 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Low-Rank Approximation for Federated Fine-tuning of On-Device Foundation Models
Jan 12, 2024Large foundation models (FMs) adapt surprisingly well to specific domains or tasks with fine-tuning. Federated learning (FL) further enables private FM fine-tuning using the local data on devices. However, the standard FMs' large size poses challenges for resource-constrained and heterogeneous devices. To address this, we consider FMs with reduced parameter sizes, referred to as on-device FMs (ODFMs). While ODFMs allow on-device inference, computational constraints still hinder efficient federated fine-tuning. We propose a parameter-efficient federated fine-tuning method for ODFMs using heterogeneous low-rank approximations (LoRAs) that addresses system and data heterogeneity. We show that homogeneous LoRA ranks face a trade-off between overfitting and slow convergence, and propose HetLoRA, which employs heterogeneous ranks across clients and eliminates the shortcomings of homogeneous HetLoRA. By applying rank self-pruning locally and sparsity-weighted aggregation at the server, we combine the advantages of high and low-rank LoRAs, which achieves improved convergence speed and final performance compared to homogeneous LoRA. Furthermore, it offers enhanced computation efficiency compared to full fine-tuning, making it suitable for heterogeneous devices while preserving data privacy.
Local or Global: Selective Knowledge Assimilation for Federated Learning with Limited Labels
Jul 17, 2023
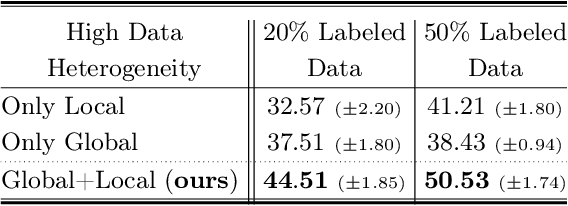


Many existing FL methods assume clients with fully-labeled data, while in realistic settings, clients have limited labels due to the expensive and laborious process of labeling. Limited labeled local data of the clients often leads to their local model having poor generalization abilities to their larger unlabeled local data, such as having class-distribution mismatch with the unlabeled data. As a result, clients may instead look to benefit from the global model trained across clients to leverage their unlabeled data, but this also becomes difficult due to data heterogeneity across clients. In our work, we propose FedLabel where clients selectively choose the local or global model to pseudo-label their unlabeled data depending on which is more of an expert of the data. We further utilize both the local and global models' knowledge via global-local consistency regularization which minimizes the divergence between the two models' outputs when they have identical pseudo-labels for the unlabeled data. Unlike other semi-supervised FL baselines, our method does not require additional experts other than the local or global model, nor require additional parameters to be communicated. We also do not assume any server-labeled data or fully labeled clients. For both cross-device and cross-silo settings, we show that FedLabel outperforms other semi-supervised FL baselines by $8$-$24\%$, and even outperforms standard fully supervised FL baselines ($100\%$ labeled data) with only $5$-$20\%$ of labeled data.
On the Convergence of Federated Averaging with Cyclic Client Participation
Feb 06, 2023



Federated Averaging (FedAvg) and its variants are the most popular optimization algorithms in federated learning (FL). Previous convergence analyses of FedAvg either assume full client participation or partial client participation where the clients can be uniformly sampled. However, in practical cross-device FL systems, only a subset of clients that satisfy local criteria such as battery status, network connectivity, and maximum participation frequency requirements (to ensure privacy) are available for training at a given time. As a result, client availability follows a natural cyclic pattern. We provide (to our knowledge) the first theoretical framework to analyze the convergence of FedAvg with cyclic client participation with several different client optimizers such as GD, SGD, and shuffled SGD. Our analysis discovers that cyclic client participation can achieve a faster asymptotic convergence rate than vanilla FedAvg with uniform client participation under suitable conditions, providing valuable insights into the design of client sampling protocols.
To Federate or Not To Federate: Incentivizing Client Participation in Federated Learning
May 30, 2022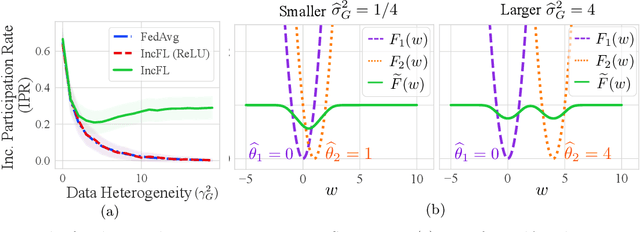

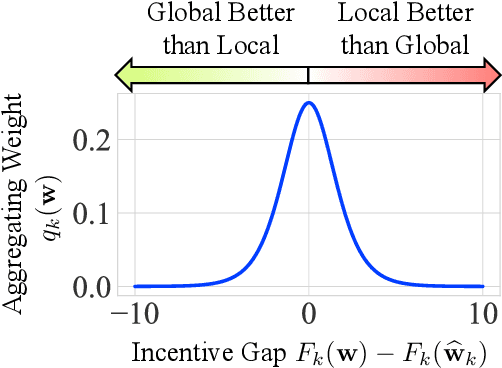
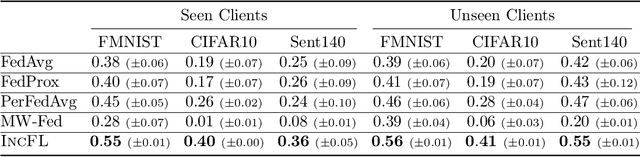
Federated learning (FL) facilitates collaboration between a group of clients who seek to train a common machine learning model without directly sharing their local data. Although there is an abundance of research on improving the speed, efficiency, and accuracy of federated training, most works implicitly assume that all clients are willing to participate in the FL framework. Due to data heterogeneity, however, the global model may not work well for some clients, and they may instead choose to use their own local model. Such disincentivization of clients can be problematic from the server's perspective because having more participating clients yields a better global model, and offers better privacy guarantees to the participating clients. In this paper, we propose an algorithm called IncFL that explicitly maximizes the fraction of clients who are incentivized to use the global model by dynamically adjusting the aggregation weights assigned to their updates. Our experiments show that IncFL increases the number of incentivized clients by 30-55% compared to standard federated training algorithms, and can also improve the generalization performance of the global model on unseen clients.
Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Apr 27, 2022
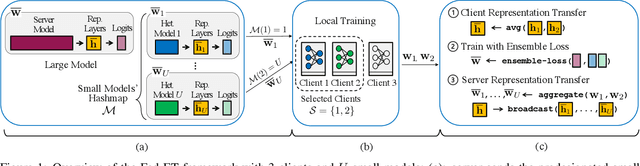

Federated learning (FL) enables edge-devices to collaboratively learn a model without disclosing their private data to a central aggregating server. Most existing FL algorithms require models of identical architecture to be deployed across the clients and server, making it infeasible to train large models due to clients' limited system resources. In this work, we propose a novel ensemble knowledge transfer method named Fed-ET in which small models (different in architecture) are trained on clients, and used to train a larger model at the server. Unlike in conventional ensemble learning, in FL the ensemble can be trained on clients' highly heterogeneous data. Cognizant of this property, Fed-ET uses a weighted consensus distillation scheme with diversity regularization that efficiently extracts reliable consensus from the ensemble while improving generalization by exploiting the diversity within the ensemble. We show the generalization bound for the ensemble of weighted models trained on heterogeneous datasets that supports the intuition of Fed-ET. Our experiments on image and language tasks show that Fed-ET significantly outperforms other state-of-the-art FL algorithms with fewer communicated parameters, and is also robust against high data-heterogeneity.
Personalized Federated Learning for Heterogeneous Clients with Clustered Knowledge Transfer
Sep 16, 2021
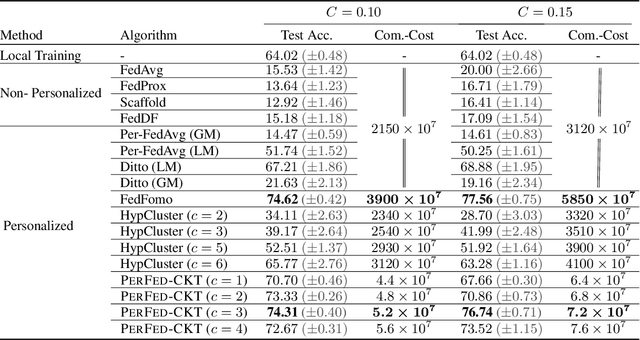


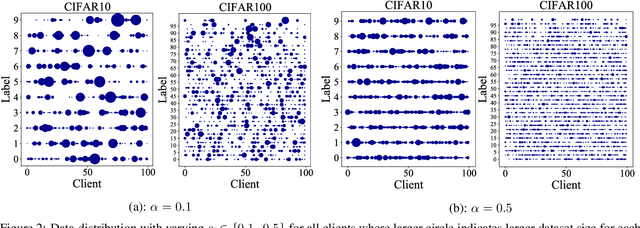
Personalized federated learning (FL) aims to train model(s) that can perform well for individual clients that are highly data and system heterogeneous. Most work in personalized FL, however, assumes using the same model architecture at all clients and increases the communication cost by sending/receiving models. This may not be feasible for realistic scenarios of FL. In practice, clients have highly heterogeneous system-capabilities and limited communication resources. In our work, we propose a personalized FL framework, PerFed-CKT, where clients can use heterogeneous model architectures and do not directly communicate their model parameters. PerFed-CKT uses clustered co-distillation, where clients use logits to transfer their knowledge to other clients that have similar data-distributions. We theoretically show the convergence and generalization properties of PerFed-CKT and empirically show that PerFed-CKT achieves high test accuracy with several orders of magnitude lower communication cost compared to the state-of-the-art personalized FL schemes.
Bandit-based Communication-Efficient Client Selection Strategies for Federated Learning
Dec 14, 2020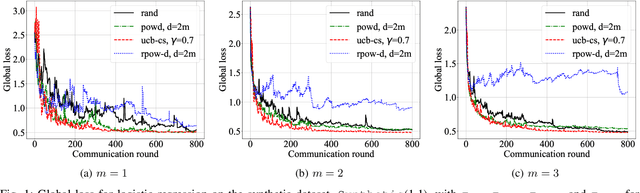
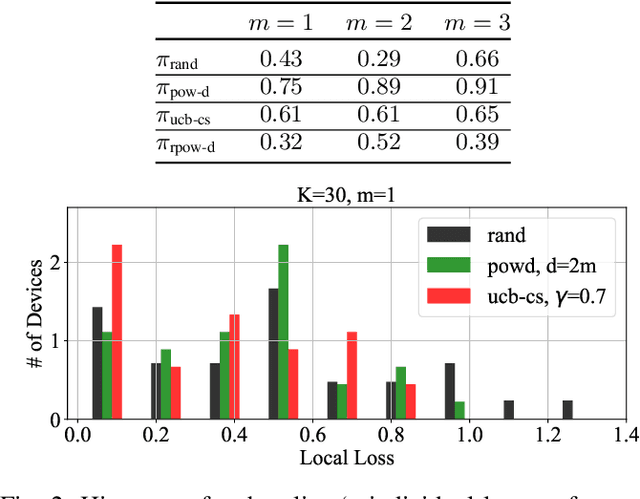
Due to communication constraints and intermittent client availability in federated learning, only a subset of clients can participate in each training round. While most prior works assume uniform and unbiased client selection, recent work on biased client selection has shown that selecting clients with higher local losses can improve error convergence speed. However, previously proposed biased selection strategies either require additional communication cost for evaluating the exact local loss or utilize stale local loss, which can even make the model diverge. In this paper, we present a bandit-based communication-efficient client selection strategy UCB-CS that achieves faster convergence with lower communication overhead. We also demonstrate how client selection can be used to improve fairness.
Client Selection in Federated Learning: Convergence Analysis and Power-of-Choice Selection Strategies
Oct 03, 2020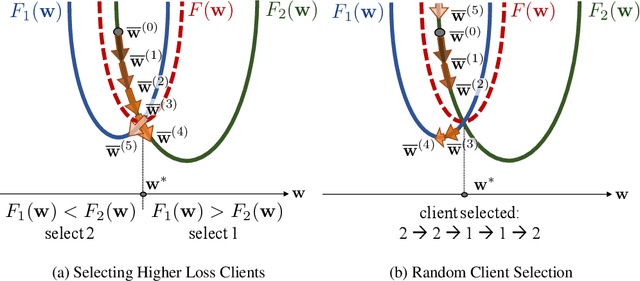

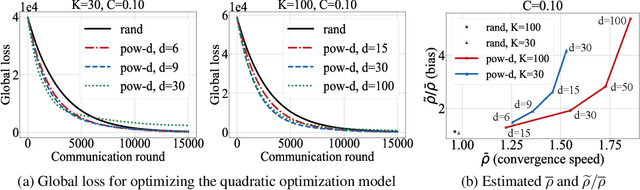

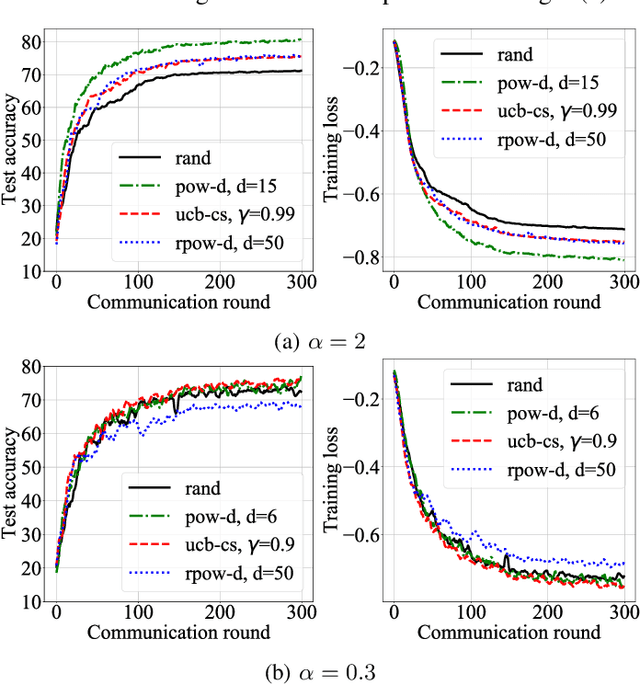
Federated learning is a distributed optimization paradigm that enables a large number of resource-limited client nodes to cooperatively train a model without data sharing. Several works have analyzed the convergence of federated learning by accounting of data heterogeneity, communication and computation limitations, and partial client participation. However, they assume unbiased client participation, where clients are selected at random or in proportion of their data sizes. In this paper, we present the first convergence analysis of federated optimization for biased client selection strategies, and quantify how the selection bias affects convergence speed. We reveal that biasing client selection towards clients with higher local loss achieves faster error convergence. Using this insight, we propose Power-of-Choice, a communication- and computation-efficient client selection framework that can flexibly span the trade-off between convergence speed and solution bias. Our experiments demonstrate that Power-of-Choice strategies converge up to 3 $\times$ faster and give $10$% higher test accuracy than the baseline random selection.