 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoJEPA: A Latent Predictive Foundation Model for Echocardiography
Feb 02, 2026Foundation models for echocardiography promise to reduce annotation burden and improve diagnostic consistency by learning generalizable representations from large unlabeled video archives. However, current approaches fail to disentangle anatomical signal from the stochastic speckle and acquisition artifacts that dominate ultrasound imagery. We present EchoJEPA, a foundation model for echocardiography trained on 18 million echocardiograms across 300K patients, the largest pretraining corpus for this modality to date. We also introduce a novel multi-view probing framework with factorized stream embeddings that standardizes evaluation under frozen backbones. Compared to prior methods, EchoJEPA reduces left ventricular ejection fraction estimation error by 19% and achieves 87.4% view classification accuracy. EchoJEPA exhibits strong sample efficiency, reaching 78.6% accuracy with only 1% of labeled data versus 42.1% for the best baseline trained on 100%. Under acoustic perturbations, EchoJEPA degrades by only 2.3% compared to 16.8% for the next best model, and transfers zero-shot to pediatric patients with 15% lower error than the next best model, outperforming all fine-tuned baselines. These results establish latent prediction as a superior paradigm for ultrasound foundation models.
BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model
May 29, 2025
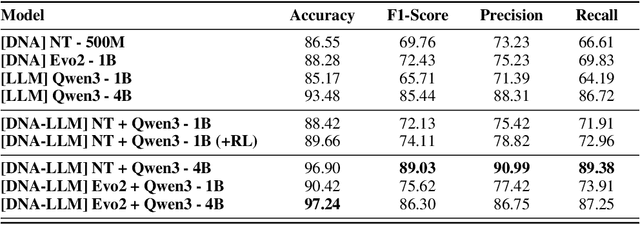


Unlocking deep, interpretable biological reasoning from complex genomic data is a major AI challenge hindering scientific discovery. Current DNA foundation models, despite strong sequence representation, struggle with multi-step reasoning and lack inherent transparent, biologically intuitive explanations. We introduce BioReason, a pioneering architecture that, for the first time, deeply integrates a DNA foundation model with a Large Language Model (LLM). This novel connection enables the LLM to directly process and reason with genomic information as a fundamental input, fostering a new form of multimodal biological understanding. BioReason's sophisticated multi-step reasoning is developed through supervised fine-tuning and targeted reinforcement learning, guiding the system to generate logical, biologically coherent deductions. On biological reasoning benchmarks including KEGG-based disease pathway prediction - where accuracy improves from 88% to 97% - and variant effect prediction, BioReason demonstrates an average 15% performance gain over strong single-modality baselines. BioReason reasons over unseen biological entities and articulates decision-making through interpretable, step-by-step biological traces, offering a transformative approach for AI in biology that enables deeper mechanistic insights and accelerates testable hypothesis generation from genomic data. Data, code, and checkpoints are publicly available at https://github.com/bowang-lab/BioReason
MedSAM2: Segment Anything in 3D Medical Images and Videos
Apr 04, 2025Medical image and video segmentation is a critical task for precision medicine, which has witnessed considerable progress in developing task or modality-specific and generalist models for 2D images. However, there have been limited studies on building general-purpose models for 3D images and videos with comprehensive user studies. Here, we present MedSAM2, a promptable segmentation foundation model for 3D image and video segmentation. The model is developed by fine-tuning the Segment Anything Model 2 on a large medical dataset with over 455,000 3D image-mask pairs and 76,000 frames, outperforming previous models across a wide range of organs, lesions, and imaging modalities. Furthermore, we implement a human-in-the-loop pipeline to facilitate the creation of large-scale datasets resulting in, to the best of our knowledge, the most extensive user study to date, involving the annotation of 5,000 CT lesions, 3,984 liver MRI lesions, and 251,550 echocardiogram video frames, demonstrating that MedSAM2 can reduce manual costs by more than 85%. MedSAM2 is also integrated into widely used platforms with user-friendly interfaces for local and cloud deployment, making it a practical tool for supporting efficient, scalable, and high-quality segmentation in both research and healthcare environments.
Advancing Medical Representation Learning Through High-Quality Data
Mar 18, 2025Despite the growing scale of medical Vision-Language datasets, the impact of dataset quality on model performance remains under-explored. We introduce Open-PMC, a high-quality medical dataset from PubMed Central, containing 2.2 million image-text pairs, enriched with image modality annotations, subfigures, and summarized in-text references. Notably, the in-text references provide richer medical context, extending beyond the abstract information typically found in captions. Through extensive experiments, we benchmark Open-PMC against larger datasets across retrieval and zero-shot classification tasks. Our results show that dataset quality-not just size-drives significant performance gains. We complement our benchmark with an in-depth analysis of feature representation. Our findings highlight the crucial role of data curation quality in advancing multimodal medical AI. We release Open-PMC, along with the trained models and our codebase.
MedRAX: Medical Reasoning Agent for Chest X-ray
Feb 04, 2025



Chest X-rays (CXRs) play an integral role in driving critical decisions in disease management and patient care. While recent innovations have led to specialized models for various CXR interpretation tasks, these solutions often operate in isolation, limiting their practical utility in clinical practice. We present MedRAX, the first versatile AI agent that seamlessly integrates state-of-the-art CXR analysis tools and multimodal large language models into a unified framework. MedRAX dynamically leverages these models to address complex medical queries without requiring additional training. To rigorously evaluate its capabilities, we introduce ChestAgentBench, a comprehensive benchmark containing 2,500 complex medical queries across 7 diverse categories. Our experiments demonstrate that MedRAX achieves state-of-the-art performance compared to both open-source and proprietary models, representing a significant step toward the practical deployment of automated CXR interpretation systems. Data and code have been publicly available at https://github.com/bowang-lab/MedRAX
EHRMamba: Towards Generalizable and Scalable Foundation Models for Electronic Health Records
May 23, 2024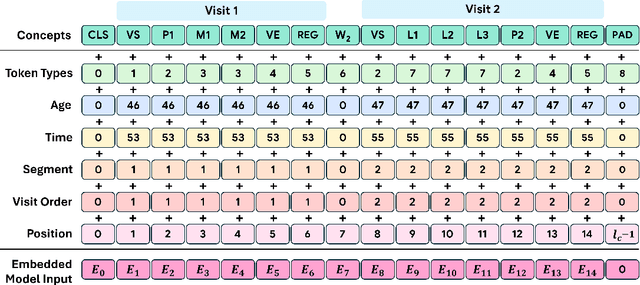
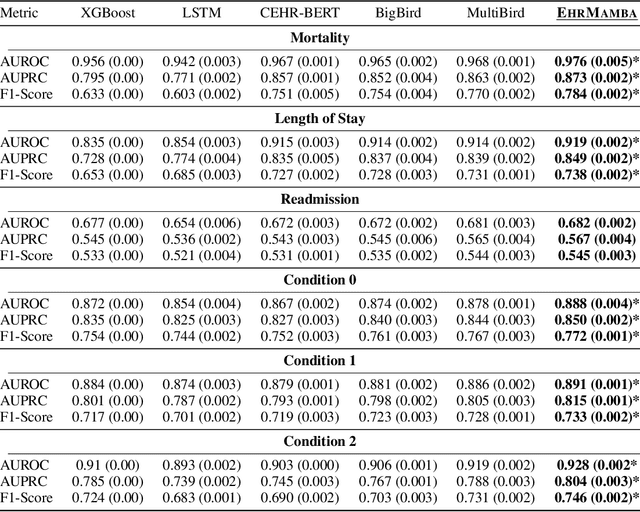
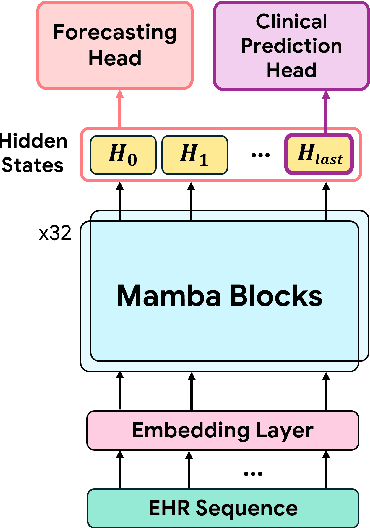
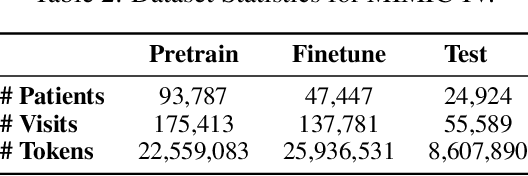
Transformers have significantly advanced the modeling of Electronic Health Records (EHR), yet their deployment in real-world healthcare is limited by several key challenges. Firstly, the quadratic computational cost and insufficient context length of these models pose significant obstacles for hospitals in processing the extensive medical histories typical in EHR data. Additionally, existing models employ separate finetuning for each clinical task, complicating maintenance in healthcare environments. Moreover, these models focus exclusively on either clinical prediction or EHR forecasting, lacking the flexibility to perform well across both. To overcome these limitations, we introduce EHRMamba, a robust foundation model built on the Mamba architecture. EHRMamba can process sequences up to four times longer than previous models due to its linear computational cost. We also introduce a novel approach to Multitask Prompted Finetuning (MTF) for EHR data, which enables EHRMamba to simultaneously learn multiple clinical tasks in a single finetuning phase, significantly enhancing deployment and cross-task generalization. Furthermore, our model leverages the HL7 FHIR data standard to simplify integration into existing hospital systems. Alongside EHRMamba, we open-source Odyssey, a toolkit designed to support the development and deployment of EHR foundation models, with an emphasis on data standardization and interpretability. Our evaluations on the MIMIC-IV dataset demonstrate that EHRMamba advances state-of-the-art performance across 6 major clinical tasks and excels in EHR forecasting, marking a significant leap forward in the field.