 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled DiLoCo for Resilient Distributed Pre-training
Apr 23, 2026Modern large-scale language model pre-training relies heavily on the single program multiple data (SPMD) paradigm, which requires tight coupling across accelerators. Due to this coupling, transient slowdowns, hardware failures, and synchronization overhead stall the entire computation, wasting significant compute time at scale. While recent distributed methods like DiLoCo reduced communication bandwidth, they remained fundamentally synchronous and vulnerable to these system stalls. To address this, we introduce Decoupled DiLoCo, an evolution of the DiLoCo framework designed to break the lock-step synchronization barrier and go beyond SPMD to maximize training goodput. Decoupled DiLoCo partitions compute across multiple independent ``learners'' that execute local inner optimization steps. These learners asynchronously communicate parameter fragments to a central synchronizer, which circumvents failed or straggling learners by aggregating updates using a minimum quorum, an adaptive grace window, and dynamic token-weighted merging. Inspired by ``chaos engineering'', we achieve significantly improved training efficiency in failure-prone environments with millions of simulated chips with strictly zero global downtime, while maintaining competitive model performance across text and vision tasks, for both dense and mixture-of-expert architectures.
Global Convergence of Multiplicative Updates for the Matrix Mechanism: A Collaborative Proof with Gemini 3
Mar 19, 2026We analyze a fixed-point iteration $v \leftarrow φ(v)$ arising in the optimization of a regularized nuclear norm objective involving the Hadamard product structure, posed in~\cite{denisov} in the context of an optimization problem over the space of algorithms in private machine learning. We prove that the iteration $v^{(k+1)} = \text{diag}((D_{v^{(k)}}^{1/2} M D_{v^{(k)}}^{1/2})^{1/2})$ converges monotonically to the unique global optimizer of the potential function $J(v) = 2 \text{Tr}((D_v^{1/2} M D_v^{1/2})^{1/2}) - \sum v_i$, closing a problem left open there. The bulk of this proof was provided by Gemini 3, subject to some corrections and interventions. Gemini 3 also sketched the initial version of this note. Thus, it represents as much a commentary on the practical use of AI in mathematics as it represents the closure of a small gap in the literature. As such, we include a small narrative description of the prompting process, and some resulting principles for working with AI to prove mathematics.
Correlated Noise Mechanisms for Differentially Private Learning
Jun 09, 2025
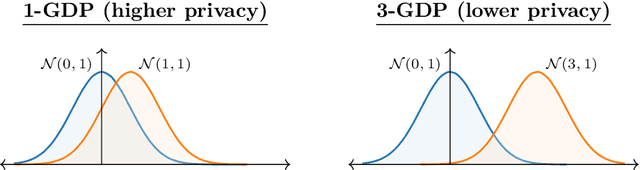

This monograph explores the design and analysis of correlated noise mechanisms for differential privacy (DP), focusing on their application to private training of AI and machine learning models via the core primitive of estimation of weighted prefix sums. While typical DP mechanisms inject independent noise into each step of a stochastic gradient (SGD) learning algorithm in order to protect the privacy of the training data, a growing body of recent research demonstrates that introducing (anti-)correlations in the noise can significantly improve privacy-utility trade-offs by carefully canceling out some of the noise added on earlier steps in subsequent steps. Such correlated noise mechanisms, known variously as matrix mechanisms, factorization mechanisms, and DP-Follow-the-Regularized-Leader (DP-FTRL) when applied to learning algorithms, have also been influential in practice, with industrial deployment at a global scale.
Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo
Mar 12, 2025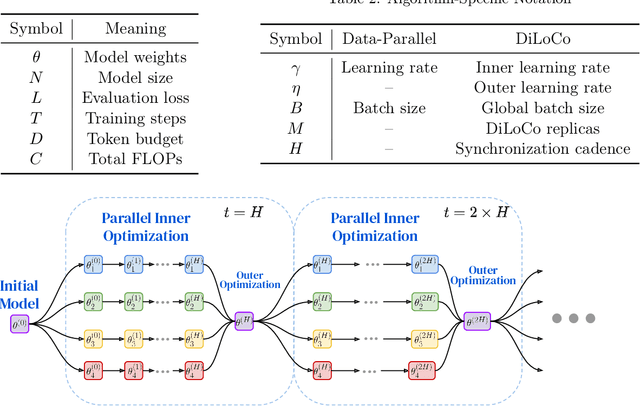
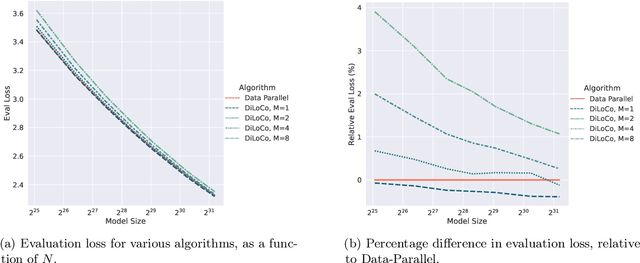
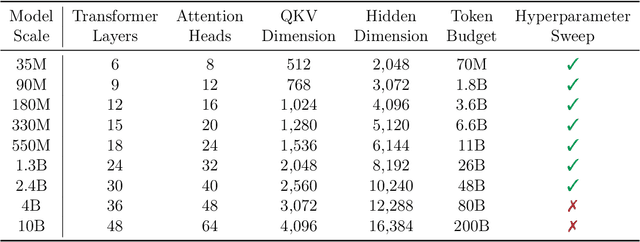
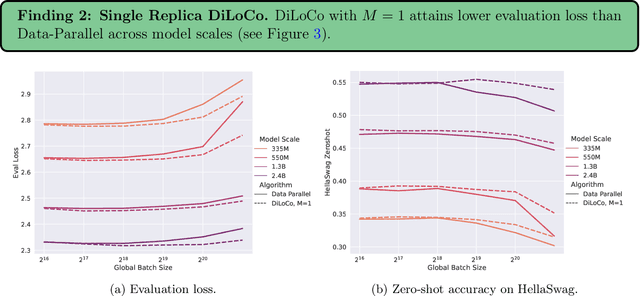
As we scale to more massive machine learning models, the frequent synchronization demands inherent in data-parallel approaches create significant slowdowns, posing a critical challenge to further scaling. Recent work develops an approach (DiLoCo) that relaxes synchronization demands without compromising model quality. However, these works do not carefully analyze how DiLoCo's behavior changes with model size. In this work, we study the scaling law behavior of DiLoCo when training LLMs under a fixed compute budget. We focus on how algorithmic factors, including number of model replicas, hyperparameters, and token budget affect training in ways that can be accurately predicted via scaling laws. We find that DiLoCo scales both predictably and robustly with model size. When well-tuned, DiLoCo scales better than data-parallel training with model size, and can outperform data-parallel training even at small model sizes. Our results showcase a more general set of benefits of DiLoCo than previously documented, including increased optimal batch sizes, improved downstream generalization with scale, and improved evaluation loss for a fixed token budget.
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
Fine-Tuning Large Language Models with User-Level Differential Privacy
Jul 10, 2024We investigate practical and scalable algorithms for training large language models (LLMs) with user-level differential privacy (DP) in order to provably safeguard all the examples contributed by each user. We study two variants of DP-SGD with: (1) example-level sampling (ELS) and per-example gradient clipping, and (2) user-level sampling (ULS) and per-user gradient clipping. We derive a novel user-level DP accountant that allows us to compute provably tight privacy guarantees for ELS. Using this, we show that while ELS can outperform ULS in specific settings, ULS generally yields better results when each user has a diverse collection of examples. We validate our findings through experiments in synthetic mean estimation and LLM fine-tuning tasks under fixed compute budgets. We find that ULS is significantly better in settings where either (1) strong privacy guarantees are required, or (2) the compute budget is large. Notably, our focus on LLM-compatible training algorithms allows us to scale to models with hundreds of millions of parameters and datasets with hundreds of thousands of users.
Cascade-Aware Training of Language Models
May 29, 2024



Reducing serving cost and latency is a fundamental concern for the deployment of language models (LMs) in business applications. To address this, cascades of LMs offer an effective solution that conditionally employ smaller models for simpler queries. Cascaded systems are typically built with independently trained models, neglecting the advantages of considering inference-time interactions of the cascaded LMs during training. In this paper, we present cascade-aware training(CAT), an approach to optimizing the overall quality-cost performance tradeoff of a cascade of LMs. We achieve inference-time benefits by training the small LM with awareness of its place in a cascade and downstream capabilities. We demonstrate the value of the proposed method with over 60 LM tasks of the SuperGLUE, WMT22, and FLAN2021 datasets.
FAX: Scalable and Differentiable Federated Primitives in JAX
Mar 11, 2024



We present FAX, a JAX-based library designed to support large-scale distributed and federated computations in both data center and cross-device applications. FAX leverages JAX's sharding mechanisms to enable native targeting of TPUs and state-of-the-art JAX runtimes, including Pathways. FAX embeds building blocks for federated computations as primitives in JAX. This enables three key benefits. First, FAX computations can be translated to XLA HLO. Second, FAX provides a full implementation of federated automatic differentiation, greatly simplifying the expression of federated computations. Last, FAX computations can be interpreted out to existing production cross-device federated compute systems. We show that FAX provides an easily programmable, performant, and scalable framework for federated computations in the data center. FAX is available at https://github.com/google-research/google-research/tree/master/fax .
(Amplified) Banded Matrix Factorization: A unified approach to private training
Jun 13, 2023



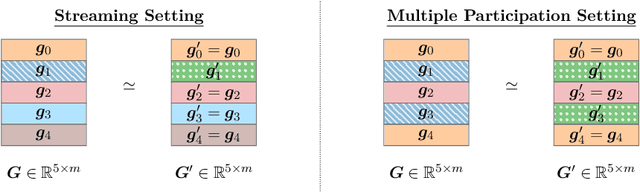
Matrix factorization (MF) mechanisms for differential privacy (DP) have substantially improved the state-of-the-art in privacy-utility-computation tradeoffs for ML applications in a variety of scenarios, but in both the centralized and federated settings there remain instances where either MF cannot be easily applied, or other algorithms provide better tradeoffs (typically, as $\epsilon$ becomes small). In this work, we show how MF can subsume prior state-of-the-art algorithms in both federated and centralized training settings, across all privacy budgets. The key technique throughout is the construction of MF mechanisms with banded matrices. For cross-device federated learning (FL), this enables multiple-participations with a relaxed device participation schema compatible with practical FL infrastructure (as demonstrated by a production deployment). In the centralized setting, we prove that banded matrices enjoy the same privacy amplification results as for the ubiquitous DP-SGD algorithm, but can provide strictly better performance in most scenarios -- this lets us always at least match DP-SGD, and often outperform it even at $\epsilon\ll2$. Finally, $\hat{b}$-banded matrices substantially reduce the memory and time complexity of per-step noise generation from $\mathcal{O}(n)$, $n$ the total number of iterations, to a constant $\mathcal{O}(\hat{b})$, compared to general MF mechanisms.
Convergence of Gradient Descent with Linearly Correlated Noise and Applications to Differentially Private Learning
Feb 02, 2023



We study stochastic optimization with linearly correlated noise. Our study is motivated by recent methods for optimization with differential privacy (DP), such as DP-FTRL, which inject noise via matrix factorization mechanisms. We propose an optimization problem that distils key facets of these DP methods and that involves perturbing gradients by linearly correlated noise. We derive improved convergence rates for gradient descent in this framework for convex and non-convex loss functions. Our theoretical analysis is novel and might be of independent interest. We use these convergence rates to develop new, effective matrix factorizations for differentially private optimization, and highlight the benefits of these factorizations theoretically and empirically.