 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bag of Tricks for Few-Shot Class-Incremental Learning
Mar 21, 2024
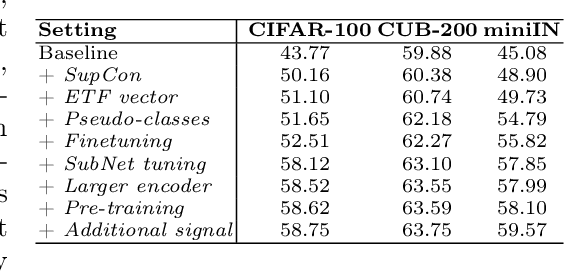


We present a bag of tricks framework for few-shot class-incremental learning (FSCIL), which is a challenging form of continual learning that involves continuous adaptation to new tasks with limited samples. FSCIL requires both stability and adaptability, i.e., preserving proficiency in previously learned tasks while learning new ones. Our proposed bag of tricks brings together eight key and highly influential techniques that improve stability, adaptability, and overall performance under a unified framework for FSCIL. We organize these tricks into three categories: stability tricks, adaptability tricks, and training tricks. Stability tricks aim to mitigate the forgetting of previously learned classes by enhancing the separation between the embeddings of learned classes and minimizing interference when learning new ones. On the other hand, adaptability tricks focus on the effective learning of new classes. Finally, training tricks improve the overall performance without compromising stability or adaptability. We perform extensive experiments on three benchmark datasets, CIFAR-100, CUB-200, and miniIMageNet, to evaluate the impact of our proposed framework. Our detailed analysis shows that our approach substantially improves both stability and adaptability, establishing a new state-of-the-art by outperforming prior works in the area. We believe our method provides a go-to solution and establishes a robust baseline for future research in this area.
Heterogeneous Low-Rank Approximation for Federated Fine-tuning of On-Device Foundation Models
Jan 12, 2024Large foundation models (FMs) adapt surprisingly well to specific domains or tasks with fine-tuning. Federated learning (FL) further enables private FM fine-tuning using the local data on devices. However, the standard FMs' large size poses challenges for resource-constrained and heterogeneous devices. To address this, we consider FMs with reduced parameter sizes, referred to as on-device FMs (ODFMs). While ODFMs allow on-device inference, computational constraints still hinder efficient federated fine-tuning. We propose a parameter-efficient federated fine-tuning method for ODFMs using heterogeneous low-rank approximations (LoRAs) that addresses system and data heterogeneity. We show that homogeneous LoRA ranks face a trade-off between overfitting and slow convergence, and propose HetLoRA, which employs heterogeneous ranks across clients and eliminates the shortcomings of homogeneous HetLoRA. By applying rank self-pruning locally and sparsity-weighted aggregation at the server, we combine the advantages of high and low-rank LoRAs, which achieves improved convergence speed and final performance compared to homogeneous LoRA. Furthermore, it offers enhanced computation efficiency compared to full fine-tuning, making it suitable for heterogeneous devices while preserving data privacy.