 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need Reasoning to Learn Reasoning: The Limitations of Label-Free RL in Weak Base Models
Nov 07, 2025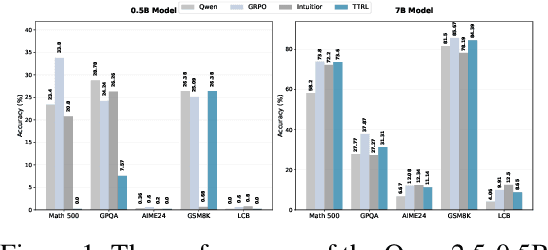
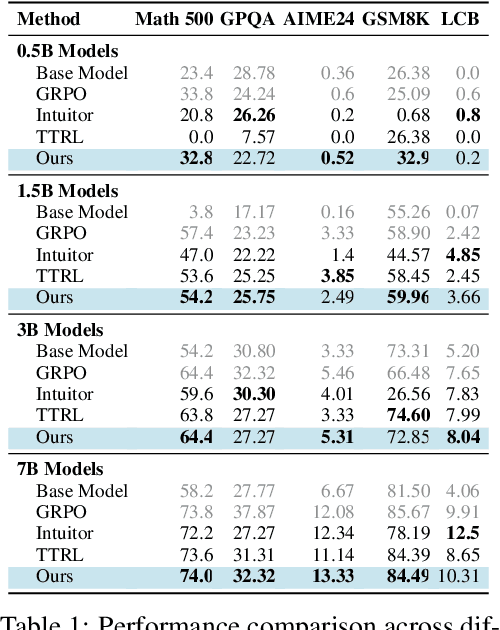

Recent advances in large language models have demonstrated the promise of unsupervised reinforcement learning (RL) methods for enhancing reasoning capabilities without external supervision. However, the generalizability of these label-free RL approaches to smaller base models with limited reasoning capabilities remains unexplored. In this work, we systematically investigate the performance of label-free RL methods across different model sizes and reasoning strengths, from 0.5B to 7B parameters. Our empirical analysis reveals critical limitations: label-free RL is highly dependent on the base model's pre-existing reasoning capability, with performance often degrading below baseline levels for weaker models. We find that smaller models fail to generate sufficiently long or diverse chain-of-thought reasoning to enable effective self-reflection, and that training data difficulty plays a crucial role in determining success. To address these challenges, we propose a simple yet effective method for label-free RL that utilizes curriculum learning to progressively introduce harder problems during training and mask no-majority rollouts during training. Additionally, we introduce a data curation pipeline to generate samples with predefined difficulty. Our approach demonstrates consistent improvements across all model sizes and reasoning capabilities, providing a path toward more robust unsupervised RL that can bootstrap reasoning abilities in resource-constrained models. We make our code available at https://github.com/BorealisAI/CuMa
Advancing Medical Representation Learning Through High-Quality Data
Mar 18, 2025Despite the growing scale of medical Vision-Language datasets, the impact of dataset quality on model performance remains under-explored. We introduce Open-PMC, a high-quality medical dataset from PubMed Central, containing 2.2 million image-text pairs, enriched with image modality annotations, subfigures, and summarized in-text references. Notably, the in-text references provide richer medical context, extending beyond the abstract information typically found in captions. Through extensive experiments, we benchmark Open-PMC against larger datasets across retrieval and zero-shot classification tasks. Our results show that dataset quality-not just size-drives significant performance gains. We complement our benchmark with an in-depth analysis of feature representation. Our findings highlight the crucial role of data curation quality in advancing multimodal medical AI. We release Open-PMC, along with the trained models and our codebase.
A Shared Encoder Approach to Multimodal Representation Learning
Mar 03, 2025Multimodal representation learning has demonstrated remarkable potential in enabling models to process and integrate diverse data modalities, such as text and images, for improved understanding and performance. While the medical domain can benefit significantly from this paradigm, the scarcity of paired multimodal data and reliance on proprietary or pretrained encoders pose significant challenges. In this work, we present a shared encoder framework for multimodal representation learning tailored to the medical domain. Our approach employs a single set of encoder parameters shared across modalities, augmented with learnable modality features. Empirical results demonstrate that our shared encoder idea achieves superior performance compared to separate modality-specific encoders, demonstrating improved generalization in data-constrained settings. Notably, the performance gains are more pronounced with fewer training examples, underscoring the efficiency of our shared encoder framework for real-world medical applications with limited data. Our code and experiment setup are available at https://github.com/VectorInstitute/shared_encoder.
Task-agnostic Prompt Compression with Context-aware Sentence Embedding and Reward-guided Task Descriptor
Feb 19, 2025The rise of Large Language Models (LLMs) has led to significant interest in prompt compression, a technique aimed at reducing the length of input prompts while preserving critical information. However, the prominent approaches in prompt compression often require explicit questions or handcrafted templates for compression, limiting their generalizability. We propose Task-agnostic Prompt Compression (TPC), a novel framework that generalizes compression across tasks and domains without requiring input questions or templates. TPC generates a context-relevant task description using a task descriptor trained on a curated dataset of context and query pairs, and fine-tuned via reinforcement learning with a reward function designed to capture the most relevant information. The task descriptor is then utilized to compute the relevance of each sentence in the prompt to generate the compressed prompt. We introduce 3 model sizes (Base, Large, and Huge), where the largest model outperforms the existing state-of-the-art methods on LongBench and ZeroSCROLLS benchmarks, and our smallest model performs comparable to the existing solutions while being considerably smaller.
SelfPrompt: Confidence-Aware Semi-Supervised Tuning for Robust Vision-Language Model Adaptation
Jan 24, 2025We present SelfPrompt, a novel prompt-tuning approach for vision-language models (VLMs) in a semi-supervised learning setup. Existing methods for tuning VLMs in semi-supervised setups struggle with the negative impact of the miscalibrated VLMs on pseudo-labelling, and the accumulation of noisy pseudo-labels. SelfPrompt addresses these challenges by introducing a cluster-guided pseudo-labelling method that improves pseudo-label accuracy, and a confidence-aware semi-supervised learning module that maximizes the utilization of unlabelled data by combining supervised learning and weakly-supervised learning. Additionally, we investigate our method in an active semi-supervised learning setup, where the labelled set is strategically selected to ensure the best utilization of a limited labelling budget. To this end, we propose a weakly-supervised sampling technique that selects a diverse and representative labelled set, which can be seamlessly integrated into existing methods to enhance their performance. We conduct extensive evaluations across 13 datasets, significantly surpassing state-of-the-art performances with average improvements of 6.23% in standard semi-supervised learning, 6.25% in active semi-supervised learning, and 4.9% in base-to-novel generalization, using a 2-shot setup. Furthermore, SelfPrompt shows excellent generalization in single-shot settings, achieving an average improvement of 11.78%.
Prompt Compression with Context-Aware Sentence Encoding for Fast and Improved LLM Inference
Sep 04, 2024



Large language models (LLMs) have triggered a new stream of research focusing on compressing the context length to reduce the computational cost while ensuring the retention of helpful information for LLMs to answer the given question. Token-based removal methods are one of the most prominent approaches in this direction, but risk losing the semantics of the context caused by intermediate token removal, especially under high compression ratios, while also facing challenges in computational efficiency. In this work, we propose context-aware prompt compression (CPC), a sentence-level prompt compression technique where its key innovation is a novel context-aware sentence encoder that provides a relevance score for each sentence for a given question. To train this encoder, we generate a new dataset consisting of questions, positives, and negative pairs where positives are sentences relevant to the question, while negatives are irrelevant context sentences. We train the encoder in a contrastive setup to learn context-aware sentence representations. Our method considerably outperforms prior works on prompt compression on benchmark datasets and is up to 10.93x faster at inference compared to the best token-level compression method. We also find better improvement for shorter length constraints in most benchmarks, showing the effectiveness of our proposed solution in the compression of relevant information in a shorter context. Finally, we release the code and the dataset for quick reproducibility and further development: https://github.com/Workday/cpc.
Benchmarking Vision-Language Contrastive Methods for Medical Representation Learning
Jun 11, 2024



We perform a comprehensive benchmarking of contrastive frameworks for learning multimodal representations in the medical domain. Through this study, we aim to answer the following research questions: (i) How transferable are general-domain representations to the medical domain? (ii) Is multimodal contrastive training sufficient, or does it benefit from unimodal training as well? (iii) What is the impact of feature granularity on the effectiveness of multimodal medical representation learning? To answer these questions, we investigate eight contrastive learning approaches under identical training setups, and train them on 2.8 million image-text pairs from four datasets, and evaluate them on 25 downstream tasks, including classification (zero-shot and linear probing), image-to-text and text-to-image retrieval, and visual question-answering. Our findings suggest a positive answer to the first question, a negative answer to the second question, and the benefit of learning fine-grained features. Finally, we make our code publicly available.
Few-shot Tuning of Foundation Models for Class-incremental Learning
May 26, 2024For the first time, we explore few-shot tuning of vision foundation models for class-incremental learning. Unlike existing few-shot class incremental learning (FSCIL) methods, which train an encoder on a base session to ensure forward compatibility for future continual learning, foundation models are generally trained on large unlabelled data without such considerations. This renders prior methods from traditional FSCIL incompatible for FSCIL with the foundation model. To this end, we propose Consistency-guided Asynchronous Contrastive Tuning (CoACT), a new approach to continually tune foundation models for new classes in few-shot settings. CoACT comprises three components: (i) asynchronous contrastive tuning, which learns new classes by including LoRA modules in the pre-trained encoder, while enforcing consistency between two asynchronous encoders; (ii) controlled fine-tuning, which facilitates effective tuning of a subset of the foundation model; and (iii) consistency-guided incremental tuning, which enforces additional regularization during later sessions to reduce forgetting of the learned classes. We perform an extensive study on 16 diverse datasets and demonstrate the effectiveness of CoACT, outperforming the best baseline method by 2.47% on average and with up to 12.52% on individual datasets. Additionally, CoACT shows reduced forgetting and robustness in low-shot experiments. As an added bonus, CoACT shows up to 13.5% improvement in standard FSCIL over the current SOTA on benchmark evaluations. We make our code publicly available at https://github.com/ShuvenduRoy/CoACT-FSCIL.
A Bag of Tricks for Few-Shot Class-Incremental Learning
Mar 21, 2024
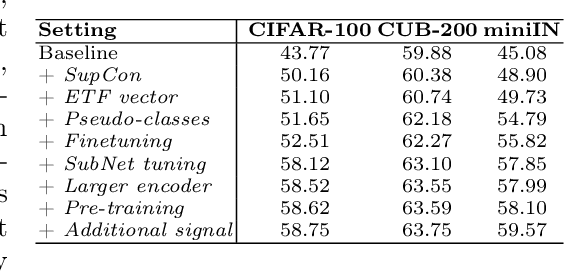


We present a bag of tricks framework for few-shot class-incremental learning (FSCIL), which is a challenging form of continual learning that involves continuous adaptation to new tasks with limited samples. FSCIL requires both stability and adaptability, i.e., preserving proficiency in previously learned tasks while learning new ones. Our proposed bag of tricks brings together eight key and highly influential techniques that improve stability, adaptability, and overall performance under a unified framework for FSCIL. We organize these tricks into three categories: stability tricks, adaptability tricks, and training tricks. Stability tricks aim to mitigate the forgetting of previously learned classes by enhancing the separation between the embeddings of learned classes and minimizing interference when learning new ones. On the other hand, adaptability tricks focus on the effective learning of new classes. Finally, training tricks improve the overall performance without compromising stability or adaptability. We perform extensive experiments on three benchmark datasets, CIFAR-100, CUB-200, and miniIMageNet, to evaluate the impact of our proposed framework. Our detailed analysis shows that our approach substantially improves both stability and adaptability, establishing a new state-of-the-art by outperforming prior works in the area. We believe our method provides a go-to solution and establishes a robust baseline for future research in this area.
Contrastive Learning of View-Invariant Representations for Facial Expressions Recognition
Nov 12, 2023Although there has been much progress in the area of facial expression recognition (FER), most existing methods suffer when presented with images that have been captured from viewing angles that are non-frontal and substantially different from those used in the training process. In this paper, we propose ViewFX, a novel view-invariant FER framework based on contrastive learning, capable of accurately classifying facial expressions regardless of the input viewing angles during inference. ViewFX learns view-invariant features of expression using a proposed self-supervised contrastive loss which brings together different views of the same subject with a particular expression in the embedding space. We also introduce a supervised contrastive loss to push the learnt view-invariant features of each expression away from other expressions. Since facial expressions are often distinguished with very subtle differences in the learned feature space, we incorporate the Barlow twins loss to reduce the redundancy and correlations of the representations in the learned representations. The proposed method is a substantial extension of our previously proposed CL-MEx, which only had a self-supervised loss. We test the proposed framework on two public multi-view facial expression recognition datasets, KDEF and DDCF. The experiments demonstrate that our approach outperforms previous works in the area and sets a new state-of-the-art for both datasets while showing considerably less sensitivity to challenging angles and the number of output labels used for training. We also perform detailed sensitivity and ablation experiments to evaluate the impact of different components of our model as well as its sensitivity to different parameters.