 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABoN: Adaptive Best-of-N Alignment
May 17, 2025



Recent advances in test-time alignment methods, such as Best-of-N sampling, offer a simple and effective way to steer language models (LMs) toward preferred behaviors using reward models (RM). However, these approaches can be computationally expensive, especially when applied uniformly across prompts without accounting for differences in alignment difficulty. In this work, we propose a prompt-adaptive strategy for Best-of-N alignment that allocates inference-time compute more efficiently. Motivated by latency concerns, we develop a two-stage algorithm: an initial exploratory phase estimates the reward distribution for each prompt using a small exploration budget, and a second stage adaptively allocates the remaining budget using these estimates. Our method is simple, practical, and compatible with any LM/RM combination. Empirical results on the AlpacaEval dataset for 12 LM/RM pairs and 50 different batches of prompts show that our adaptive strategy consistently outperforms the uniform allocation with the same inference budget. Moreover, our experiments show that our adaptive strategy remains competitive against uniform allocations with 20% larger inference budgets and even improves in performance as the batch size grows.
Eager Updates For Overlapped Communication and Computation in DiLoCo
Feb 18, 2025
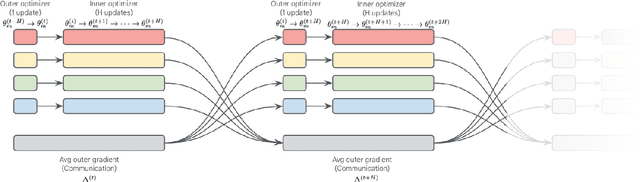
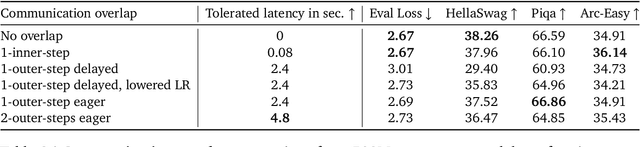
Distributed optimization methods such as DiLoCo have been shown to be effective in training very large models across multiple distributed workers, such as datacenters. These methods split updates into two parts: an inner optimization phase, where the workers independently execute multiple optimization steps on their own local data, and an outer optimization step, where the inner updates are synchronized. While such approaches require orders of magnitude less communication than standard data-parallel training, in settings where the workers are datacenters, even the limited communication requirements of these approaches can still cause significant slow downs due to the blocking necessary at each outer optimization step. In this paper, we investigate techniques to mitigate this issue by overlapping communication with computation in a manner that allows the outer optimization step to fully overlap with the inner optimization phase. We show that a particular variant, dubbed eager updates, provides competitive performance with standard DiLoCo in settings with low bandwidth between workers.
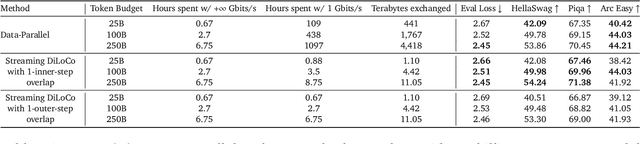
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
Stacking as Accelerated Gradient Descent
Mar 08, 2024



Stacking, a heuristic technique for training deep residual networks by progressively increasing the number of layers and initializing new layers by copying parameters from older layers, has proven quite successful in improving the efficiency of training deep neural networks. In this paper, we propose a theoretical explanation for the efficacy of stacking: viz., stacking implements a form of Nesterov's accelerated gradient descent. The theory also covers simpler models such as the additive ensembles constructed in boosting methods, and provides an explanation for a similar widely-used practical heuristic for initializing the new classifier in each round of boosting. We also prove that for certain deep linear residual networks, stacking does provide accelerated training, via a new potential function analysis of the Nesterov's accelerated gradient method which allows errors in updates. We conduct proof-of-concept experiments to validate our theory as well.
Efficient Stagewise Pretraining via Progressive Subnetworks
Feb 08, 2024Recent developments in large language models have sparked interest in efficient pretraining methods. A recent effective paradigm is to perform stage-wise training, where the size of the model is gradually increased over the course of training (e.g. gradual stacking (Reddi et al., 2023)). While the resource and wall-time savings are appealing, it has limitations, particularly the inability to evaluate the full model during earlier stages, and degradation in model quality due to smaller model capacity in the initial stages. In this work, we propose an alternative framework, progressive subnetwork training, that maintains the full model throughout training, but only trains subnetworks within the model in each step. We focus on a simple instantiation of this framework, Random Path Training (RaPTr) that only trains a sub-path of layers in each step, progressively increasing the path lengths in stages. RaPTr achieves better pre-training loss for BERT and UL2 language models while requiring 20-33% fewer FLOPs compared to standard training, and is competitive or better than other efficient training methods. Furthermore, RaPTr shows better downstream performance on UL2, improving QA tasks and SuperGLUE by 1-5% compared to standard training and stacking. Finally, we provide a theoretical basis for RaPTr to justify (a) the increasing complexity of subnetworks in stages, and (b) the stability in loss across stage transitions due to residual connections and layer norm.
Asynchronous Local-SGD Training for Language Modeling
Jan 17, 2024



Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {\it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps. We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact the learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently. We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers' local training steps based on their computation speed. This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
Improved Differentially Private and Lazy Online Convex Optimization
Dec 20, 2023We study the task of $(\epsilon, \delta)$-differentially private online convex optimization (OCO). In the online setting, the release of each distinct decision or iterate carries with it the potential for privacy loss. This problem has a long history of research starting with Jain et al. [2012] and the best known results for the regime of {\epsilon} not being very small are presented in Agarwal et al. [2023]. In this paper we improve upon the results of Agarwal et al. [2023] in terms of the dimension factors as well as removing the requirement of smoothness. Our results are now the best known rates for DP-OCO in this regime. Our algorithms builds upon the work of [Asi et al., 2023] which introduced the idea of explicitly limiting the number of switches via rejection sampling. The main innovation in our algorithm is the use of sampling from a strongly log-concave density which allows us to trade-off the dimension factors better leading to improved results.
On the Convergence of Federated Averaging with Cyclic Client Participation
Feb 06, 2023



Federated Averaging (FedAvg) and its variants are the most popular optimization algorithms in federated learning (FL). Previous convergence analyses of FedAvg either assume full client participation or partial client participation where the clients can be uniformly sampled. However, in practical cross-device FL systems, only a subset of clients that satisfy local criteria such as battery status, network connectivity, and maximum participation frequency requirements (to ensure privacy) are available for training at a given time. As a result, client availability follows a natural cyclic pattern. We provide (to our knowledge) the first theoretical framework to analyze the convergence of FedAvg with cyclic client participation with several different client optimizers such as GD, SGD, and shuffled SGD. Our analysis discovers that cyclic client participation can achieve a faster asymptotic convergence rate than vanilla FedAvg with uniform client participation under suitable conditions, providing valuable insights into the design of client sampling protocols.
From Gradient Flow on Population Loss to Learning with Stochastic Gradient Descent
Oct 13, 2022Stochastic Gradient Descent (SGD) has been the method of choice for learning large-scale non-convex models. While a general analysis of when SGD works has been elusive, there has been a lot of recent progress in understanding the convergence of Gradient Flow (GF) on the population loss, partly due to the simplicity that a continuous-time analysis buys us. An overarching theme of our paper is providing general conditions under which SGD converges, assuming that GF on the population loss converges. Our main tool to establish this connection is a general converse Lyapunov like theorem, which implies the existence of a Lyapunov potential under mild assumptions on the rates of convergence of GF. In fact, using these potentials, we show a one-to-one correspondence between rates of convergence of GF and geometrical properties of the underlying objective. When these potentials further satisfy certain self-bounding properties, we show that they can be used to provide a convergence guarantee for Gradient Descent (GD) and SGD (even when the paths of GF and GD/SGD are quite far apart). It turns out that these self-bounding assumptions are in a sense also necessary for GD/SGD to work. Using our framework, we provide a unified analysis for GD/SGD not only for classical settings like convex losses, or objectives that satisfy PL / KL properties, but also for more complex problems including Phase Retrieval and Matrix sq-root, and extending the results in the recent work of Chatterjee 2022.
Private Matrix Approximation and Geometry of Unitary Orbits
Jul 06, 2022Consider the following optimization problem: Given $n \times n$ matrices $A$ and $\Lambda$, maximize $\langle A, U\Lambda U^*\rangle$ where $U$ varies over the unitary group $\mathrm{U}(n)$. This problem seeks to approximate $A$ by a matrix whose spectrum is the same as $\Lambda$ and, by setting $\Lambda$ to be appropriate diagonal matrices, one can recover matrix approximation problems such as PCA and rank-$k$ approximation. We study the problem of designing differentially private algorithms for this optimization problem in settings where the matrix $A$ is constructed using users' private data. We give efficient and private algorithms that come with upper and lower bounds on the approximation error. Our results unify and improve upon several prior works on private matrix approximation problems. They rely on extensions of packing/covering number bounds for Grassmannians to unitary orbits which should be of independent interest.