 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Aware Routing for Efficient Text-To-Image Generation
Jun 17, 2025



Diffusion models are well known for their ability to generate a high-fidelity image for an input prompt through an iterative denoising process. Unfortunately, the high fidelity also comes at a high computational cost due the inherently sequential generative process. In this work, we seek to optimally balance quality and computational cost, and propose a framework to allow the amount of computation to vary for each prompt, depending on its complexity. Each prompt is automatically routed to the most appropriate text-to-image generation function, which may correspond to a distinct number of denoising steps of a diffusion model, or a disparate, independent text-to-image model. Unlike uniform cost reduction techniques (e.g., distillation, model quantization), our approach achieves the optimal trade-off by learning to reserve expensive choices (e.g., 100+ denoising steps) only for a few complex prompts, and employ more economical choices (e.g., small distilled model) for less sophisticated prompts. We empirically demonstrate on COCO and DiffusionDB that by learning to route to nine already-trained text-to-image models, our approach is able to deliver an average quality that is higher than that achievable by any of these models alone.
Bipartite Ranking From Multiple Labels: On Loss Versus Label Aggregation
Apr 15, 2025
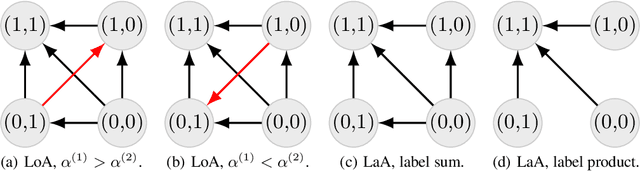


Bipartite ranking is a fundamental supervised learning problem, with the goal of learning a ranking over instances with maximal area under the ROC curve (AUC) against a single binary target label. However, one may often observe multiple binary target labels, e.g., from distinct human annotators. How can one synthesize such labels into a single coherent ranking? In this work, we formally analyze two approaches to this problem -- loss aggregation and label aggregation -- by characterizing their Bayes-optimal solutions. Based on this, we show that while both methods can yield Pareto-optimal solutions, loss aggregation can exhibit label dictatorship: one can inadvertently (and undesirably) favor one label over others. This suggests that label aggregation can be preferable to loss aggregation, which we empirically verify.
I Know What I Don't Know: Improving Model Cascades Through Confidence Tuning
Feb 26, 2025Large-scale machine learning models deliver strong performance across a wide range of tasks but come with significant computational and resource constraints. To mitigate these challenges, local smaller models are often deployed alongside larger models, relying on routing and deferral mechanisms to offload complex tasks. However, existing approaches inadequately balance the capabilities of these models, often resulting in unnecessary deferrals or sub-optimal resource usage. In this work we introduce a novel loss function called Gatekeeper for calibrating smaller models in cascade setups. Our approach fine-tunes the smaller model to confidently handle tasks it can perform correctly while deferring complex tasks to the larger model. Moreover, it incorporates a mechanism for managing the trade-off between model performance and deferral accuracy, and is broadly applicable across various tasks and domains without any architectural changes. We evaluate our method on encoder-only, decoder-only, and encoder-decoder architectures. Experiments across image classification, language modeling, and vision-language tasks show that our approach substantially improves deferral performance.
Universal Model Routing for Efficient LLM Inference
Feb 12, 2025



Large language models' significant advances in capabilities are accompanied by significant increases in inference costs. Model routing is a simple technique for reducing inference cost, wherein one maintains a pool of candidate LLMs, and learns to route each prompt to the smallest feasible LLM. Existing works focus on learning a router for a fixed pool of LLMs. In this paper, we consider the problem of dynamic routing, where new, previously unobserved LLMs are available at test time. We propose a new approach to this problem that relies on representing each LLM as a feature vector, derived based on predictions on a set of representative prompts. Based on this, we detail two effective strategies, relying on cluster-based routing and a learned cluster map respectively. We prove that these strategies are estimates of a theoretically optimal routing rule, and provide an excess risk bound to quantify their errors. Experiments on a range of public benchmarks show the effectiveness of the proposed strategies in routing amongst more than 30 unseen LLMs.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
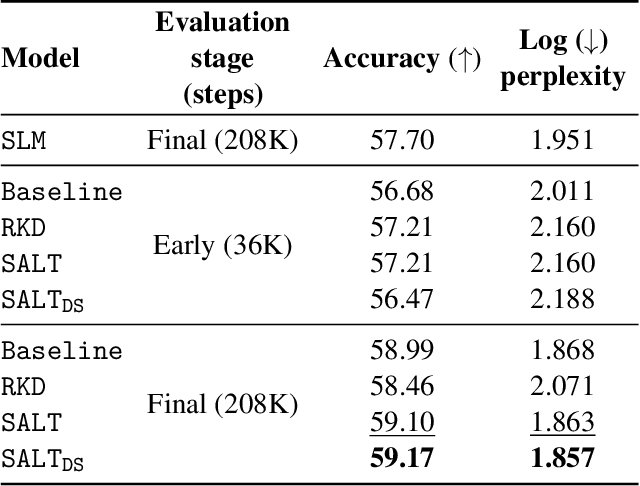

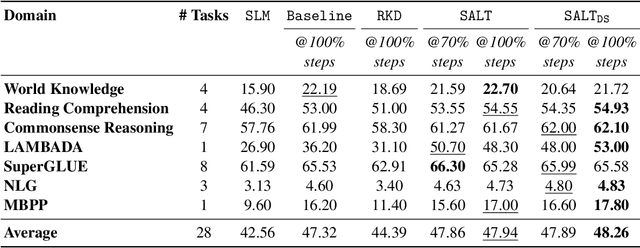
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
Cascade-Aware Training of Language Models
May 29, 2024



Reducing serving cost and latency is a fundamental concern for the deployment of language models (LMs) in business applications. To address this, cascades of LMs offer an effective solution that conditionally employ smaller models for simpler queries. Cascaded systems are typically built with independently trained models, neglecting the advantages of considering inference-time interactions of the cascaded LMs during training. In this paper, we present cascade-aware training(CAT), an approach to optimizing the overall quality-cost performance tradeoff of a cascade of LMs. We achieve inference-time benefits by training the small LM with awareness of its place in a cascade and downstream capabilities. We demonstrate the value of the proposed method with over 60 LM tasks of the SuperGLUE, WMT22, and FLAN2021 datasets.
Faster Cascades via Speculative Decoding
May 29, 2024

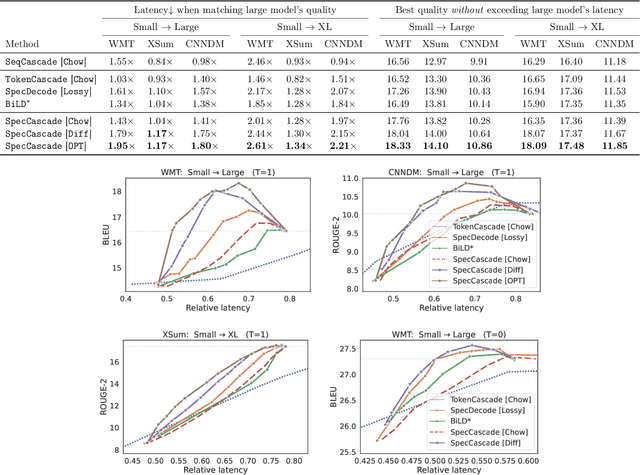

Cascades and speculative decoding are two common approaches to improving language models' inference efficiency. Both approaches involve interleaving models of different sizes, but via fundamentally distinct mechanisms: cascades employ a deferral rule that invokes the larger model only for "hard" inputs, while speculative decoding uses speculative execution to primarily invoke the larger model in parallel verification mode. These mechanisms offer different benefits: empirically, cascades are often capable of yielding better quality than even the larger model, while theoretically, speculative decoding offers a guarantee of quality-neutrality. In this paper, we leverage the best of both these approaches by designing new speculative cascading techniques that implement their deferral rule through speculative execution. We characterize the optimal deferral rule for our speculative cascades, and employ a plug-in approximation to the optimal rule. Through experiments with T5 models on benchmark language tasks, we show that the proposed approach yields better cost-quality trade-offs than cascading and speculative decoding baselines.
Language Model Cascades: Token-level uncertainty and beyond
Apr 15, 2024Recent advances in language models (LMs) have led to significant improvements in quality on complex NLP tasks, but at the expense of increased inference costs. Cascading offers a simple strategy to achieve more favorable cost-quality tradeoffs: here, a small model is invoked for most "easy" instances, while a few "hard" instances are deferred to the large model. While the principles underpinning cascading are well-studied for classification tasks - with deferral based on predicted class uncertainty favored theoretically and practically - a similar understanding is lacking for generative LM tasks. In this work, we initiate a systematic study of deferral rules for LM cascades. We begin by examining the natural extension of predicted class uncertainty to generative LM tasks, namely, the predicted sequence uncertainty. We show that this measure suffers from the length bias problem, either over- or under-emphasizing outputs based on their lengths. This is because LMs produce a sequence of uncertainty values, one for each output token; and moreover, the number of output tokens is variable across examples. To mitigate this issue, we propose to exploit the richer token-level uncertainty information implicit in generative LMs. We argue that naive predicted sequence uncertainty corresponds to a simple aggregation of these uncertainties. By contrast, we show that incorporating token-level uncertainty through learned post-hoc deferral rules can significantly outperform such simple aggregation strategies, via experiments on a range of natural language benchmarks with FLAN-T5 models. We further show that incorporating embeddings from the smaller model and intermediate layers of the larger model can give an additional boost in the overall cost-quality tradeoff.
It's an Alignment, Not a Trade-off: Revisiting Bias and Variance in Deep Models
Oct 13, 2023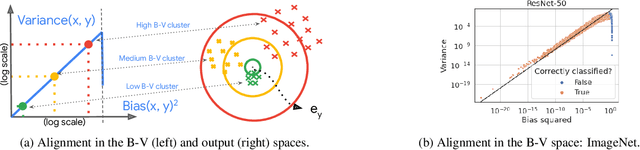

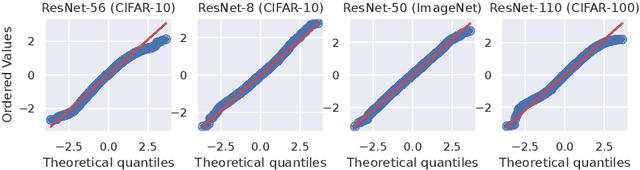
Classical wisdom in machine learning holds that the generalization error can be decomposed into bias and variance, and these two terms exhibit a \emph{trade-off}. However, in this paper, we show that for an ensemble of deep learning based classification models, bias and variance are \emph{aligned} at a sample level, where squared bias is approximately \emph{equal} to variance for correctly classified sample points. We present empirical evidence confirming this phenomenon in a variety of deep learning models and datasets. Moreover, we study this phenomenon from two theoretical perspectives: calibration and neural collapse. We first show theoretically that under the assumption that the models are well calibrated, we can observe the bias-variance alignment. Second, starting from the picture provided by the neural collapse theory, we show an approximate correlation between bias and variance.
When Does Confidence-Based Cascade Deferral Suffice?
Jul 06, 2023



Cascades are a classical strategy to enable inference cost to vary adaptively across samples, wherein a sequence of classifiers are invoked in turn. A deferral rule determines whether to invoke the next classifier in the sequence, or to terminate prediction. One simple deferral rule employs the confidence of the current classifier, e.g., based on the maximum predicted softmax probability. Despite being oblivious to the structure of the cascade -- e.g., not modelling the errors of downstream models -- such confidence-based deferral often works remarkably well in practice. In this paper, we seek to better understand the conditions under which confidence-based deferral may fail, and when alternate deferral strategies can perform better. We first present a theoretical characterisation of the optimal deferral rule, which precisely characterises settings under which confidence-based deferral may suffer. We then study post-hoc deferral mechanisms, and demonstrate they can significantly improve upon confidence-based deferral in settings where (i) downstream models are specialists that only work well on a subset of inputs, (ii) samples are subject to label noise, and (iii) there is distribution shift between the train and test set.