 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunable X-band opto-electronic synthesizer with ultralow phase noise
Mar 29, 2024Modern communication, navigation, and radar systems rely on low noise and frequency-agile microwave sources. In this application space, photonic systems provide an attractive alternative to conventional microwave synthesis by leveraging high spectral purity lasers and optical frequency combs to generate microwaves with exceedingly low phase noise. However, these photonic techniques suffer from a lack of frequency tunability, and also have substantial size, weight, and power requirements that largely limit their use to laboratory settings. In this work, we address these shortcomings with a hybrid opto-electronic approach that combines simplified optical frequency division with direct digital synthesis to produce tunable low-phase-noise microwaves across the entire X-band. This results in exceptional phase noise at 10 GHz of -156 dBc/Hz at 10 kHz offset and fractional frequency instability of 1x10^-13 at 0.1 s. Spot tuning away from 10 GHz by 500 MHz, 1 GHz, and 2 GHz, yields phase noise at 10 kHz offset of -150 dBc/Hz, -146 dBc/Hz, and -140 dBc/Hz, respectively. The synthesizer architecture is fully compatible with integrated photonic implementations that will enable a versatile microwave source in a chip-scale package. Together, these advances illustrate an impactful and practical synthesis technique that shares the combined benefits of low timing noise provided by photonics and the frequency agility of established digital synthesis.
Outfit Completion via Conditional Set Transformation
Nov 28, 2023



In this paper, we formulate the outfit completion problem as a set retrieval task and propose a novel framework for solving this problem. The proposal includes a conditional set transformation architecture with deep neural networks and a compatibility-based regularization method. The proposed method utilizes a map with permutation-invariant for the input set and permutation-equivariant for the condition set. This allows retrieving a set that is compatible with the input set while reflecting the properties of the condition set. In addition, since this structure outputs the element of the output set in a single inference, it can achieve a scalable inference speed with respect to the cardinality of the output set. Experimental results on real data reveal that the proposed method outperforms existing approaches in terms of accuracy of the outfit completion task, condition satisfaction, and compatibility of completion results.
Partial Visual-Semantic Embedding: Fashion Intelligence System with Sensitive Part-by-Part Learning
Nov 12, 2022



In this study, we propose a technology called the Fashion Intelligence System based on the visual-semantic embedding (VSE) model to quantify abstract and complex expressions unique to fashion, such as ''casual,'' ''adult-casual,'' and ''office-casual,'' and to support users' understanding of fashion. However, the existing VSE model does not support the situations in which the image is composed of multiple parts such as hair, tops, pants, skirts, and shoes. We propose partial VSE, which enables sensitive learning for each part of the fashion coordinates. The proposed model partially learns embedded representations. This helps retain the various existing practical functionalities and enables image-retrieval tasks in which changes are made only to the specified parts and image reordering tasks that focus on the specified parts. This was not possible with conventional models. Based on both the qualitative and quantitative evaluation experiments, we show that the proposed model is superior to conventional models without increasing the computational complexity.
SHIFT15M: Multiobjective Large-Scale Fashion Dataset with Distributional Shifts
Aug 30, 2021



Many machine learning algorithms assume that the training data and the test data follow the same distribution. However, such assumptions are often violated in real-world machine learning problems. In this paper, we propose SHIFT15M, a dataset that can be used to properly evaluate models in situations where the distribution of data changes between training and testing. The SHIFT15M dataset has several good properties: (i) Multiobjective. Each instance in the dataset has several numerical values that can be used as target variables. (ii) Large-scale. The SHIFT15M dataset consists of 15million fashion images. (iii) Coverage of types of dataset shifts. SHIFT15M contains multiple dataset shift problem settings (e.g., covariate shift or target shift). SHIFT15M also enables the performance evaluation of the model under various magnitudes of dataset shifts by switching the magnitude. In addition, we provide software to handle SHIFT15M in a very simple way: https://github.com/st-tech/zozo-shift15m.
Deep Set-to-Set Matching and Learning
Oct 22, 2019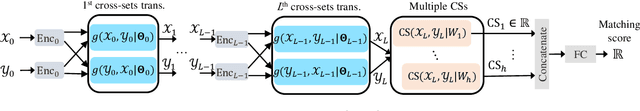
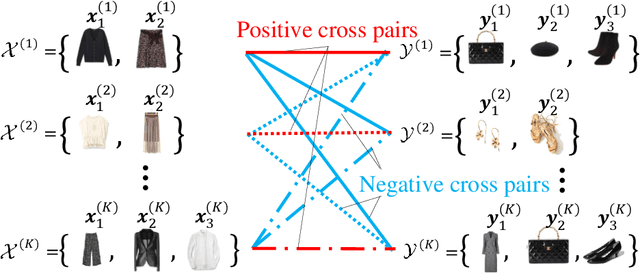

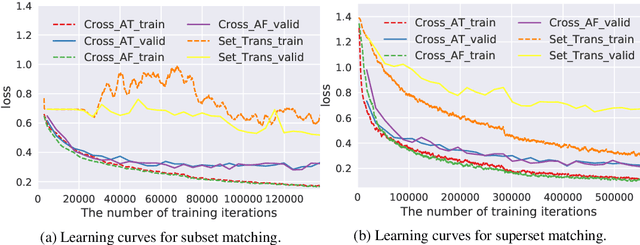
Matching two sets of items, called set-to-set matching problem, is being recently raised. The difficulties of set-to-set matching over ordinary data matching lie in the exchangeability in 1) set-feature extraction and 2) set-matching score; the pair of sets and the items in each set should be exchangeable. In this paper, we propose a deep learning architecture for the set-to-set matching that overcomes the above difficulties, including two novel modules: 1) a cross-set transformation and 2) cross-similarity function. The former provides the exchangeable set-feature through interactions between two sets in intermediate layers, and the latter provides the exchangeable set matching through calculating the cross-feature similarity of items between two sets. We evaluate the methods through experiments with two industrial applications, fashion set recommendation, and group re-identification. Through these experiments, we show that the proposed methods perform better than a baseline given by an extension of the Set Transformer, the state-of-the-art set-input function.
Outfit Generation and Style Extraction via Bidirectional LSTM and Autoencoder
Oct 23, 2018
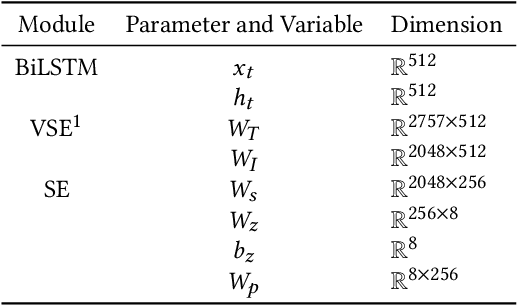
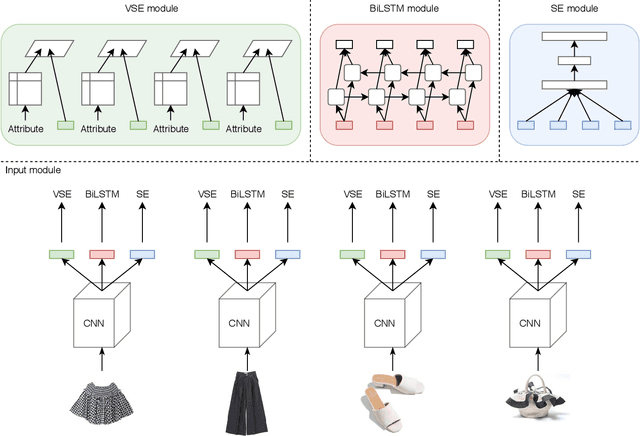
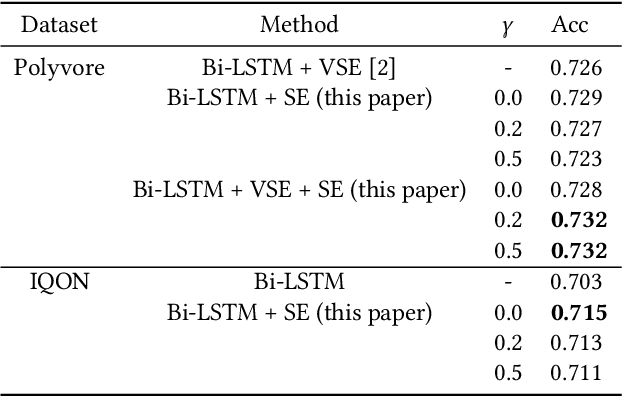
When creating an outfit, style is a criterion in selecting each fashion item. This means that style can be regarded as a feature of the overall outfit. However, in various previous studies on outfit generation, there have been few methods focusing on global information obtained from an outfit. To address this deficiency, we have incorporated an unsupervised style extraction module into a model to learn outfits. Using the style information of an outfit as a whole, the proposed model succeeded in generating outfits more flexibly without requiring additional information. Moreover, the style information extracted by the proposed model is easy to interpret. The proposed model was evaluated on two human-generated outfit datasets. In a fashion item prediction task (missing prediction task), the proposed model outperformed a baseline method. In a style extraction task, the proposed model extracted some easily distinguishable styles. In an outfit generation task, the proposed model generated an outfit while controlling its styles. This capability allows us to generate fashionable outfits according to various preferences.