling rules to synthesize training labels rather than using individual annotations to achieve competitive results for natural language processing (NLP) tasks. However, data imbalance is often overlooked in applying the WS paradigm, despite being a common issue in a variety of NLP tasks. To address this challenge, we propose Adaptive Ranking-based Sample Selection (ARS2), a model-agnostic framework to alleviate the data imbalance issue in the WS paradigm. Specifically, it calculates a probabilistic margin score based on the output of the current model to measure and rank the cleanliness of each data point. Then, the ranked data are sampled based on both class-wise and rule-aware ranking. In particular, the two sample strategies corresponds to our motivations: (1) to train the model with balanced data batches to reduce the data imbalance issue and (2) to exploit the expertise of each labeling rule for collecting clean samples. Experiments on four text classification datasets with four different imbalance ratios show that ARS2 outperformed the state-of-the-art imbalanced learning and WS methods, leading to a 2%-57.8% improvement on their F1-score.