 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Between Waves, wave2wave
Jul 20, 2020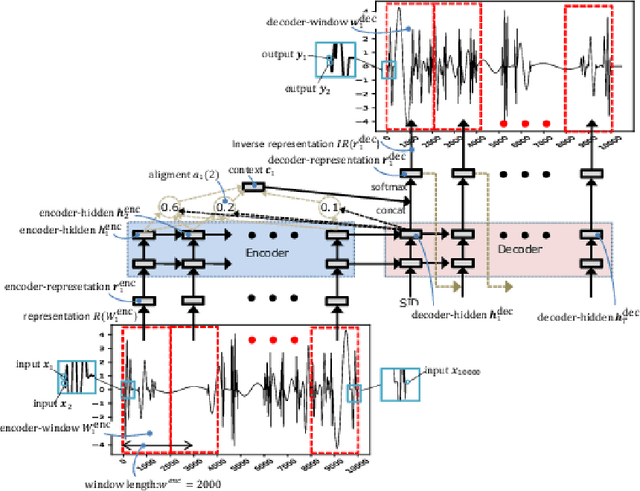
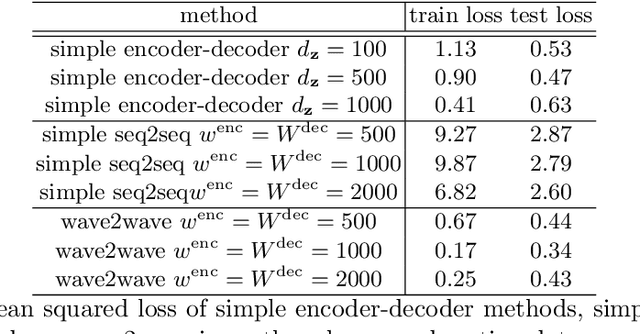
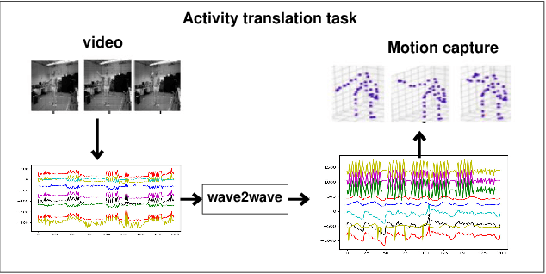
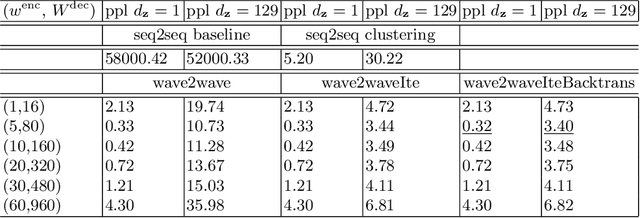
The understanding of sensor data has been greatly improved by advanced deep learning methods with big data. However, available sensor data in the real world are still limited, which is called the opportunistic sensor problem. This paper proposes a new variant of neural machine translation seq2seq to deal with continuous signal waves by introducing the window-based (inverse-) representation to adaptively represent partial shapes of waves and the iterative back-translation model for high-dimensional data. Experimental results are shown for two real-life data: earthquake and activity translation. The performance improvements of one-dimensional data was about 46% in test loss and that of high-dimensional data was about 1625% in perplexity with regard to the original seq2seq.
Deep Set-to-Set Matching and Learning
Oct 22, 2019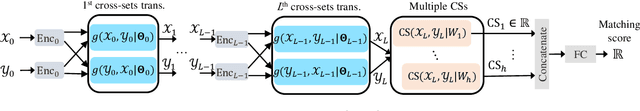
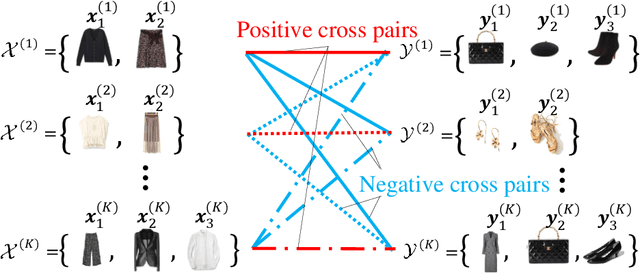

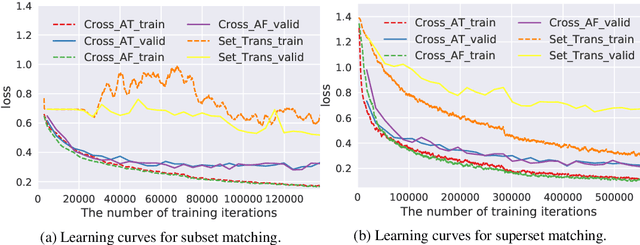
Matching two sets of items, called set-to-set matching problem, is being recently raised. The difficulties of set-to-set matching over ordinary data matching lie in the exchangeability in 1) set-feature extraction and 2) set-matching score; the pair of sets and the items in each set should be exchangeable. In this paper, we propose a deep learning architecture for the set-to-set matching that overcomes the above difficulties, including two novel modules: 1) a cross-set transformation and 2) cross-similarity function. The former provides the exchangeable set-feature through interactions between two sets in intermediate layers, and the latter provides the exchangeable set matching through calculating the cross-feature similarity of items between two sets. We evaluate the methods through experiments with two industrial applications, fashion set recommendation, and group re-identification. Through these experiments, we show that the proposed methods perform better than a baseline given by an extension of the Set Transformer, the state-of-the-art set-input function.
Efficient Sample Reuse in Policy Gradients with Parameter-based Exploration
Jan 17, 2013The policy gradient approach is a flexible and powerful reinforcement learning method particularly for problems with continuous actions such as robot control. A common challenge in this scenario is how to reduce the variance of policy gradient estimates for reliable policy updates. In this paper, we combine the following three ideas and give a highly effective policy gradient method: (a) the policy gradients with parameter based exploration, which is a recently proposed policy search method with low variance of gradient estimates, (b) an importance sampling technique, which allows us to reuse previously gathered data in a consistent way, and (c) an optimal baseline, which minimizes the variance of gradient estimates with their unbiasedness being maintained. For the proposed method, we give theoretical analysis of the variance of gradient estimates and show its usefulness through extensive experiments.
Feature Selection via L1-Penalized Squared-Loss Mutual Information
Oct 06, 2012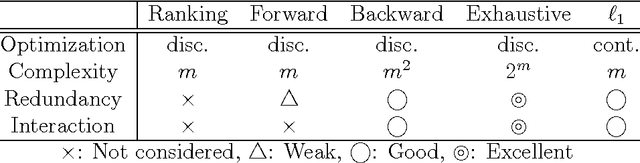
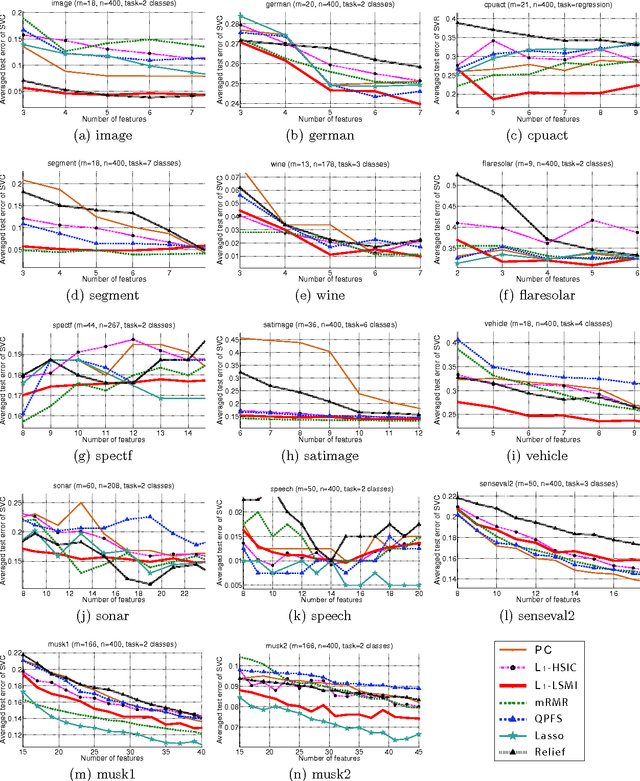
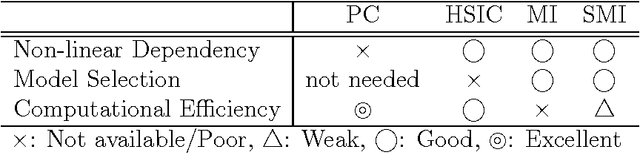
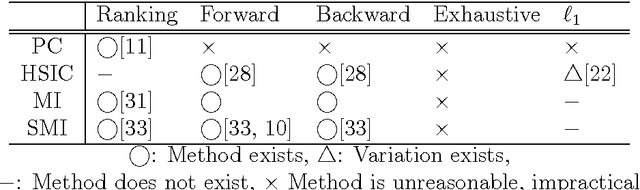
Feature selection is a technique to screen out less important features. Many existing supervised feature selection algorithms use redundancy and relevancy as the main criteria to select features. However, feature interaction, potentially a key characteristic in real-world problems, has not received much attention. As an attempt to take feature interaction into account, we propose L1-LSMI, an L1-regularization based algorithm that maximizes a squared-loss variant of mutual information between selected features and outputs. Numerical results show that L1-LSMI performs well in handling redundancy, detecting non-linear dependency, and considering feature interaction.
Artist Agent: A Reinforcement Learning Approach to Automatic Stroke Generation in Oriental Ink Painting
Jun 18, 2012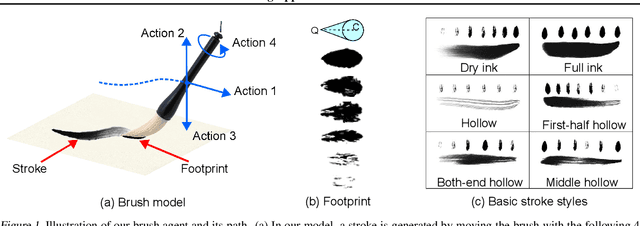

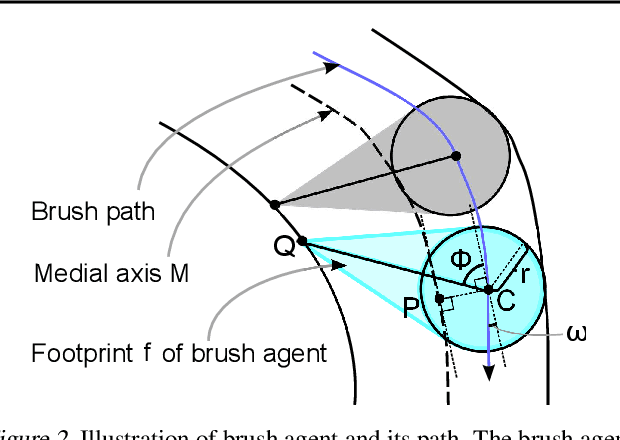
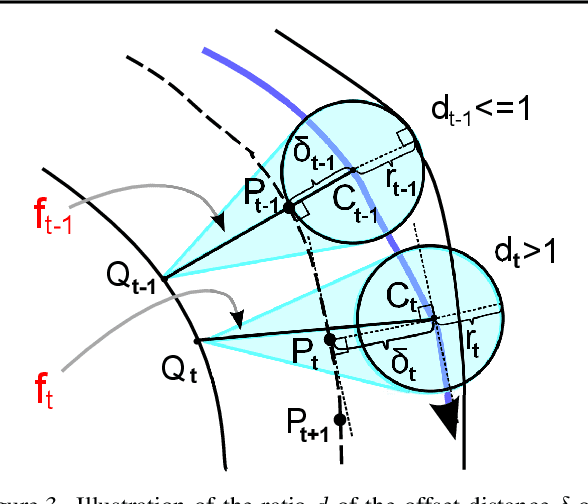
Oriental ink painting, called Sumi-e, is one of the most appealing painting styles that has attracted artists around the world. Major challenges in computer-based Sumi-e simulation are to abstract complex scene information and draw smooth and natural brush strokes. To automatically find such strokes, we propose to model the brush as a reinforcement learning agent, and learn desired brush-trajectories by maximizing the sum of rewards in the policy search framework. We also provide elaborate design of actions, states, and rewards tailored for a Sumi-e agent. The effectiveness of our proposed approach is demonstrated through simulated Sumi-e experiments.
Parametric Return Density Estimation for Reinforcement Learning
Mar 15, 2012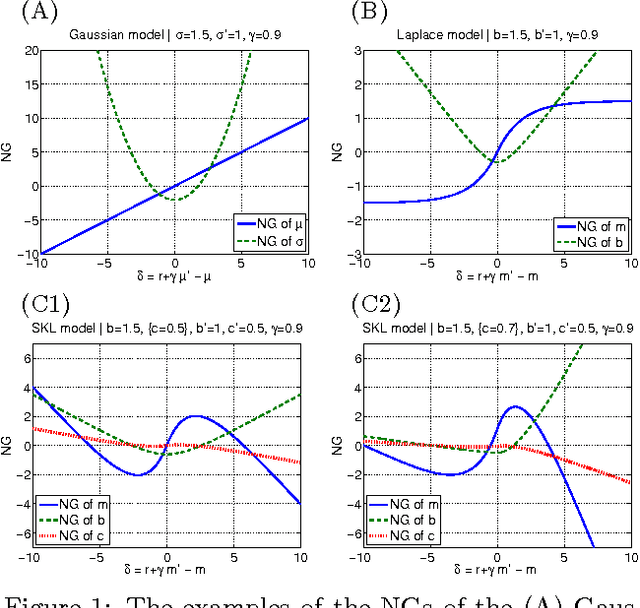
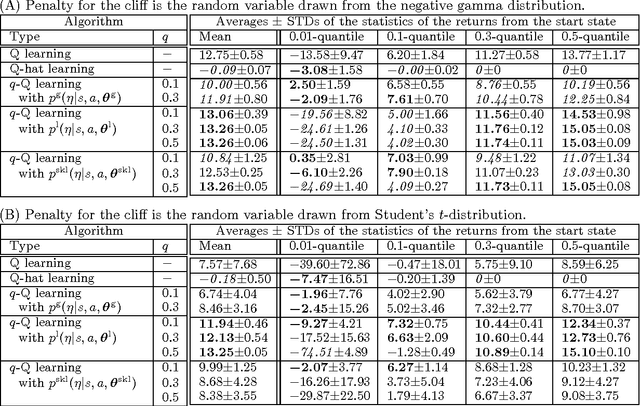
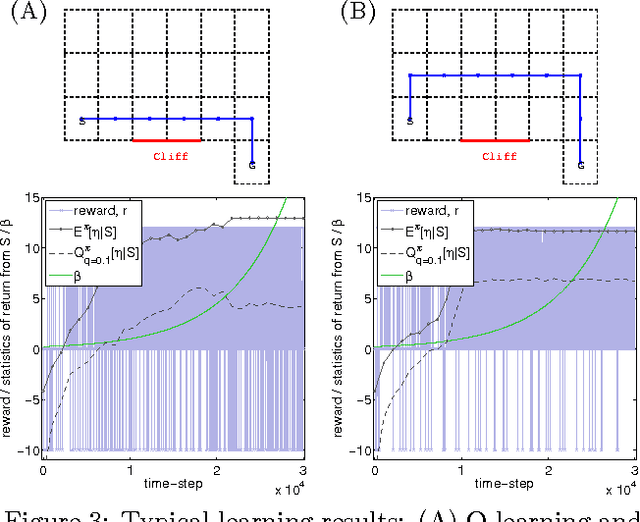
Most conventional Reinforcement Learning (RL) algorithms aim to optimize decision-making rules in terms of the expected returns. However, especially for risk management purposes, other risk-sensitive criteria such as the value-at-risk or the expected shortfall are sometimes preferred in real applications. Here, we describe a parametric method for estimating density of the returns, which allows us to handle various criteria in a unified manner. We first extend the Bellman equation for the conditional expected return to cover a conditional probability density of the returns. Then we derive an extension of the TD-learning algorithm for estimating the return densities in an unknown environment. As test instances, several parametric density estimation algorithms are presented for the Gaussian, Laplace, and skewed Laplace distributions. We show that these algorithms lead to risk-sensitive as well as robust RL paradigms through numerical experiments.
Information-Maximization Clustering based on Squared-Loss Mutual Information
Dec 03, 2011Information-maximization clustering learns a probabilistic classifier in an unsupervised manner so that mutual information between feature vectors and cluster assignments is maximized. A notable advantage of this approach is that it only involves continuous optimization of model parameters, which is substantially easier to solve than discrete optimization of cluster assignments. However, existing methods still involve non-convex optimization problems, and therefore finding a good local optimal solution is not straightforward in practice. In this paper, we propose an alternative information-maximization clustering method based on a squared-loss variant of mutual information. This novel approach gives a clustering solution analytically in a computationally efficient way via kernel eigenvalue decomposition. Furthermore, we provide a practical model selection procedure that allows us to objectively optimize tuning parameters included in the kernel function. Through experiments, we demonstrate the usefulness of the proposed approach.
Relative Density-Ratio Estimation for Robust Distribution Comparison
Jun 23, 2011Divergence estimators based on direct approximation of density-ratios without going through separate approximation of numerator and denominator densities have been successfully applied to machine learning tasks that involve distribution comparison such as outlier detection, transfer learning, and two-sample homogeneity test. However, since density-ratio functions often possess high fluctuation, divergence estimation is still a challenging task in practice. In this paper, we propose to use relative divergences for distribution comparison, which involves approximation of relative density-ratios. Since relative density-ratios are always smoother than corresponding ordinary density-ratios, our proposed method is favorable in terms of the non-parametric convergence speed. Furthermore, we show that the proposed divergence estimator has asymptotic variance independent of the model complexity under a parametric setup, implying that the proposed estimator hardly overfits even with complex models. Through experiments, we demonstrate the usefulness of the proposed approach.